
Temat dzisiejszego artykułu zaczął kształtować się, gdy pierwszy raz poznałem (i wypróbowałem) możliwości dojrzałych narzędzi działających w modelu „programowania bez programowania”, czyli tzw. no-code. Założona teza brzmiała – serwisy te są na tyle dojrzałe i dają tyle swobody, że można przy ich użyciu przygotować interaktywne witryny nie umiejąc kodować. Potem przebyłem długą podróż, starając się ową tezę udowodnić. Poległem.
Środowiska do tworzenia projektów no-code są fajne, nawet bardzo fajne. Problem polega na tym, że obiecują więcej, niż są w stanie dostarczyć. Prosta automatyzacja – super. Innowacyjna baza danych współużywana przez kilka osób o różnych uprawnieniach – bez problemu. Prosta logika złożona z kilku decyzji i akcji? Tu pojawiają się schody.
Etap zauroczenia
W moim przypadku zaczęło się od szczerego zauroczenia. Spójrzmy na prosty automacik wyklikany w serwisie Integromat, którym pochwaliłem się tutaj:
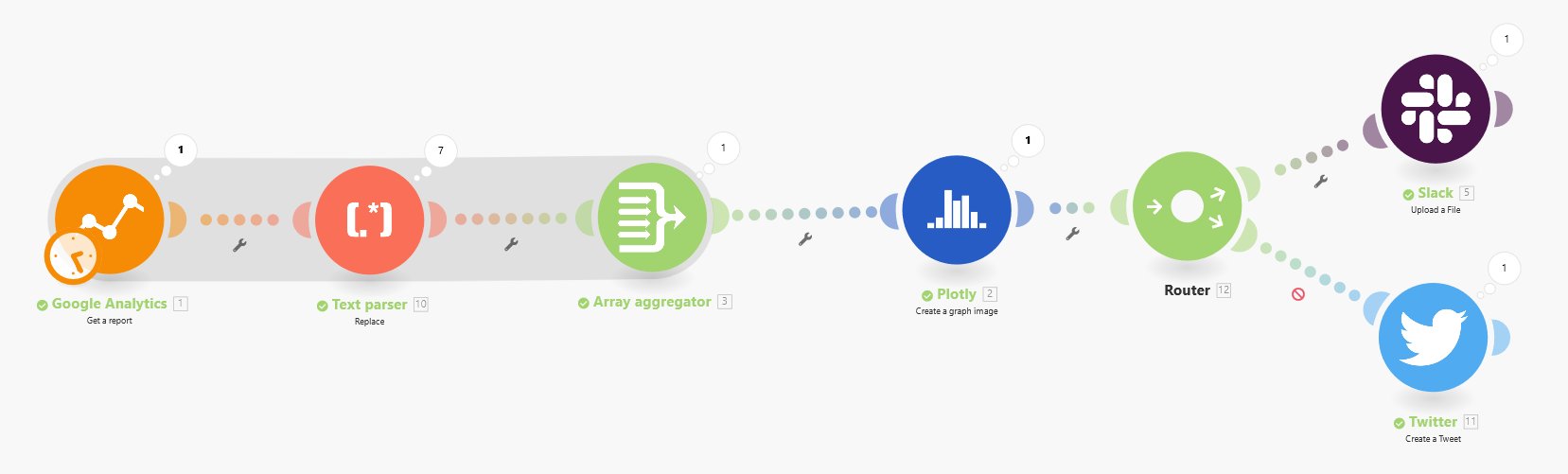
Na obrazku widzimy automat, który przeprowadza kolejno (od lewej do prawej) następujące operacje:
- pobranie danych o oglądalności witryny z Google Analytics
- wyciągnięcie podzbioru numerków opisujących ostatnich kilka dni
- agregacja danych liczbowych do tabeli
- wizualizacja danych z tej tabeli na wykresie
- wysłanie obrazka z wykresem na Twittera oraz Slacka
Wynikowe twitnięcie dokonane przez automat wyglądało tak:
Wszystko wyklikane w kreatorze wizualnym, pozwalającym na względnie wygodne testowanie i odpluskwianie. Wrzucamy na ekran pastylkę symbolizującą daną integrację, wstawiamy klucz API, rzeczy zaczynają działać praktycznie od razu. W porównaniu do rzeźni, jaką jest ręczna integracja czegokolwiek z Google Analytics – niebo a ziemia.
