
Niniejszy tekst jest moim wkładem w dyskusję, czy kod źródłowy oprogramowania realizowanego na zlecenie władz powinien wchodzić w zakres informacji publicznej. Otóż: zdecydowanie powinien.
Na przykładzie ministerialnego Systemu Losowego Przydziału Spraw objaśnię prostym językiem pułapki, jakie wiążą się ze ślepą wiarą w poprawność działania systemu komputerowego. Mamy tu bowiem do czynienia z niedostatecznie opisanym algorytmem, niezweryfikowaną implementacją tego algorytmu, wreszcie z wydającym rozporządzenie ministrem, dla którego „generator liczb losowych” jest tym samym co zmienna losowa i którego współpracownicy nigdy nie dotarli na lekcję o rozkładzie prawdopodobieństwa.
Pokażę w jaki sposób możliwe byłoby takie manipulowanie systemem losowania, aby w razie ujawnienia wytłumaczyć je omyłką niekompetentnego programisty. Na końcu zaproponuję metodę losowania, która byłaby w pełni przejrzysta i opierała się na zmiennych o gwarantowanej losowości.
Najpierw o tym, że programowanie jest trudne
Dwa najtrudniejsze problemy informatyki to:
- nazewnictwo zmiennych
- inwalidacja cache’a
- błąd typu off by one
Aby było jasne – to powyżej to dowcip, który rozśmiesza programistów do łez. Nie martw się, jeśli go nie rozumiesz albo cię nie bawi. Każda branża ma swój hermetyczny humor, czytelny jedynie dla ludzi z tej branży.
O czym to ja… a, tak. Programowanie jest trudne. W Wikipedii możmy znaleźć listę najbardziej spektakularnych zdarzeń wynikających z błędów w oprogramowaniu i prawda jest taka, że z biegiem czasu średnia jakość kodu raczej stoi w miejscu. Albo wręcz się obniża, bo co i rusz budujemy nowe warstwy abstrakcji na starych, chybotliwych fundamentach.
Gdy programista przystępuje do pracy, ma do dyspozycji lepszą lub gorszą specyfikację zadania czyli opis tego, co program ma robić (niekiedy także – jak ma to robić). Im lepszy opis, tym mniej niejasności czyli tzw. „przypadków brzegowych”. Pamiętacie artykuł o emotikonktach? Wspomniałem tam o emotikonce „rodzina z dwiema dziewczynkami, jasny kolor skóry”, wyglądającej np. tak:

Jeśli sprawdzimy, ile „miejsca” zajmie „w komputerze” ta emotka, to zależnie od jednostki pomiaru i metody zapisu możemy otrzymać wartości 1, 4, 7, 11, 38, 40, 42 albo 44. Wystarczy, że osoby projektujące dwie części jednego systemu używającego emotikonek nie ustalą bardzo precyzyjnie formatu przenoszenia danych, a już mamy przyczynę potencjalnej awarii. Oczywiście specyfikacja może wynikać z analizy, którą projektanci dostali od analityków, zaś brak specyfikacji powinien być zasygnalizowany przez programistów, ale pośpiech lub brak doświadczenia na którymkolwiek z etapów ma skutki takie a nie inne.
Jeśli chcesz poczytać więcej o całym procesie tworzenia programu, polecam rozdział „Inżynieria oprogramowania” w doskonałym Przewodniku po informatyce.
Obserwacja: nawet, gdy programista wie, co ma zrobić i jak ma działać jego program, to mimo wysokiej staranności i najlepszych chęci nadal będzie miał milion sposobów na popełnienie błędu.
Jak upewnić się, że program robi to co należy?
Mamy tylko dwie metody: przegląd kodu oraz testowanie.
Przegląd kodu (code review) polega na tym, że jedna osoba programuje a gdy skończy, inne osoby pracujące przy tym samym projekcie oglądają wszystkie zmiany w kodzie źródłowym i starają się znaleźć w tych zmianach słabe strony. Bywa to proces zawstydzający i nieprzyjemny, bo nikt nie lubi wytykania błędów, ale usterki wychwycone na tym etapie nie kosztują prawie nic. A taki na przykład błąd w oprogramowaniu rakiety Ariane 5 kosztował 370 milionów dolarów, bo źle działający kawałek oprogramowania rakiety spowodował jej eksplozję.

Testowanie to systematyczne sprawdzanie, czy program zawsze robi to, co należy. Jest żmudne, monotonne i długotrwałe zaś cały proces musi być powtarzany od początku przed wydaniem każdej kolejnej wersji tego programu. Zdarza się bowiem, że poprawa jednego błędu skutkuje wprowadzeniem innego błędu w innym miejscu.
