
W jednym z poprzednich tekstów pokazałem, że arkusz kalkulacyjny pozwala przygotować całkiem złożone obliczenia i wizualizacje. Niestety, szybko zderzamy się z głównym problemem arkuszy – dane są tam ściśle powiązane z operacjami przetwarzania a niewielkie zmiany w pośrednim kroku obliczeń mogą pociągać konieczność przeorganizowanie całego arkusza.
Jeśli makra i skomplikowane formuły masz w małym palcu, może czas na kolejny krok? W tym tekście poznasz środowisko RStudio Cloud i zobaczysz, w jaki sposób dane tabelaryczne można obrabiać w języku skryptowym. Nie będzie to tutorial prowadzący małymi kroczkami, skaczemy w głąb języka R, kolekcji pakietów tidyverse oraz biblioteki ggplot. Wykresy przygotujemy przy użyciu gramatyki opisującej mapowania zmiennych, charakterystykę układu współrzędnych oraz definicje kształtów i kolorów.
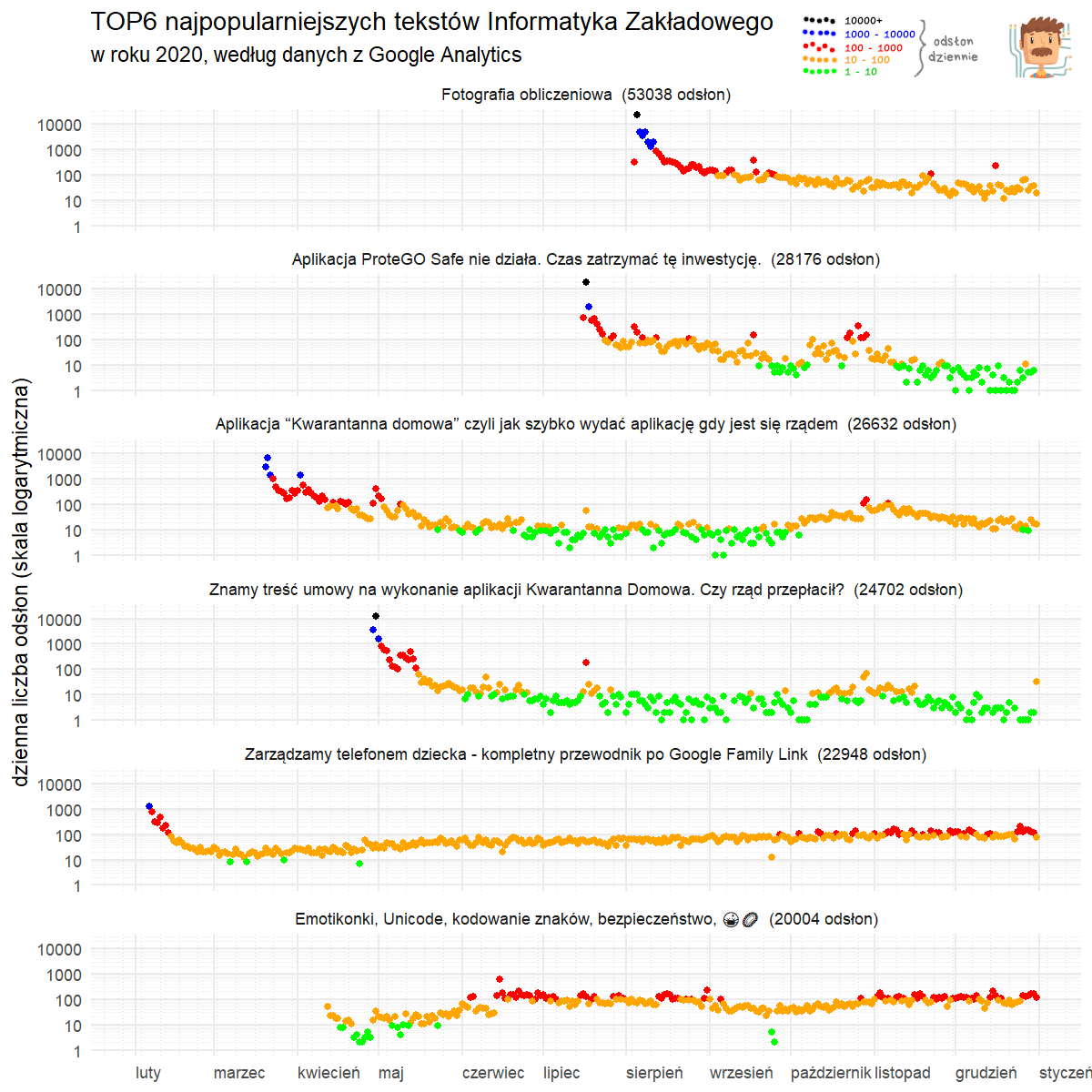
Naszym celem będzie przygotowanie następującego obrazka. Zawiera on sześć najlepiej klikających się artykułów z minionego roku umieszczonych na wspólnej osi czasu. Z małych wykresów można odczytać, kiedy artykuł został opublikowany i jak wygląda dynamika zmian czytelnictwa.