Na blogu Integromatu opisano obszerny zestaw gotowców. Składa się on z 50 różnych szablonów, które można sklonować jednym kliknięciem.
Podczas pierwszej lektury nie dostrzegłem, że znakomita większość z nich składa się z raptem dwóch lub trzech kroków – np. przesłanie maili z Gmaila na Slacka, backup fotek z Google Photo na Dropboxa albo automatyczne twitnięcie postów z Facebooka. Jest to fajna i wygodna automatyka, ale… „dorosłe” programy komputerowe to jednak nieco więcej, niż reguły typu „akcja-reakcja”.
Etap otrzeźwienia
Narzędzia typu „no-code” zawsze wystawiają publiczne API, więc z definicji gotowe są do wzajemnej integracji. Orędownicy tego modelu często prezentują rozwiązania oparte o kilka uzupełniających się usług a popularnym przykładem innowacyjności w tym obszarze jest baza danych AirTable.

Polecam wszystkim samodzielne przeklikanie Airtable, to dość unikalne skrzyżowanie Excela z relacyjną bazą danych. Czerpie najlepsze z obu światów, np. bardzo wygodną obsługę danych różnych typów (predefiniowane kontrolki ekranowe), grupowanie sekcji czy prezentację relacji jeden-do-wielu i wiele-do-jednego. Kilka dobrych pomysłów nieobciążonych naleciałościami historycznymi czyni Airtable czymś nowym, świeżym i atrakcyjnym.

Co z tego jednak, skoro model rozliczeń jest tak dziwny. Płacąc 10 USD miesięcznie użytkownik może utworzyć dowolnie wiele baz danych, ale z limitem do… 5000 rekordów w każdej z nich. To wyklucza AirTable z bardzo wielu zastosowań, m.in. takich, gdzie wymagane jest logowanie zmian lub zdarzeń. Za 20 USD miesięcznie limit rośnie do 50 tysięcy rekordów. Aby jakoś usytuować tę cenę w relacji do konkurencji – konto Microsoft 365 Business Basic kosztuje 5 USD za osobę miesięcznie, też zawiera API do integracji z usługami zewnętrznymi a webowy Excel pomieści milion wierszy w każdym arkuszu.
Owo spostrzeżenie wywołało refleksję: to narzędzie jest zwyczajnie drogie. Prawdziwy problem leży jednak gdzie indziej. Wyklikałem sobie udany automacik integrujący kilka serwisów, m.in. AirTable, Integromat i coś-tam-jeszcze. Wymagał wysiłku, koniec końców zadziałał. Odruch programisty? Zapiszmy wszystko w repozytorium kodu, aby zawsze móc powrócić do poprawnej konfiguracji.
No i tu robi się problem, a raczej cała rodzina problemów. Czasem – choć nie zawsze – pojedyncze narzędzie no-code pozwala na „oznaczanie” albo „opublikowanie” stanu bieżącego pod jakąś nazwą. Jeśli jednak integrujesz kilka różnych narzędzi, nie uda ci się synchroniczne, spójne otagowanie stanu, do którego będzie dało się wrócić bez efektów ubocznych lub ręcznego przywracania parametryzacji. Nawet w obrębie jednego narzędzia prawie nigdy nie ma możliwości eksportu/importu kompletu ustawień, np. zapisania scenariusza Integromatu do pliku. W najlepszym razie możesz zrobić kopię zasobu i nazwać ją „działająca kopia czegośtam”.
Nawet nie zaczynajmy rozmowy o jednoczesnym utrzymaniu kilku środowisk: rozwojowego, testowego i produkcyjnego. Takie koncepcje nie istnieją. Nie ma możliwości przepinania zestawu kluczy API, nie ma migracji ustawień między środowiskami, przenoszenia przetestowanej funkcji do innego środowiska, porównywania różnic, niemożliwe jest utrzymanie jakichkolwiek dobrych praktyk dotyczących utrzymania oprogramowania. DevOpsi i miłośnicy Terraforma będą gotowi wydłubać sobie oczy, byle tylko nie patrzeć na wdrożenie produkcyjne takiej usługi.