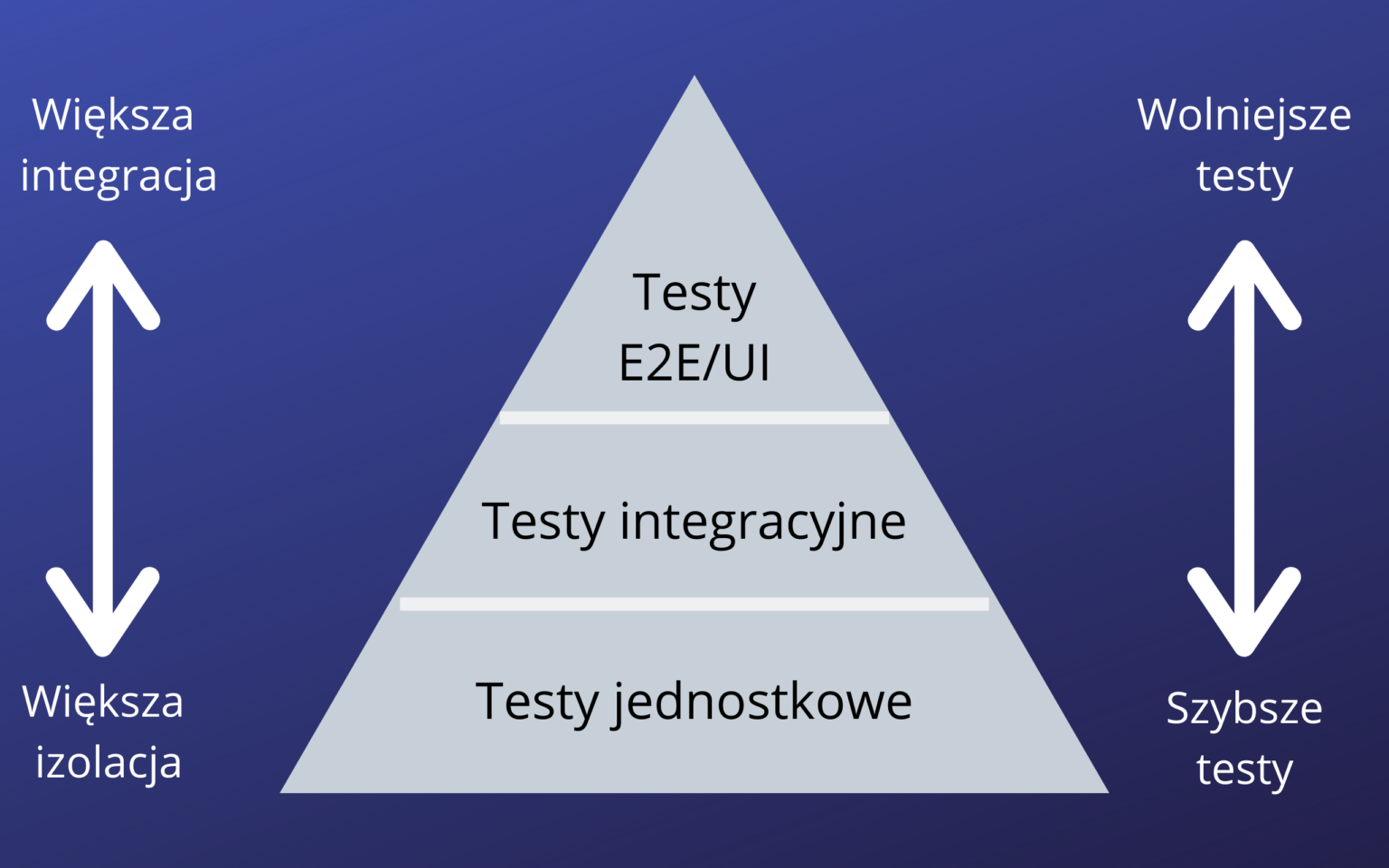
źródło: projectquality.it
W prawidłowo prowadzonych projektach mamy do czynienia z całą hierarchią testów. Każdy kawałek kodu jest opatrzony automatycznymi testami jednostkowymi, sprawdzającymi poprawność pojedynczej operacji (np. zwiększenia stanu konta w banku). Nad nimi mamy testy integracyjne, w których sprawdzamy poprawność współpracy różnych komponentów systemu – tu także preferowane jest podejście automatyczne (przykład: poprawność działania modułu decydującego o przyznaniu kredytu – zależnie od historii rachunku i informacji z BIK) . Na końcu są tzw. testy end-to-end, w których sprawdzamy, czy oprogramowanie jako całość działa poprawnie (np. proces przyznania kredytu gotówkowego – od zalogowania użytkownika, przez wypełnienie formularzy i zawarcie umowy aż po przelanie środków na rachunek).
Obserwacja: nie da się zagwarantować, że jakiś program jest bezbłędny. Możemy jedynie zapewnić, że wykonanie konkretnej wersji programu zgodnie z pewną sekwencją kroków zakończyło się oczekiwanym wynikiem.
System Losowego Przydziału Spraw – spojrzenie pierwsze
Zajrzyjmy do Rozporządzenia Ministra Sprawiedliwości z dnia 18 czerwca 2019 r. „Regulamin urzędowania sądów powszechnych”
Wprowadza ono do powszechnego użycia System Losowego Przydziału Spraw (SLPS) zdefiniowany następująco:
§ 2. [Definicje],
16) SLPS – system teleinformatyczny służący do losowego przydziału spraw i zadań sądu, działający w oparciu o generator liczb losowych (System Losowego Przydziału Spraw).
Dalej mamy rozproszony po całym dokumencie opis tego, co ów System ma robić. Przykłady:
§ 43. [Przydział spraw w wydziałach i sekcjach]
1) Sprawy są przydzielane losowo sędziom jako referentom, zgodnie z podziałem czynności, przez SLPS, oddzielnie dla każdego repertorium, wykazu lub innego urządzenia ewidencyjnego, chyba że przepisy niniejszego rozporządzenia przewidują inne zasady przydziału.
§ 50. [Tworzenie przez SLPS składów orzekających]
1) Na potrzeby przydziału spraw rozpoznawanych w składzie 3 sędziów SLPS losowo tworzy, na okres do 12 miesięcy, składy, którym przydziela sprawy referentów. Jeśli SLPS nie wyznaczy pozostałych dwóch członków składu, wyznacza ich przewodniczący wydziału.
§ 74. [Raport z losowania lub zarządzenie o przydziale]
W aktach spraw przydzielonych przez SLPS, zamieszcza się wydruk raportu z losowania.
Wiecie, co mnie – jako programistę – bawi w tym Regulaminie najbardziej? Otóż nie dowiadujemy się, gdzie to oprogramowanie miałoby działać. Tak zwyczajnie, na którym komputerze, bo jest ich na świecie więcej niż jeden. Z kontekstu wiadomo, że jest to scentralizowany system działający pod kontrolą ministerstwa, ale równie dobrze SLPS mógłby być tak programem dla Windows działającym w sekretariacie sądu, jak i programem na smartfona działającym na komórce prezesa sądu. Albo ministra, bo czemu by nie.
Odłóżmy jednak rozważania na temat tego, jak mały Zbysio wyobraża sobie specyfikację techniczną i funkcjonalną oprogramowania. Czas na inny kawałek wiedzy.
Liczby losowe w komputerze
Komputery nie działają w sposób losowy. Ich głównym celem jest totalna powtarzalność przeprowadzanych operacji. Gdy liczymy rozwinięcie liczby pi z dokładnością do pięćdziesięciu tysięcy miliardów liczb po przecinku (rekord ze stycznia 2020), to niezależnie od obranej metody oczekujemy zawsze takiego samego wyniku.