Dane źródłowe
Dane do umieszczenia na wykresie będą pochodziły z serwisu Google Analytics. W dzisiejszych czasach, gdy przeglądarki domyślnie blokują funkcje śledzenia i „obce” ciasteczka, prezentuje on statystyki niedoszacowane dwu- a nawet i pięciokrotnie, ale to na razie musi nam wystarczyć.
Otwieramy serwis Analytics, przechodzimy do ekranu Zachowanie → Zawartość witryny → Wszystkie strony, przestawiamy zakres dat na cały rok 2020, Wymiar podstawowy na „Tytuł strony” a Wymiar dodatkowy na „Datę”. Panel wygląda tak:
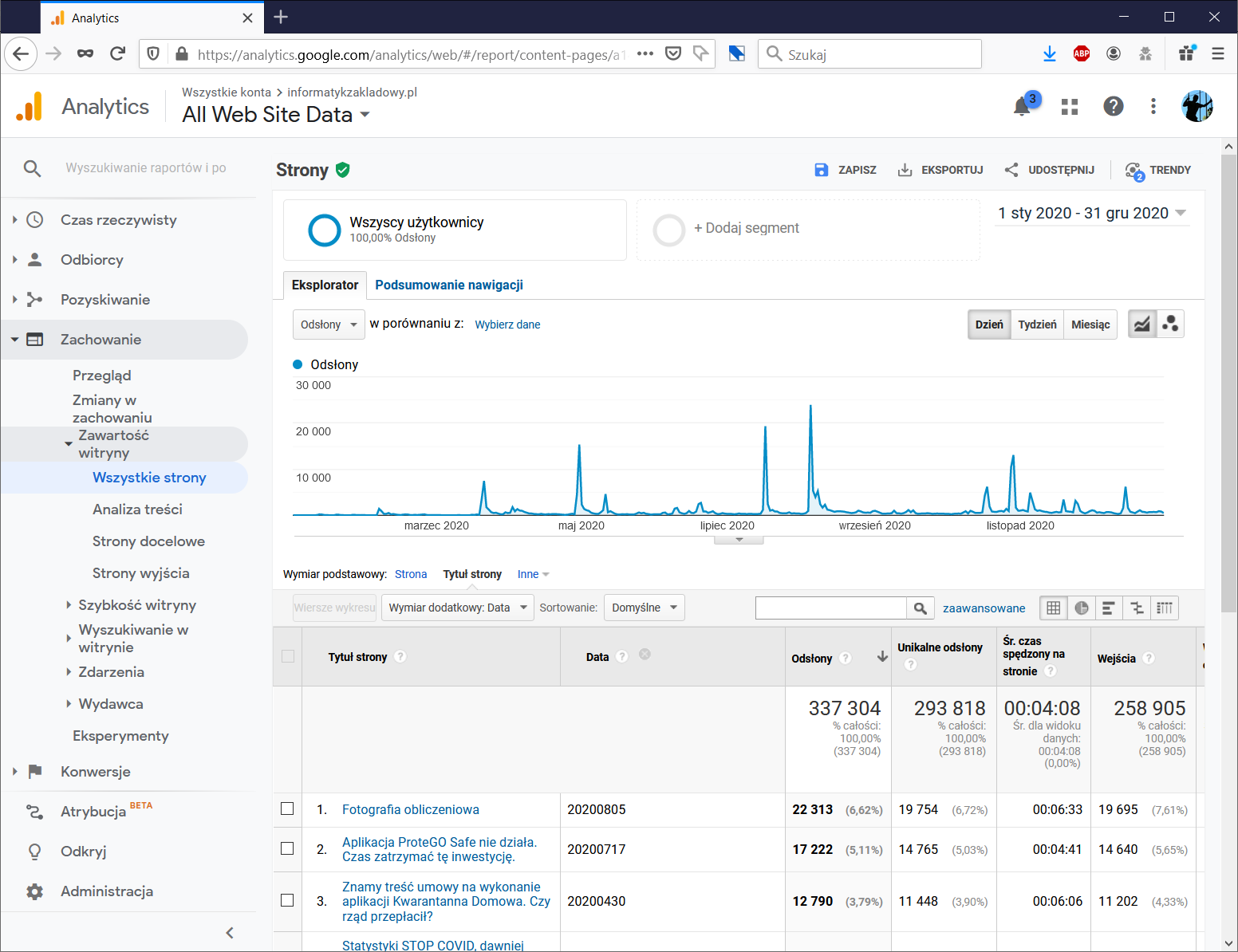
Na dole strony widzimy, że roczne statystyki to ponad 11 tysięcy wierszy opisujących oglądalność „strono-dni”, jednak na raz możemy zobaczyć co najwyżej 5000 pozycji.
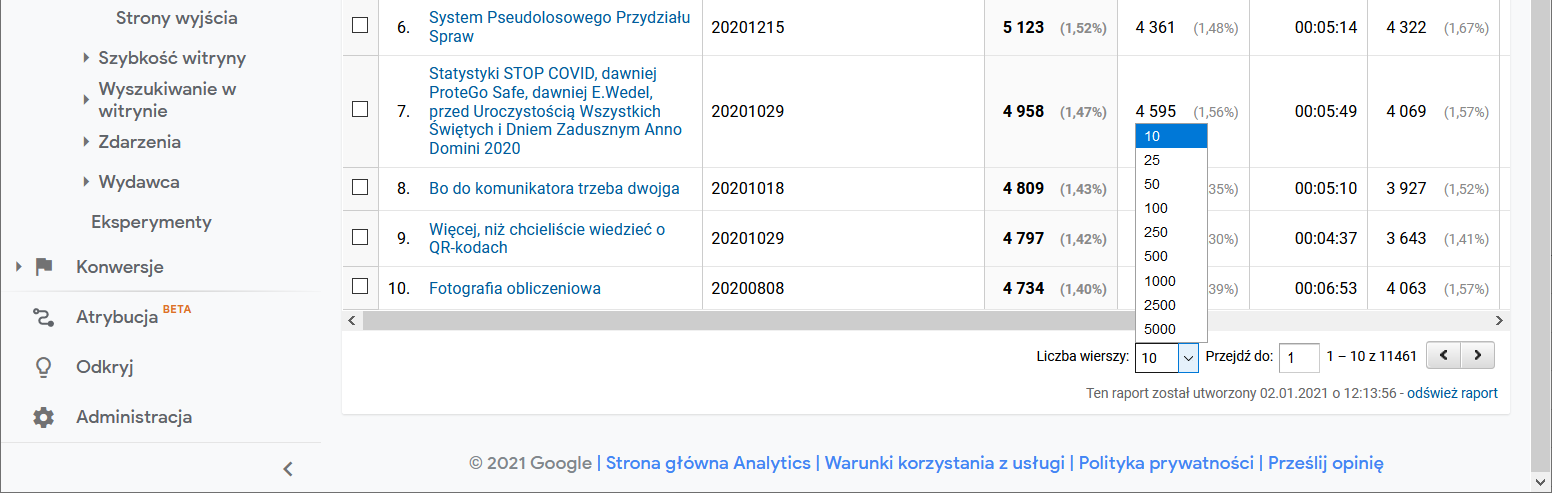
Nie ma prostego ani szybkiego sposobu na wyciągnięcie kompletu danych, więc trzeba przestawić kontrolkę na wyświetlanie 5000 wierszy i trzykrotnie użyć funkcji Eksportuj → CSV w nagłówku strony, osobno dla każdego przedziału danych. Otrzymamy trzy pliki tekstowe, które trzeba troszkę podrzeźbić ręcznie.