źródło: @tonylewis
Ostatnia kluczowa kwestia – kopie bezpieczeństwa. Biznes każdych rozmiarów nie może obejść się bez backupów, tworzonych automatycznie wg harmonogramu oraz na żądanie w dowolnej chwili. Wrzucenie w Google hasła „Airtable backup” zwraca na pierwszych pozycjach wątki z oficjalnego forum, w których można przeczytać, że NIE ISTNIEJE metoda backupu i późniejszego przywrócenia do Airtable danych oraz struktur, relacji, formuł i załączników. Także strony pomocy Integromatu nie zawierają ani jednego słowa o eksporcie i imporcie danych, ustawień, kluczy, przepływów. Podobnie jest w wielu innych narzędziach no-code.
„No-code” oznacza często „no-backup”, „no-fallback” i „no-revert”.
Etap porzucenia
Wiemy już, że przy braku backupów i zarządzania wersjami wynalazki typu „no-code” nie nadają się do poważnych zastosowań. Może jednak pomogą komuś, kto nie jest programistą a chciałby wyklikać jakiś mechanizm bardziej skomplikowany od „dwukoralikowego” backupu zdjęć?
Postanowiłem spróbować. Wymyśliłem sobie następujący problem – system wysyłający personalizowane maile z linkami dostępowym do jakiegoś zasobu. Założenia:
- żądanie może wysłać klient (podając e-mail) albo admin (podają identyfikator klienta)
- jeśli klient zostanie znaleziony w bazie danych, sprawdzamy datę ostatniej wysyłki maila
- jeśli ostatnia wysyłka miała miejsce godzinę temu lub wcześniej, wysyłamy wiadomość
- jeśli wysyłka się udała, odnotowujemy sukces
W każdym kroku niepowodzenie oznacza przejście do kroku, w którym alarmujemy operatora o błędzie i kończymy pracę. Diagram przepływu będzie wyglądał następująco:
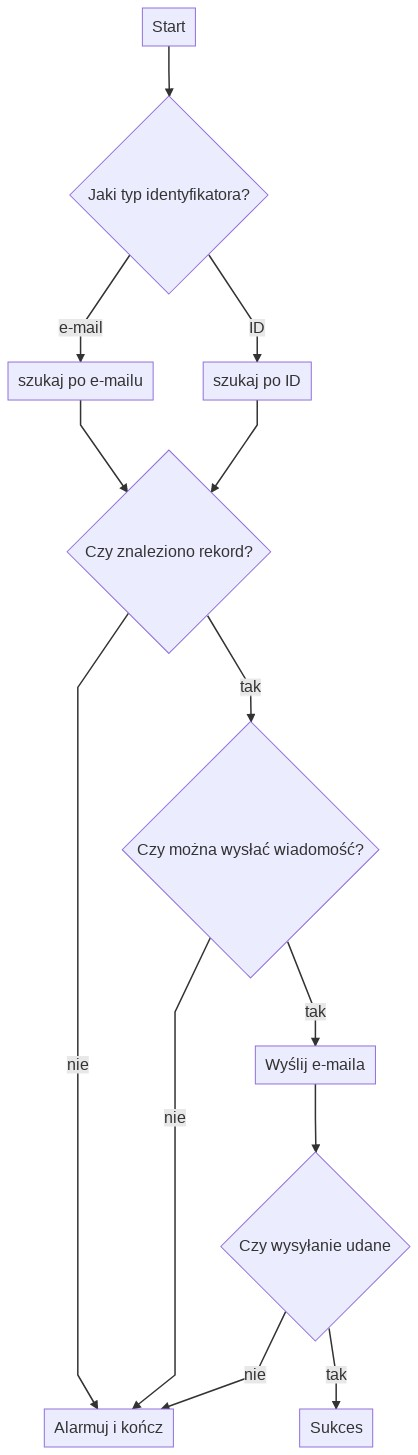
Łatwo spostrzec, że przy czterech rozgałęzieniach mamy osiem możliwych ścieżek, z których sześć kończy się alarmem dotyczącym błędu.