Gdy chcemy mieć do czynienia z wartościami prawdziwie losowymi, musimy zdać się na nieprzewidywalne zjawiska fizyczne, np. pomiar rozpadu izotopów promieniotwórczych, przejścia fotonów przez półprzezroczyste zwierciadło czy szumu termicznego wzbudzanego przez oporniki w obwodzie elektrycznym. W znakomitej większości przypadków wymagana aparatura podniosłaby znacząco koszt komputera, jeśli w ogóle by się w nim zmieściła [dodano 16.12.2020: czytelnicy podpowiadają, że losowość mogą dostarczać tanie moduły TPM oraz bardzo drogie lecz certyfikowane karty rozszerzeń RNG]
Firma Cloudflare, dzięki której niniejszy blog wytrzymał każde dotychczasowe obciążenie, do wzbogacania losowości w swoich systemach wykorzystuje „lampy lava”, w których rozgrzany wosk formuje bąble o kształcie i rozmiarze niemożliwym do przewidzenia.
Frank Vincentz, CC BY-SA 3.0, via Wikimedia Commons

Wszystkie wymienione metody obarczone są jednak wadą – tempo dostarczania wartości losowych jest dość niskie. Jeśli nasz program potrzebowałby miliona takich liczb na sekundę, mamy problem, bo zmiana wyglądu lava lampy w ciągu milionowej części sekundy jest zbyt mała. Pojedyncza lampa dostarczy raczej jeden losowy bit (wartość 0 lub 1) na kilkanaście lub kilkadziesiąt sekund.
Liczby pseudolosowe w komputerze
Jak wiele rzeczy w IT, losowość w komputerze jest delikatnym oszustwem. W powszechnym użyciu mamy bowiem generatory liczb pseudolosowych (ang. pseudo-random number generator lub PRNG), na przykład Mersenne Twister. Algorytmy PRNG są w stanie generować w dużym tempie wysokiej jakości liczby pseudolosowe. Jeśli interesuje cię, jak sprawdza się jakość generatorów, zajrzyj do tego artykułu.

Czasem brak losowości można dostrzec gołym okiem. Weźmy ciąg losowych bitów, przypiszmy zerom i jedynkom kolory biały i czarny a potem przygotujmy z tego ciągu kwadratowy obrazek. Gdy pozwolimy zrobić to za nas serwisowi random.org, zobaczymy grafikę podobną do poniższej.

Teraz weźmy drugi obrazek:

Od razu widzimy, że drugi obraz zawiera regularności, co szesnasty bit jest całkowicie przewidywalny, widać też skupiska zer i jedynek. Osoba świadoma tej usterki generatora będzie znać zawczasu wynik części losowań.
Generator liczb pseudolosowych musi być zainicjowany tzw. ziarnem (ang. seed – uwaga, link do Minecraft Wiki) czyli zestawem kilkuset zer i jedynek który wstępnie „zamiesza” wewnętrzne rejestry generatora. Użycie takiego samego ziarna będzie skutkować identycznym ciągiem generowanych wartości. Osoba znająca ziarno może więc przewidzieć wszystkie kolejne wartości pochodzące z generatora.
Wracamy na chwilę do Regulaminu sądów
Pamiętacie jeszcze główny wątek? Cytowaliśmy tam regulamin sądów: „Sprawy są przydzielane losowo sędziom […] przez SLPS”. Przed chwilą dowiedzieliśmy się jednak, że znajomość ziarna pozwala przewidzieć wartości losowe, które pojawią się w przyszłości.
Mamy więc do czynienia z systemem komputerowym, który będzie realizował algorytm „losowego” przydziału spraw za pomocą generatora liczb pseudolosowych. Jeśli ktoś zna ziarno, może przewidzieć wynik takiego losowania. Jeśli ktoś ma wpływ na ziarno, może kontrolować wynik losowania.
Większości błędów oprogramowania nie widać
Wróćmy do tematu testowania i błędów.
Hasło „błąd w oprogramowaniu” często przywodzi na myśl niebieski ekran Windows, jednak w rzeczywistości większość usterek daje się zaobserwować jedynie w specyficznych okolicznościach i nie prowadzi do utraty danych ani zawieszenia programu.
Ten blog działa na oprogramowaniu WordPress. Tutaj można zobaczyć listę błędów poprawionych w wydaniu 5.6, na 218 zgłoszeń mamy cztery błędy blokujące, dwa krytyczne, pięć poważnych i… ponad 200 usterek z którymi da się żyć. Niektóre są poprawiane po sześciu lub więcej latach.
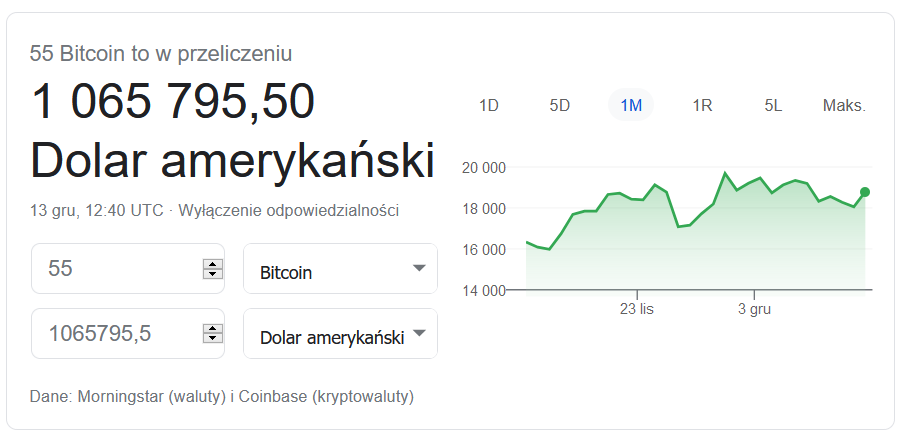
Niestety, błędy generatora liczb pseudolosowych są zazwyczaj niewidoczne – aż do chwili, kiedy ktoś wykorzysta ich słabość. Dobre źródło losowości jest potrzebne m.in. w zastosowaniach kryptograficznych. Na kryptografii oparta jest kryptowaluta Bitcoin. Można z tego wysnuć wniosek, że niedostateczna losowość przełoży się na niedostateczne bezpieczeństwo portfeli bitcoinowych i tak właśnie jest. Oto przykład – w roku 2013 odkryto słabość PRNG w Androidzie, której efektem były kradzieże bitcoinów z portfeli utworzonych na telefonach. Atakujący mógł przewidzieć stan generatora liczb losowych w urządzeniu ofiary, odtworzyć klucz prywatny portfela i zlecić w imieniu ofiary przelew środków.