Do operacji na plikach tekstowych polecam edytor Notepad++. Bierzemy pierwszy plik i usuwamy z niego sześć linii nagłówka:
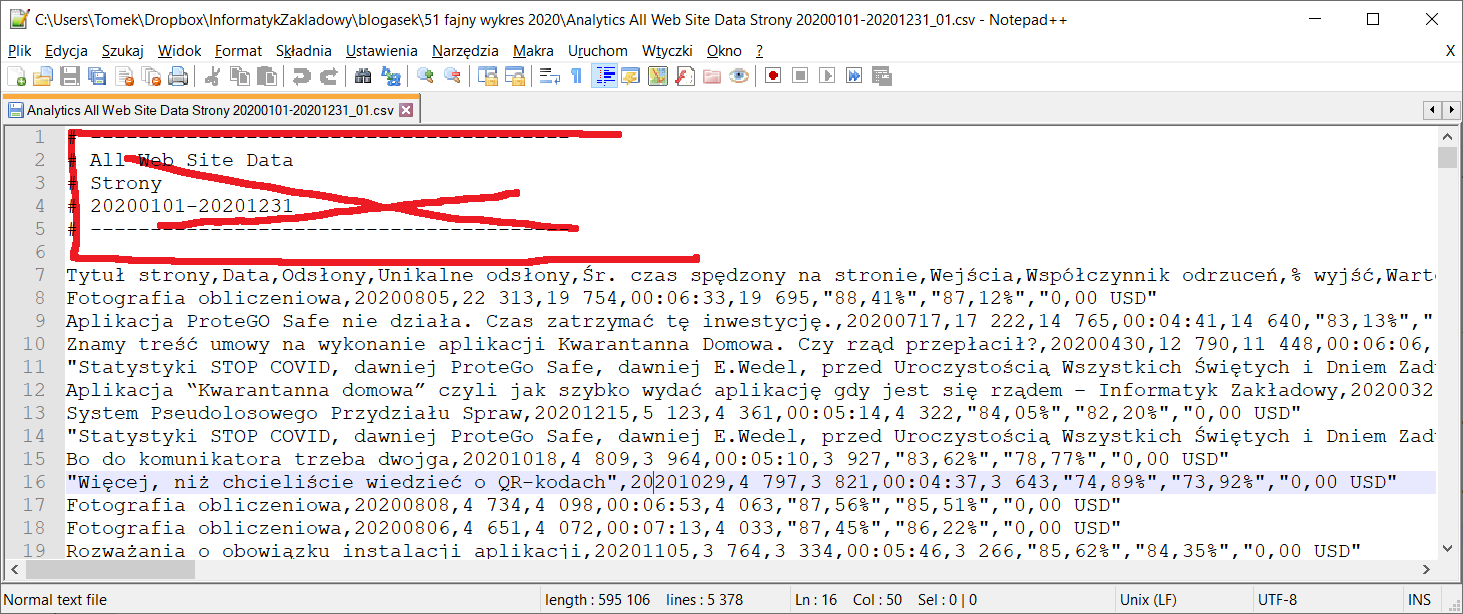
Potem kasujemy kilkaset linii z końca pliku, odcinając wszystko co nie zawiera statystyk oglądalności:
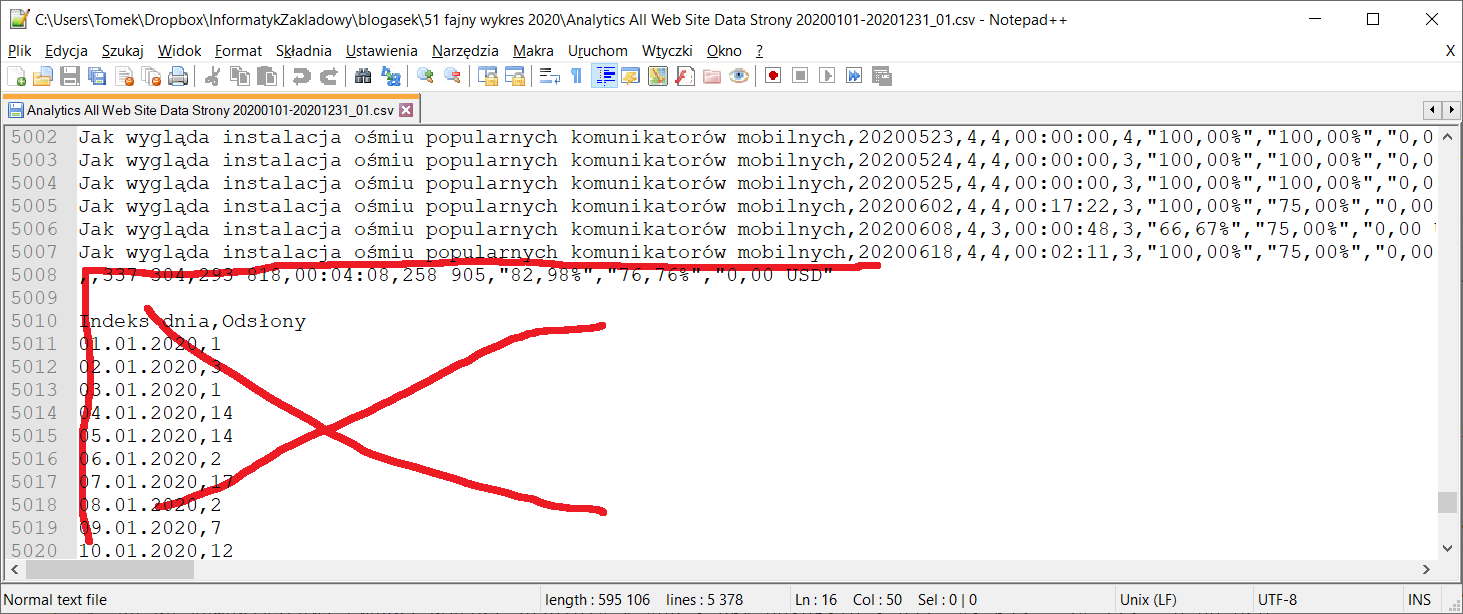
Podobne operacje należy przeprowadzić na drugim i trzecim pliku, tym razem usuwając także wiersz nagłówka (siódmy). Na koniec zawartość drugiego i trzeciego pliku wklejamy na koniec pierwszego pliku, aby mieć komplet danych w jednym zbiorze CSV.
TUTAJ znajdziesz plik tekstowy data.csv z pełnymi statystykami bloga z 2020 roku. Będziemy używać go w dalszej części tekstu.
RStudio Cloud
Załóż darmowe konto w serwisie RStudio Cloud, utwórz workspace o dowolnej nazwie, następnie w prawej-dolnej zakładce Files użyj funkcji Upload, by wysłać pobrany przed chwilą plik data.csv. Kliknij go, RStudio powinno wyglądać jakoś tak:

Teraz wybierz opcję File → New file → R Script aby utworzyć nowy plik skryptowy. Wszystkie teksty w czarnych ramkach poniżej będą stanowić kolejne fragmenty naszego skryptu obrabiającego dane. Nie musisz rozumieć składni poleceń, język R jest dość… charakterystyczny.
Skrypt uruchomisz poleceniem „Run” w pasku narzędzi okienka pliku. Jeśli podświetlisz fragment pliku, uruchomisz tylko zaznaczony kod, w przeciwnym razie wykonany zostanie cały plik.
Zaczynajmy od deklaracji użycia potrzebnych bibliotek, przy pierwszym użyciu zobaczysz w RStudio żółty pasek proponujący ich instalację. Zajmie to minutę lub dwie.
Przestawiamy formatowanie dat na język polski.
Wczytujemy dane z pliku do zmiennej articles. Zmienną tę zobaczymy w prawym górnym panelu, możesz kliknąć niebieskie kółko obok nazwy aby zobaczyć nazwy wczytanych kolumn.
Wyrzucamy niepotrzebne kolumny, poprawiamy typy drugiej i trzeciej kolumny.
Gdy klikniemy nazwę zmiennej articles, otworzy się okienko z podglądem jej zawartości. Widzimy, że zmienna ta przechowuje tzw. ramkę danych czyli dane tabelaryczne, zorganizowane w wiersze i kolumny.