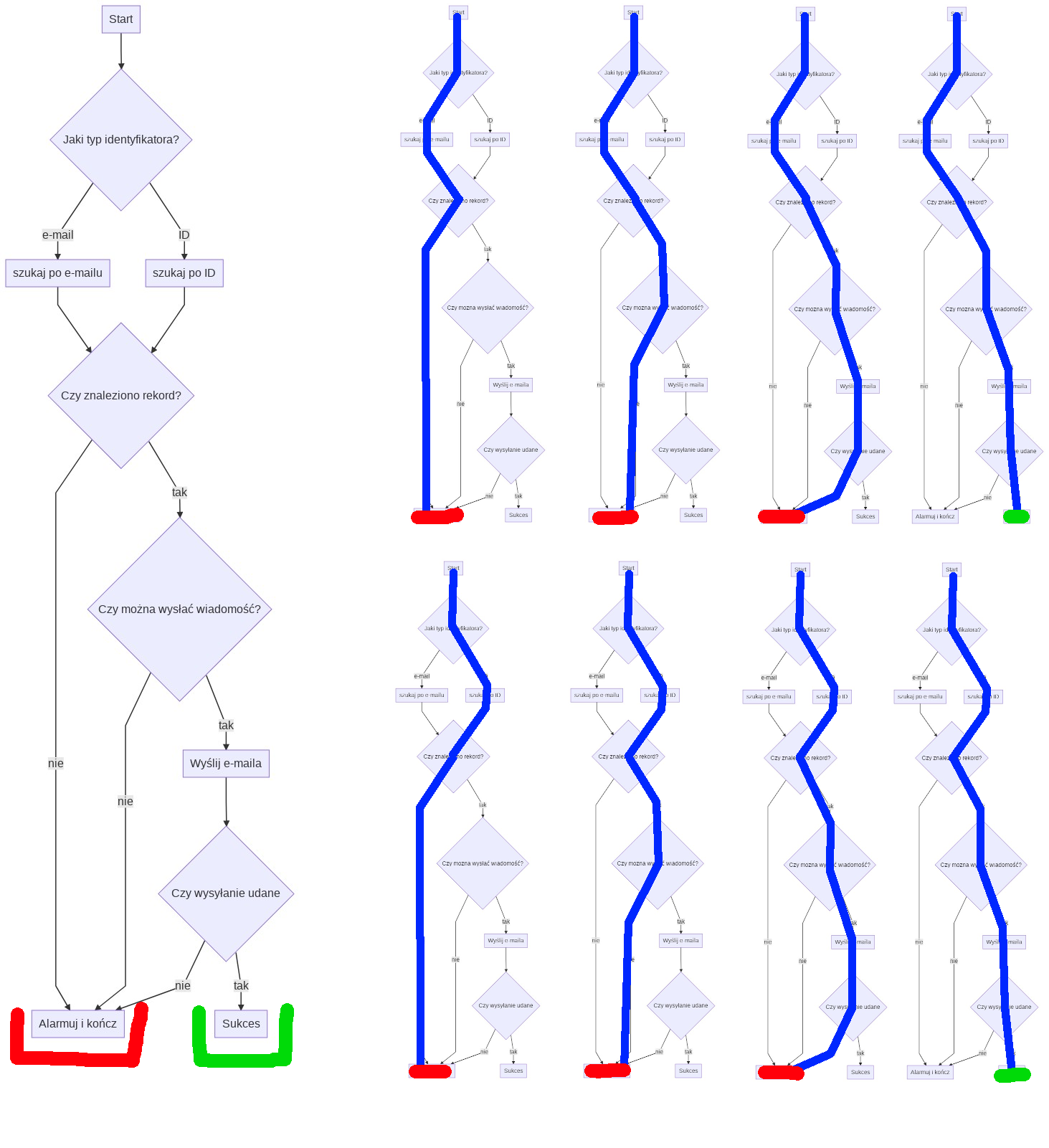
Gdybyśmy teraz chcieli wyklikać w Integromacie schemat, gdzie błędne ścieżki zbiegają się w jednym węźle raportującym problem, napotkamy następujący bloker:
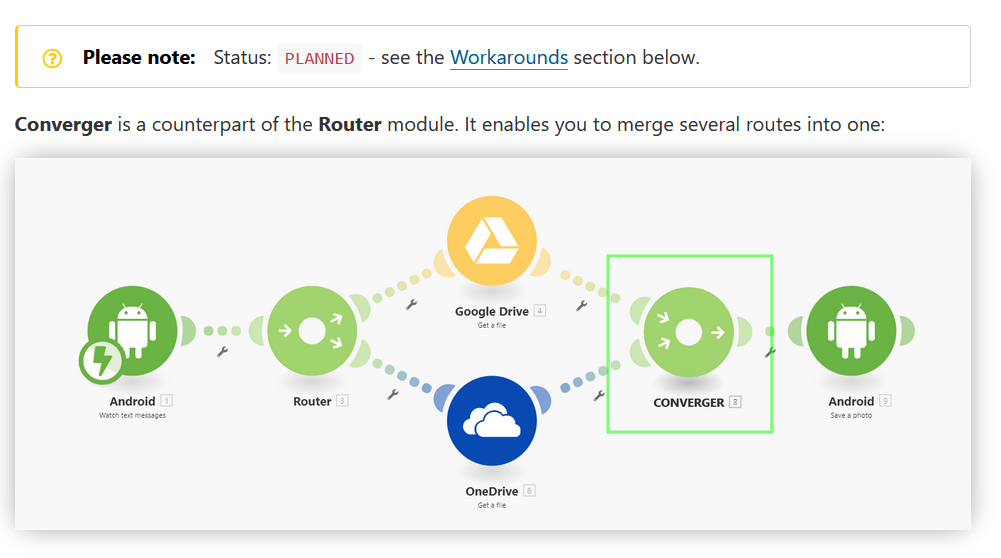
Klocek pozwalający na połączenie różnych ścieżek wykonania jest w Integromacie elementem… planowanym. Jeśli wierzyć serwisowi Crunchbase, Integromat jest na rynku od roku 2012. Skoro funkcja łączenia ścieżek wykonania jest w przygotowaniu od 2018 roku, to coś jest mocno nie tak z architekturą Integromata (lub z wyczuciem potrzeb użytkowników).
Tak czy owak jesteśmy skazani albo na ułomne obejście sugerowane przez autorów, albo na duplikowanie całych gałęzi diagramu, wskutek czego będzie on wyglądał tak:

Łatwo spostrzec, że węzeł „alarm w przypadku błędu” wystąpi tu sześciokrotnie. Gdybyśmy zdecydowali się na utrzymywanie projektu w takiej postaci, jest on praktycznie skazany na przeoczenia podczas przyszłych zmian i poprawek. Efektem będą trudne do wykrycia niespójności. Nawet dość podstawowe funkcje edycyjne (jak „znajdź-i-zamień”) dostępne są nie w interfejsie Integromatu, lecz w pluginie do przeglądarki Chrome.

źródło: @integromat
Jeśli nie Integromat to co? Wytrwale szukałem lepszego narzędzia no-code. Rozgałęzienia w obsłudze zdarzeń są w Zapier są jeszcze bardziej prymitywne i ograniczone. W IFTTT nie ma ich wcale, tak samo jak Bubble. Power Automate dostępny jest tylko dla korporacji. Sprawdziłem jeszcze kilka mniej popularnych opcji i…
Poddałem się.
Jeśli obserwujecie mnie na Twitterze, wiecie to od lutego:
Napisałem wówczas: „Szczerość nie radość, ale napiszę jak jest. Od wielu miesięcy starałem się pokazać Wam na prostym przykładzie prostej witryny z prostą automatyzacją, że współczesne webowe narzędzia typu NoCode pozwalają napisać program bez programowania. I wiecie co? Nie pozwalają. Sorry, nadal do programowania potrzebujecie programisty, NoCode przestaje działać tuż po tym, gdy wyjdziemy poza granice funkcji przewidziane przez autorów danego rozwiązania. A naprawdę bardzo chciałem, żeby się udało.