Serwis Ars Technica donosił, że ukradziono w ten sposób co najmniej 55 BTC, wartych wówczas 5720 USD. Mam nadzieję, że ofiara jakoś przepracowała tę stratę, bo przy dzisiejszym kursie bitcoina to troszkę ponad milion dolarów.
Programiści Stack Overflow
Co robi typowy wyrobnik kodu, gdy staje przed nieznanym problemem? Sięga do portalu Stack Overflow czyli gigantycznej skarbnicy pytań i odpowiedzi, od programistów dla programistów. Odnajduje tam losową odpowiedź na pytanie względnie zbliżone do napotkanego problemu, kopiuje przykładowy kod do swojego projektu i jeśli coś jako-tako zadziała, problem uznaje się za rozwiązany.
Przykład z życia – pada pytanie, dlaczego w załączonym kodzie mimo użycia losowego ziarna wartości z generatora liczb pseudolosowych się powtarzają.

Przyczyną jest oparcie ziarna o wartość zegara, z dokładnością do tysięcznej części sekundy, tymczasem cytowany kod wykona się w tym czasie wielokrotnie, stąd duplikaty. Co gorsza, do ziarna trafiają jedynie trzy cyfry dziesiętne, więc ów kod zawsze wygeneruje jeden z raptem tysiąca ciągów liczb pseudolosowych.
Co poradzono pytającemu?
Odpowiedź numer jeden – pauzować wykonanie programu na milisekundę.
Odpowiedź numer dwa – zamiast milisekund użyć… nanosekund!
Obie odpowiedzi są bezwartościowe i szkodliwe, w przypadku cytowanego środowiska i języka programowania nie należy w ogóle ustawiać ziarna w PRNG, będzie ono automatycznie zainicjowane przez system operacyjny wartością o wiele bardziej losową niż data i czas.
Inny przykład – blogonotka objaśniająca m.in. problemy z inicjalizacją ziarna. Zawiera fragmenty kodu oznaczone jako „ANTI-PATTERN, do not copy-paste” czyli „ANTYWZORZEC, nie kopiować/wklejać”. Nie trzeba chyba dodawać, że to ułomny lecz działający kod, który daje się… wkleić do własnego programu.
Obecność w internecie takich pytań wraz z takimi odpowiedziami może stanowić wygodne alibi dla kogoś, kto zechce osadzić w programie fragment kodu ustawiający kontrolowane przez użytkownika ziarno: „och, faktycznie, jest tu pewna niewinna niedoskonałość, widocznie programista pisząc tę linijkę kodu zainspirował się niewłaściwym przykładem”.
Wracamy ponownie do Regulaminu sądów
„Sprawy są przydzielane losowo sędziom […] przez SLPS”.
Przed chwilą pokazaliśmy, że kod inicjujący ręcznie ziarno generatora liczb pseudolosowych na bazie daty i czasu pozwoli na kontrolowanie „losowanej” wartości. Tutaj trochę uproszczę, ale możliwa ścieżka nadużycia mogłaby wyglądać następująco: jeśli w losowaniu danej sprawy bierze udział sześciu sędziów i chcemy wylosować sędziego nr 1 albo 4, należy spojrzeć na zegarek i kliknąć przycisk losowania w sekundzie nr 1, 12, 13, 32, 44, 48, 55, 56 albo 57. Nie musi to być zresztą sekunda, może być minuta.
Co gorsza, wytwórca kodu pozwalającego na takie nadużycia będzie w stanie wiarygodnie wykręcić się, że usterka nie jest celowa zaś jej przyczyną były niskie kwalifikacje programisty, który skopiował felerny wycinek kodu z internetu.
Wszystkie pozostałe parametry losowania (liczba spraw, liczba sędziów oraz ich obciążenie, liczba dni nieobecności sędziego) są wtórne i nie mają znaczenia dla tez formułowanych w niniejszym artykule. Zawsze będzie bowiem istniała możliwość sprawdzenia, jak zmanipulowana liczba pseudolosowa przełoży się na wynik konkretnego losowania.
Rozkład prawdopodobieństwa
Nie chcę utracić resztek uwagi czytelników, którzy jeszcze śledzą tekst, więc ten problem tylko zasygnalizuję: losowość w komputerze to nie tylko „sprawiedliwy” wybór jednej z kilku wartości. Możemy na wiele sposobów regulować prawdopodobieństwo wyboru – na przykład sprawić, by „środkowe” numery wypadały częściej.
Jeśli ktoś grał w „Osadników z Catanu” to dobrze wie, że suma oczek z dwóch kostek sześciennych będzie równa dwa w średnio jednym na 36 rzutów, tymczasem suma równa siedem wypadnie aż sześć razy na 36 rzutów.