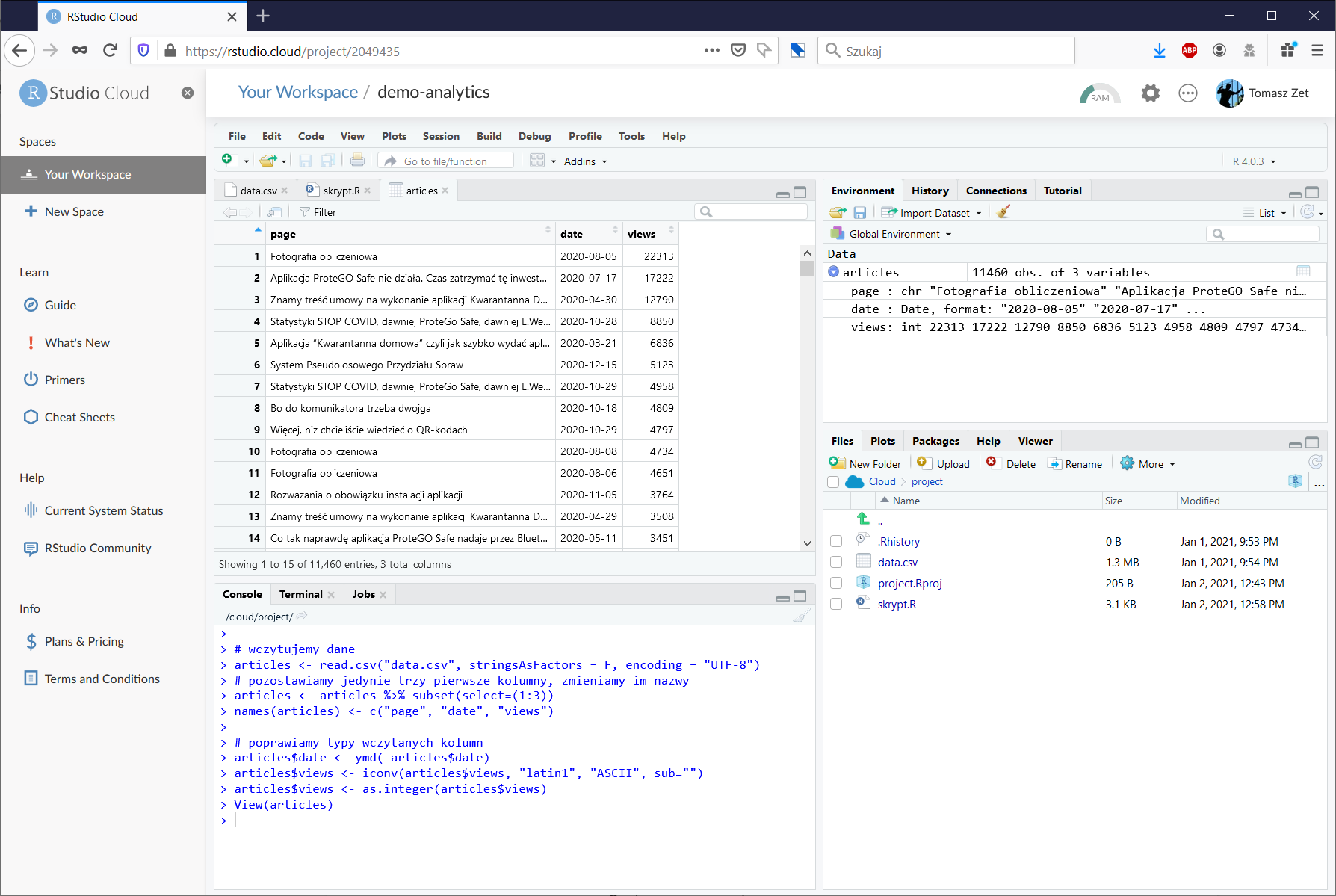
Czyścimy dane – nie chcemy patrzeć na odsłony strony głównej, ponadto w ciągu roku zmienił się sposób prezentacji tytułu strony.