Artykuł powstanie tak czy owak, będą propsy dla @integromat oraz @bubble, będą słowa uznania dla @airtable, ale ze wskazaniem kluczowych ograniczeń. Całkiem szczerze sądzę, że użytkownicy Excela 365 mogą pokochać Airtable a ten, kto od lat co rano zaczyna dzień pracy od rutynowego kopiowania danych skądś dokądś, może odzyskać radość życia dzięki Integromatowi. Niestety – to nadal za mało. Może kiedyś.”
Podsumowanie
Szczerze zachęcam do poklikania w Integromat i Airtable. Zobaczycie, jak kształtują się świeże paradygmaty oraz innowacyjne ścieżki User Experience. Przy odrobinie szczęścia odkryjecie prostą automatykę, której – nie wiedząc o tym – od zawsze potrzebowaliście. Trzeba tylko pamiętać, że już na średnim poziomie komplikacji minusy podejścia no-code przesłonią prawie wszystkie plusy a brak możliwości sporządzenia kopii bezpieczeństwa nie pozwoli użytkownikowi na spokojny sen.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

18 odpowiedzi na “No code, no woman, no cry”
Wada no-code: twoje dane są w chmurze, często dane wrażliwe. Czy chcesz, żeby odczyty z twojego licznika energii elektrycznej trafiały do chmury jakiegoś operatora? Twój rejestr wydatków i plan finansowy? Ufasz politykom prywatności? Czy operator usunie wszystkie dane realizując twoje prawo bycia zapomnianym? Również z backupów?
Tak ufam im, przynajmniej czesci z nich – jak chocby hyperskalerom jak MS, Amazon czy Google. mają za dużo do stracenia.
A jak Ci zablokują dostęp do danych w imię np. aktualnie obowiązującej poprawności politycznej – tak jak zrobili to urzędującemu prezydentowi USA – D. Trumpowi?
Albo przypadek Andrew Spinks’a, twórcy gry Terraria, który w lutym 2021 stracił dostęp do gmaila i nie był w stanie go odzyskać.
Albo przypadek serwisu Parler, który w ciągu kilku dni został dosłownie wymieciony z sieci przez połączone działania Amazon, Google i Apple.
Albo przypadki tysięcy zwykłych użytkowników, którzy potracili kanały na YouTube, Facebook itp.
Ja zgadzam się z Gertrude Nelson, ale rzecz jasna inni mogą mieć odwrotny pogląd na tę kwestię, do czego mają całkowite prawo, i jest ich chyba nawet zdecydowana większość…
Zaraz, ale to trochę przesuwanie bramki. Najpierw pytasz o to, czy operatorzy chmury nie będą wykorzystywać naszych danych wrażliwych i czy usuną dane jak się sam usuniemy z chmury, a potem nagle zmieniasz pytanie na to, czy operatorzy chmury nie usuną nas z chmury.
To są dwa różne problemy, ten drugi przecież od zawsze istniał: kiedy ktoś łamał prawo na serwisach społecznościowych to mógł stracić konto, gdyby Trump nie był Trumpem to by to konto stracił dużo, dużo wcześniej za nawoływanie do przemocy, które nie jest chronione druga poprawką.
Faktycznie to są po prostu 3 podstawowe atrybuty bezpieczeństwa – poufność, integralność i dostępność.
@ziemek pisanie „Tak ufam im […] mają za dużo do stracenia.” jest wyjątkowo naiwne. Otóż Microsoft, Alphabet (właściciel Google) czy Amazon nie mają nic do stracenia. To koncerny posiadające roczny budżet większy niż prawdopodobnie większość państw świata.
Dochody korporacji w roku 2020:
Alphabet: 185 mld USD
Microsoft: 143 mld USD
Amazon: 386 mld USD
Dla porównania budżet Polski w roku 2020 zakładał dochód państwa na poziomie ok. 115 mld USD…
Do tego dochodzi nam kwestia monopolizacji rynku przez Alphabet, Microsoft i Amazon, która powoduje, że większość ludzi nawet nie ma za bardzo wyboru (lub myśli, że nie ma), żeby zrezygnować z usług tych korporacji.