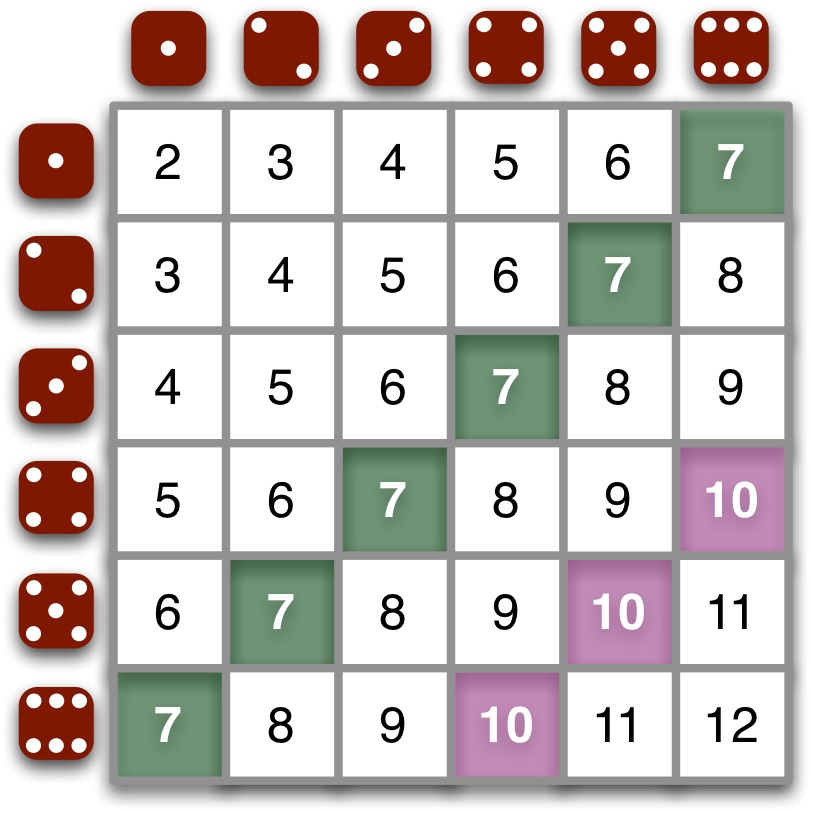
Zbyt duże anomalie w codziennych losowaniach mogłyby zostać zauważone, ale np. zmanipulowane losowanie składów sędziowskich raz w roku – prawie na pewno nie.
Co się pisze o SLPS
Sędzia Aneta Łazarska pisze w cyklu artykułów publikowanych w serwisie lex.pl między innymi:
[…] Zasadniczym mankamentem tego uregulowania jest brak dostępności danych dotyczących zasad pracy narzędzia informatycznego. Według zaś orzecznictwa administracyjnego algorytm losowania nawet nie stanowi informacji publicznej, co niewątpliwie może budzić kontrowersje, gdyż przydział spraw w sądzie ma nie tylko stricte techniczne znaczenie, lecz stanowi realizację prawa do ustawowego sędziego. Niezależnie więc od tego, czy sprawy przydziela człowiek, komputer czy generator liczbowy, rozdział spraw pomiędzy sędziów powinien być oparty na transparentnych zasadach poddających się kontroli zewnętrznej (art. 45 ust. 1 Konstytucji RP), szczególnie gdy obecnie to Minister Sprawiedliwości określa te zasady. […]
[…] Brak gwarancji transparentnego przydziału spraw ma istotne znaczenie dla realizacji
prawa obywatela do rzetelnego procesu, umożliwia bowiem ręczne sterowanie procesem, a nierzadko i dobór dyspozycyjnych sędziów orzekających według życzenia i polecenia władzy […]
[…] System losowego przydziału spraw (SLPS) jest aplikacją sieciową, dostępną z komputerów zalogowanych do wewnętrznych sieci informatycznych w sądach. Centralny komputer wykorzystujący generator liczb losowych po rejestracji spraw dokonuje ich losowego przydziału. Mankamentem przyjętych rozwiązań jest brak danych dotyczących algorytmu losowania, co może stanowić zagrożenie dla prawa do ustawowego sędziego i niezawisłości sędziowskiej […]
[…] Centralny komputer wykorzystujący generator liczb losowych kolejno zajmuje się po godzinach pracy sądu każdy wydziałem. Sprawy wniesione do sądu z chwilą ich wpływu są rejestrowane w odpowiednich repertoriach lub wykazach. Następnie sprawy podlegające losowemu przydziałowi rejestruje się w systemie informatycznym, obsługującym narzędzie informatyczne najpóźniej w ciągu dwóch dni roboczych od dnia wpływu do sądu, chyba że sprawa podlega przydziałowi po uzupełnieniu braków (§ 43 ust. 1 i 3). Oznacza to, że już na pierwszym etapie po rejestracji następuje selekcja spraw na te, które są losowane, i te, które są wyłączone spod losowania.[…]
Temat SLPS podnoszony był także w następujących publikacjach:
Forsal.pl – System losowania spraw przychylny dla ministra
„Minister sprawiedliwości ma sporo szczęścia. Sprawę, w której jest pozwanym, dostał do prowadzenia sędzia, który wydawał wyroki korzystne dla Krystyny Pawłowicz, ówczesnej poseł PiS”
oraz
„Mało prawdopodobne jest, aby ktoś mógł dokonywać celowych zmian w systemie i nielegalnie wpływać na wyniki losowań. Taka sytuacja wymagałaby zmowy przewodniczącego wydziału, kierownika sekretariatu, kogoś z MS i informatyka obsługującego system“.
W niniejszym tekście pokazałem, że to nieprawda. Gdy możliwość wpływania na mechanizm losowania została osadzona w systemie, wystarczy jedna osoba mająca wiedzę o sposobie doprowadzenia do pożądanego wyniku. Nic nie stoi na przeszkodzie, aby do wpływu na wynik losowań wystarczał zdalny dostęp z podstawowymi uprawnieniami.
Archiwum Osiatyńskiego – System Losowego Przydziału Spraw w sądach powszechnych
„Nie mamy pewności, wbrew zapewnieniom ministerstwa sprawiedliwości, że urządzenie elektroniczne przeprowadza losowania w sposób całkowicie przypadkowy (losowy). Mechanizm losowania tworzony jest za pomocą algorytmu, stworzonego przez człowieka. Nie znając tegoż algorytmu, ani zasad funkcjonowania programu (brak kodu źródłowego) nie sposób ustalić rzeczywistych kryteriów doboru sędziów, stosowanych przez SLPS.”
Gazeta Prawna – SLPS, czyli Swoim Lepszy Przydział Spraw
„[…] przez kilka pierwszych miesięcy działania SLPS do akt każdej sprawy dołączany był raport zawierający nazwiska wszystkich sędziów biorących udział w losowaniu, odpowiednie współczynniki techniczne i wskazanie osoby, do której ostatecznie sprawa trafiła. Dokument ów zastępował zarządzenie przewodniczącego o przydzieleniu sprawy. Nie wiedzieć czemu zrezygnowano z rozbudowanego raportu na rzecz skróconego, o treści ograniczającej się do wskazania nazwiska sędziego, któremu system sprawę przydzielił. Brak zatem nazwisk pozostałych sędziów biorących udział w losowaniu. Z pewnością zmiana ta nie przyczynia się do zwiększenia lansowanej przez resort sprawiedliwości transparentności “
Sprawozdanie z lustracji II Wydziału Karnego Sądu Okręgowego w Toruniu […] przeprowadzonej przez SSA Wojciecha Andruszkiewicza […] z dnia 11 września 2018
„Tak więc jedynym źródłem poznania mechanizmu funkcjonowania SLPS są przepisy wyżej przytoczonego Regulaminu (paragrafy od 43 do 61) oraz doświadczenie nabywane po obserwacji funkcjonowania SLPS […]
Wprowadzeniu systemu SLPS towarzyszyło założenie, że działa on bezbłędnie a nieprawidłowości wynikają z błędów popełnianych przez osoby wprowadzające dane do systemu, a te mogą być korygowane przez system w kolejnych losowaniach.”