Po czyszczeniu mogło się zdarzyć, że ten sam artykuł w tym samym dniu będzie opisany dwoma wierszami – sumujemy je a przy okazji dodajemy kolumnę sumviews zawierającą łączną liczbę obejrzeń danego artykułu.
Tworzymy pierwsze wykresy
Do zobrazowania danych użyjemy wspomnianego już pakietu ggplot, który potrafi czerpać dane bezpośrednio z data frame (danych tabelarycznych). To podejście jest zupełnie inne, niż przypadku narzędzi graficznych – przekształcamy dane na obraz poprzez opisanie pożądanych cech wizualizacji. Znakomity esej napisał o tym Przemysław Biecek, zachęcam do lektury.
W sieci znajdziemy wiele materiałów pomocniczych, np. taką ściągawkę jak na obrazku

Pierwszy przykład będzie bardzo prosty – weźmiemy jeden artykuł (filtrowanie w wierszu 2), przypiszemy datę i oglądalność do osi X i Y (wiersz 3), na końcu użyjemy formy wykresu liniowego (wiersz 4).
Wynikowy obraz wygląda następująco
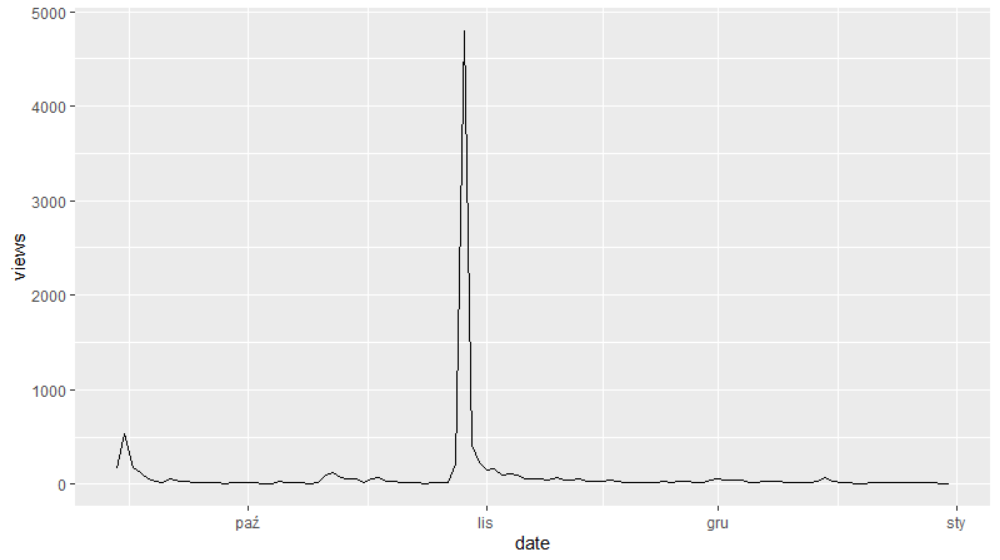
Widzimy, że pik oglądalności z końcówki października (tekst wtedy trafił na pierwszą stronę Wykopu) utrudnia odczytanie pozostałych wartości, możemy więc jedną komendą zmienić skalę Y na logarytmiczną, dodamy do niej samodzielnie określoną siatkę (wiersz 5) a na wykres nałożymy odmienny szablon wizualny (wiersz 6).