Naprawdę myślisz, że zaszkodzi im jakkolwiek to, że zignorują Twój wniosek o usunięcie danych albo przekażą Twoje amerykańskim służbom lub zwyczajnie sprzedadzą je innym korporacjom? Pozwiesz ich? Poskarżysz się w rodzinie, znajomym i w Internecie i nagle masowy bojkot konsumencki zmiecie ich z rynku?
W USA nie obowiązuje RODO, a amerykański model ochrony danych osobowych i prywatności opiera się głównie na odpowiedzialności cywilnoprawnej administratorów danych. Powodzenia, drogi Ziemku, w pozywaniu którejkolwiek z tych spółek przed amerykańskimi sądami za naruszenie ochrony Twoich danych…
Nikogo nie pozwie, bo klikając „ACCEPT” zgodził się po pierwsze na arbitraż a po drugie na ograniczenie roszczeń do kwoty $100 albo mniej 😉
Zawsze dziwiło mnie uzależnianie się od zewnętrznej firmy. Zwłaszcza amerykańskie, które mogą robić, co chcą, bo w Polsce nie mamy nad nimi żadnej kontroli.
A obadales powstające google tablet? Wymaga amerykańskiego IP.
Google tables
Z drugiej strony, jak duży nakład pracy jest potrzebny żeby rozwiązać ten problem w kodzie? Czy każda integrowana usługa to konieczność importu pierdyliona krzywych bibliotek 3rdparty czy da się to zrobić prościej as a code?
Nie wiem, czym dokładnie jest „ten problem”, ale w podejściu „as a code” masz stały kurs wymiany: cała praca, którą zaoszczędzisz na początku cudzym kodem, wróci w późniejszym etapie, gdy ów cudzy kod trzeba będzie usunąć (bo nierozwijany, bo poszedł w złą stronę, bo mocno podrożał, konkurencja wykupiła i zabiła itd.) albo zacząć utrzymywać samodzielnie (bo porzucony a go lubimy)
Chodziło o rozwiązanie dokładnie tego problemu z Twojego przykładu, ale w kodzie, abstrahując od j. programowania. Upraszczając płaci się w tym Integromacie, IFTTT czy Zapierze za to żeby sobie proces 1. ławo i elastycznie wyklikać i za to, że 2. ktoś pilnuje żeby integracja z usługami/klockami cały czas działała, nawet jeśli API tych usług się zmieni w czasie.
Przydałoby się coś w kodzie co w miarę możliwości zachowuje cechę nr 2.
Przeszedłem podobną drogę podczas zabawy z no-code z zapierem. W praktyce nawet proste automatyzacje (np. zapisanie na dysku google załącznika z maila spełniającego kryteria) wymagają wielu kroków, a wersja darmowa pozwala na jednokrokowe akcje (jeden trigger + jedna akcja). Najniższa opcja płatna to 20$/mc.
Przeszedłem podobną drogę podczas zabawy z no-code z zapierem. W praktyce nawet proste automatyzacje (np. zapisanie na dysku google załącznika z maila spełniającego kryteria) wymagają wielu kroków, a wersja darmowa pozwala na jednokrokowe akcje (jeden trigger + jedna akcja). Najniższa opcja płatna to 20$/mc.
Brak eksportu/importu i wersjonowania to kolejny minus. Szukając alternatyw trafiłem na https://n8n.io/ – open source, self-hosted, import/export workflow i credentiali, może warto sprawdzić.
Bardzo fajny wpis 🙂 Sam testowałem kilka opcji no-code open source, m.in. NocoDB, Baserow czy Grist. Podobne wnioski odnośnie odwzorowania czegokolwiek poza najprostszą logiką czy relacją. Do tego przeszkadza mi brak możliwości konfiguracji czy uproszczenia interfejsu, kiedy przechodnimi z projektowania do korzystania.
wspomniany n8m rzeczywiście warty sprawdzenia
A jaka jest Wasza opinia o bardziej złożonych narzędziach no-code jak np. Bubble, Xano?
W zasadzie taka sama. Jeśli nie umiesz programować i Bubble pozwala ci zrealizować jakiś prototyp – korzystaj! Dobrych praktyk i tak nie znasz, więc ich nie zastosujesz. A gdy biznes ci zadziała, to sam poczujesz ograniczenia i zamówisz rozwiązanie szyte na miarę.