Fundacja ePaństwo – (Nie)słodka tajemnica losowania sędziów
„Znowu złapaliśmy się na naszej naiwności, bo po złożeniu wniosku o przekazanie raportów, ministerstwo poinformowało, że potrzebuje więcej czasu na analizę danych i przekaże nam odpowiedź później niż po ustawowych 14 dniach. Oczekiwaliśmy, że o ile ministerstwo uważa, że algorytm opisuje działanie systemu komputerowego, to wyniki jego działania stanowią informację o sprawach publicznych. Bo czym innym jest informacja, jakiemu sędziemu, kiedy przyznano jaką sprawę.
Jednakże, zdaniem ministerstwa i takie raporty nie stanowią informacji publicznej, ponieważ “stanowią “produkt” działania narzędzia informatycznego jakim jest program komputerowy przeznaczony do losowego przydziału spraw sądowych (…).” W konsekwencji, również te dane zostały zakwalifikowane jako informacja techniczna, czyli taka, która nie podlega udostępnieniu.”
tl;dr
W niniejszym tekście starałem się pokazać, że:
- program napisany przez programistę nie zawsze będzie realizował założony w specyfikacji algorytm przetwarzania danych
- testowanie programu nie zawsze wychwyci popełnione błędy
- w komputerze bardzo ciężko o prawdziwą losowość, z reguły stosuje się generatory liczb pseudolosowych
- działanie generatora liczb pseudolosowych można zaburzyć, wówczas da się z góry wyznaczyć wszystkie przyszłe wartości zwracane przez generator
- temat losowości jest trudny i wielu programistów nie ma świadomości możliwych do popełnienia błędów
- celowe błędy wpływające na działanie generatora liczb pseudolosowych mogą wyglądać tak, jak staranny kod niekompetentnego programisty
- celowe zaburzenie generatora liczb pseudolosowych może sprawić, że osoba kontrolująca parametry zaburzenia będzie mogła doprowadzić do pożądanego wyniku losowania
Bez dostępu do kodu źródłowego opinia publiczna nie jest w stanie zweryfikować, czy „losowość” w SLPS rzeczywiście realizuje postulat przypadkowego (tj. „sprawiedliwego”) przydziału spraw sędziom.
W roku 2018 została wystosowana interpelacja nr 18006 posła Pawła Pudłowskiego i posłanki Kamili Gasiuk-Pihowicz, w której znalazły się następujące pytania dotyczące SLPS:
„1. Dlaczego nie ma możliwości sprawdzenia kodu oprogramowania?
2. Dlaczego system ma być transparentny tylko dla wybranej grupy zainteresowanych?
3. Jeśli kod źródłowy jest własnością Skarbu Państwa, to ministerstwo może go udostępnić – dlaczego nie chce tego zrobić?
4. Czy rzeczywiście dobór sędziów i spraw będzie się odbywał w stu procentach losowo?
5. Dlaczego administratorem zbioru danych do losowania ma być Ministerstwo Sprawiedliwości?”
Odpowiedź pełna była tez które można bez większego problemu podważyć:
„Program komputerowy napisany prawidłowo realizuje algorytm, tj. działa tak, jak przewiduje algorytm.”
– skąd jednak wiadomo, że SLPS napisano prawidłowo?
„Nieujawnienie kodu źródłowego nie oznacza braku transparentności. Zasady działania systemu, przydziału spraw, zostały opisane w uzasadnieniu projektu rozporządzenia”
– nie wiemy, czy implementacja SLPS realizuje założenia Regulaminu sądów. Bez znajomości kodu źródłowego nie będziemy wiedzieć niczego o rzeczywistym sposobie działania SLPS. Cytowany wyżej tekst fundacji ePaństwo pokazuje, że nie sposób dziś uzyskać informacji o żadnym aspekcie funkcjonowania SLPS. Słowem – jest on zaprzeczeniem transparentności.
Obserwacja wyników działania systemu i otrzymane zapewnienia o poprawności realizacji to zdecydowanie za mało. Dopiero analiza kodu źródłowego pozwoliłaby specjalistom na określenie, w jakim stopniu zrealizowany algorytm zgodny jest z zapisami Regulaminu. Dodajmy, że obecny tam opis SLPS – rozrzucony po wielu artykułach, punktach i podpunktach – nie ma wiele wspólnego ze specyfikacją programu komputerowego.
Co istotne – znajomość źródeł w żaden sposób nie obniży bezpieczeństwa rozwiązania informatycznego. Wszystkie informacje mające wpływ na poufność konkretnej instalacji (adresacja sieciowa, identyfikatory API, prywatne klucze szyfrowania itp.) powinny być wydzielone z kodu źródłowego i stanowić parametryzację, zgodnie ze znanymi i szeroko stosowanymi praktykami wytwarzania i utrzymania oprogramowania.
Jak mógłby działać w pełni przejrzysty SLPS, którego działania nikt nie zakwestionuje?
Nawet dostęp do kodu źródłowego nie da nam pewności, że na serwerach ministerstwa rzeczywiście działa program skompilowany z udostępnionych publicznie plików. Jak mimo tego upewnić się, że przydział spraw rzeczywiście bazuje na „sprawiedliwej losowej losowości”?
Odpowiedź jest prosta – najpierw ogłaszana jest lista losowań, potem zbieramy/tworzymy losowe ziarno dla generatora liczb pseudolosowych, następnie przeprowadzamy losowania w ustalonym porządku, ustalonym algorytmem.