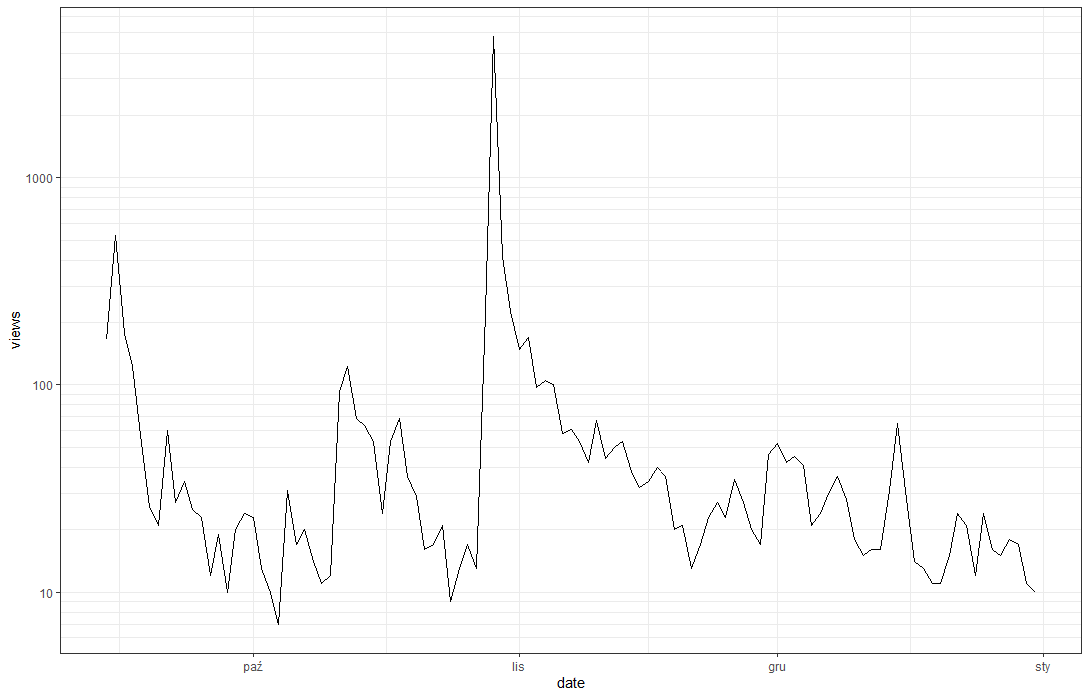
Docelowy obrazek
Na obrazku chcemy umieścić kilka osobnych wykresów kolorowanych według skali logarytmicznej, potrzebujemy więc kilka dodatkowych kolumn i zmiennych
Teraz możemy już sporządzić finalny wykres, wywołanie ggplot wygląda następująco
Finalny obrazek wygląda tak, jak poniższy – jedynie logo serwisu i skala kolorów zostały wstawione ręcznie. Ostatnia komenda zapisała obrazek do pliku, znajdziesz go w RStudio Cloud w prawym dolnym panelu, w zakładce Files.
Kompletny skrypt znajdziesz tutaj.
I to już wszystko.
Albo nie. Pozostała jeszcze jedna porada.
W niniejszym tekście wykonaliśmy środowisko RStudio Cloud, bo próg wejścia jest tam bardzo niski – wystarczy przeglądarka i minuta na założenie konta, można od razu przystąpić do akcji i wszystko działa. W gratisie dostajesz dostęp do środowiska chmurowego przez 15 godzin miesięcznie. Jeśli dobijesz do tego limitu, to po prostu zainstaluj na swoim komputerze język R wraz z darmowym wydaniem programu RStudio.
PS: ten tekst jest mocno specjalistyczny i jako taki nie będzie zbyt popularny. Zostaw komentarz, jeśli chcesz, aby co jakiś czas na blogu pojawiały się bardziej skomplikowane tematy dla bardziej zaawansowanych czytelników. Dzięki!
[dodano 01.02.2021] pierwotna wersja skryptu prezentowanego w artykule zawierała usterkę, z powodu której tekst o Family Linku miał zbyt niską oglądalność. Poprawiono wykres i kod w języku R.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

6 odpowiedzi na “Najpopularniejsze artykuły z roku 2020 na fajnym wykresie i jak go zrobić”
Zostawiam komentarz, aby co jakiś czas na blogu pojawiały się bardziej skomplikowane tematy dla bardziej zaawansowanych czytelników 😉
Tak, chcę, żeby pojawiały się omówienia tematów bardziej zaawansowanych. Przykład: dostęp zdalny do komputera (VNC), jak nie mamy publicznego IP. Zagadnienia dla programistów też pożądane.
Bardzo fajny praktyczny wstęp do R i R Studio. Nie jestem pewien, czy temat jest bardziej zaawansowany, wydaje mi się bardziej niszowy po prostu.
Interesuje mnie pójście w kierunku programowania, a dokładniej właśnie badania danych, ale jakoś nie mogę się przekonać do R, wolę Pythona. Może jakieś artykuły w jego tematyce?
Ja nadal mam nadzieję, że przejdę przez życie nie programując w Pythonie, więc musisz szukać gdzie indziej 🙂
ciekawe