Przykładowa realizacja:
- do godziny 14:00 sądy wprowadzają do SLPS sprawy podlegające losowaniu, tworzone są losowania, do losowań przydzielani są sędziowie (składy, referendarze, itp.)
- do godziny 15:00 publikowany jest podpisany cyfrowo i znakowany czasem spis wszystkich losowań i ich uczestników
- o godzinie 17:00 zamykane są notowania GPW – wówczas obroty i kurs zamknięcia wybranych indeksów przepuszczamy przez funkcję skrótu, wynik tej operacji stanowi ziarno generatora liczb losowych
- o godzinie 18:00 SLPS przeprowadza losowania i publikuje wyniki a każdy chętny może powielić te obliczenia i przekonać się, czy otrzymał takie same rezultaty
Kursy akcji z GPW to oczywiście przykładowe źródło losowości – chodzi o to, by bazować na wiedzy dostępnej publicznie, uprzednio nieprzewidywalnej a dającej się weryfikować wieloma kanałami.
Słowo na zakończenie
Niniejszy artykuł opisuje tylko jedną z wielu sytuacji, w której sprawy publiczne stykają się z komputerami i technologią. Niestety, za mało jest publikacji objaśniających wzajemny wpływ tych dwóch obszarów i stąd właśnie biorą się takie wyroki jak:
„Głównym zastosowaniem kodu źródłowego jest wyrażanie programów komputerowych w zrozumiałej postaci, co skłania do przyjęcia tezy, że kod źródłowy nie zawiera jakiegokolwiek komunikatu o sprawach publicznych i stanowi jedynie narzędzie wykorzystywane w programach komputerowych. Okoliczność, że określone programy komputerowe są wykorzystywane przez organy władzy publicznej do realizacji zadań publicznych, nie przesądza, że kody źródłowe są informacją publiczną.” (Wyrok NSA – I OSK 2014/13).
W przypadku SLPS kod źródłowy jest jednak zestawem reguł na bazie których decyzje organów państwa niejako podejmą się same!
Jeśli źródła SLPS mają pozostać tajemnicą, to równie dobrze możemy przekształcić w program komputerowy sporą część Kodeksu postępowania administracyjnego. Odpadną wszystkie spory o terminy zawite i przedawnienia – nieomylny komputer ministerstwa przyjmie skan pisma, wypluje decyzję i nikt nigdy nie dowie się, jakie reguły wnioskowania do niej doprowadziły. Po co zresztą komputer, tę samą robotę ogarnie w kilka godzin byle szaman.
Całkowite pominięcie technicznych aspektów SLPS w ministerialnym rozporządzeniu wynika pewnie z tego, że dla osób parających się prawem i przepisami hasło „generator liczb losowych” przekłada się mentalnie na „sprawiedliwa, niepodważalna, losowa decyzja nieobarczona czynnikiem ludzkim”. Tak jednak nie jest. Reguły określił programista a owocem jego kompetencji i interpretacji Regulaminu jest oprogramowanie, które przydziela tysiącom sędziów miliony spraw. Miejmy nadzieję, że owe kompetencje były wystarczające a intencje – czyste.

PS: pracowałeś/aś przy tworzeniu SLPS? Proszę o kontakt, zapewniam anonimowość.
Za pomoc w dostępie do materiałów dziękuję Łukaszowi Jurdze, za kontrolę merytoryczną tekstu – Krzysztofowi Izdebskiemu z Fundacji ePaństwo
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

23 odpowiedzi na “System Pseudolosowego Przydziału Spraw”
A co by było gdyby okazało się, że program który losuje sprawy ma błąd, lub da się wpłynąć na jego działanie? Czy to oznacza, że sprawy sądowe, które prowadzili sędziowie wylosowani przez program są do ponownego rozpatrzenia? Ministerstwo z pewnością nie chce się przekonać, bo oznaczałoby to paraliż wymiaru sprawiedliwości.
Tym bardziej trzeba naciskać na transparentność w tym zakresie. Chodzi o to, żeby władza zrozumiała, że jawność przynosi korzyść wszystkim. Wszak taki klops nigdy by się zdarzył przy przejrzystym procesie tworzenia i wdrażania algorytmu, bo zostałby fafnaście razy po do drodze wychwycony.
W pokoju programistów powinien być kij albo pas. Nieskomentowanie funkcji 1x kijem! Za nienapisanie testu do funkcji 2x kijem! Za kopiuj-wklej z netu bez analizy skopiowanego fragmentu 8x kijem! TDD teoretycznie spowalnia proces wytwarzania kodu na początku, ale praktyka pokazuje, że pisze się 3x szybciej.
Za używanie nie razem z czasownikami – 15x kijem. Aż oczy bolą.
To są rzeczowniki:
Co? Napisanie, nienapisanie.
Komentowanie, niekomentowanie.
To raz. Dwa, z czasownikami też powinno być łącznie, jak po czesku. Mówi się „niEdaj”, „niEpodAwaj”, więc czemu ma się pisać „nie dAj”, „nie podAwaj”?
Szanujemy bardzo za opracowanie
Przeczytałem z wielką uwagą Pana artykuł. Pomimo że jestem prawnikiem w przeszłości dużo interesowałem się kwestią programowania, losowań wykonywanych za pośrednictwem oprogramowania itp. Z moich analiz na przykładzie praktycznego funkcjonowania SLPS w wydziale wynika, że to o czym Pan pisze w artykule potwierdza się w praktyce. Do referatów niektórych sędziów losowane są sprawy nieproporcjonalnie częściej niż do innych. Tytułem przykładu mogę podać że pięć bardzo rzadkich spraw wylosowało na przestrzeni roku dwóch sędziów na dziesięciu biorących udział w losowaniu. W moim przekonaniu również algorytm i sposób przydziału spraw jest wadliwy – osobom funkcyjnym przydziela mniej spraw niż to wynika z oficjalnego współczynnika przydziału. Czyli np. przewodniczący który ma mieć 50 % przydziału de facto dostaje koło 30-40 %. Podobnie inni funkcyjni. Pozdrawiam
Podzielam tę obserwację. Dodam, że podobno istnieje połączenie ZSRK z SLPS (tak wynika z informacji ministerstwa) ale nikt nie chce udzielić odpowiedzi, czy np. uwzględnia obniżenie wpływu wyznające z wykonywania urlopu wychowawczego przy tze. losowaniach na żądanie.
„Całkowite pominięcie technicznych aspektów SLPS w ministerialnym rozporządzeniu wynika pewnie z tego, że dla osób parających się prawem i przepisami hasło „generator liczb losowych” przekłada się mentalnie na „sprawiedliwa, niepodważalna, losowa decyzja nieobarczona czynnikiem ludzkim”.”
Bardzo bym chciał, żeby jedyny powód był taki, że wszystkie osoby odpowiedzialne za wprowadzenie i utrzymywanie takiego stanu rzeczy, to gamonie. Niestety w świetle dziennikarskiej pracy śledczej Tomasza Piątka bardziej prawdopodobnym wydaje mi się, że sędziów wybiera nam obecnie „Kreml”. Zresztą sama statystyka działa tu na niekorzyść, bo to bardzo mało prawdopodobne, żeby w co najmniej kilkudziesięcioosobowym gronie osób trafiły się same gamonie.
W kwestii losowości – GPW nie jest losowa. Kursami można manipulować.
Obrotami znacznie trudniej. A skoordynować obroty i kursy zamknięcia dziesięciu czy dwudziestu walorów byłoby już zadaniem dla Chucka Norrisa.
Z giełdą to różnie bywa, może np. być zamknięta z powodu awarii, skrócić/wydłużyć notowania itd. Ale wiem, że to był tylko przykład. Zresztą pan Ts’o nie raz się rozpisywał na temat mieszania entropii z różnych źródeł więc giełda jako jeden ze strumieni jest całkiem niezła, do tego np. szum mikrofalowego promieniowania tła i co tam jeszcze przyjdzie do głowy. Albo… certyfikowane urządzenie ze sterownikami żeby nie tracić czasu na implementację wszystkiego samemu. Któryś-tam FIPS wystarczy by spać spokojnie – nie popadałbym w paranoję.
Ale przecież w tym przypadku nie o to chodzi, żeby mieć całkowicie losowy seed niewiadomego pochodzenia, ale pochodzenie tego „mniej losowego” seeda było jasne i przejrzyste a przede wszystkim trudne do zmanipulowania.
Jestem w stanie wyobrazić sobie przypadek, gdy urząd publikuje „losowego” seeda, z „certyfikowanego urządzenia”, do tego przedstawionego algorytmu, wszystko działa a sprawa jest przypisana do takiego sędziego do jakiego urząd chciał.
Taki nam się seed wylosował i co nam pan zrobi?
Przypominam, że Morawiecki już kiedyś zatrudnił Chucka N (do tej reklamy o fuck-turach).
Super artykuł! Co do konieczności zadawania generatorowi liczb pseudolosowych za każdym razem nowego ziarna – w .NET zalecane jest używanie RNGCryptoServiceProvider, który nawet nie umożliwia zadania ziarna, a zapewnia o niebo lepszą losowość niż podstawowy generator System.Random. Polecam bardzo przyjemny artykuł na ten temat https://lowleveldesign.org/2018/08/15/randomness-in-net/
A co jeśli po prostu zawęża się pulę osób losowanych do zbioru osób, które mają być wylosowane? Ordynarne, ale skuteczne, jeśli nikt tego nie weryfikuje. Specyfikacja pewnie nie zawiera detali na temat rozliczalności i publikacji danych cząstkowych. Po co wnikać w to całe matematyczno-informatyczne bagno jak można na chama wylosować 3 z 3 sędziów…
A same generatory losowego szumu są drogie tylko dlatego, że mają drogą certyfikację. Przeciętny elektronik za parę złotych zrobi coś wystarczająco dobrego, a za dość zabawną kwotę kilku tysięcy USD można nabyć certyfikowane urządzenie. Zrobić taki system w sposób porządny i działający transparentnie to nie jest wielka sztuka.
Sztuką jest nie bać się tego zrobić. A politycy z odwagą często mają na bakier.
Jak już czepiałem się na ćwiterze, to zdanie jest nieprawdziwe. Generatory liczb losowych od dawna są częścią TPM-ów, wcześniej bywały montowane na płytach głównych. Dziś znajdziemy je w procesorach Intela, AMD a także w wielu SoC-ach ARM (i pewnie innych też). Tak, nie są to urządzenia bardzo wydajne. Dostarczają dziesiątki kB/s szumu, ale do znakomitej większości zastosowań to wystarcza. Do SLPS również by wystarczyło, gdyby nie korzystać z liczb dostarczonych przez GPW. Ze względu na przejrzystość to jest całkiem dobry pomysł.
Słuszna uwaga, dodałem w tekście informację o TPM i sprzętowych RNG.
Świetny pomysł z algorytmem używającym notowań GPW jako ziarna.
Losowanie jest zbędne. Częś sędziów jest ustawiona politycznie. Część to złośliwcy którzy chętnie „dowalają” w wyrokach. Pozostali nie chcą się wychylać i będą orzekać z trendami żeby się nie pogrążyć.
Dzięki za artykuł, czyta się to świetnie nawet gdy nie wszystko rozumiem, bo programistą nie jestem, jednak mam odrobinę intuicji, by rozumieć podstawy działania programów.
A zmieniając lekko temat, choć pozostając przy pseudolosowosci, to mam anegdotkę. Otóż jak jeżdżę samochodem, to często puszczam sobie w radiu muzykę z pendrive’ach. I – jako że znam już te utwory na pamięć niemalże, to często wciskam przycisk „random”, by trochę mieć zaskoczenia, co będę za chwilę słuchał.
I oczywiście po kilku sesjach zauważyłem, że znowu – wiem jaki utwór będzie za chwilę, rzadko się tu mylę. I że spora część utworów w ogóle prawie nigdy nie zostaje odsłuchana.
Taką to losowość daje komputer. 😉
Wiekszy problem jest z regulaminem i składami wieloosobowymi. SLPS generuje referenta a pozniej ręcznie – wg uznania dodaje się dwóch bocznych. Nie raz po dłuzszym czasie. Dalej ! Na dzien losowania rererenta wyłacza się z losowania sedziów którzy mają krótki urlop lub wiedząc, ze coś idzie do sądu biorą jeden dzien urlopu lub L 4 na jedzen dzien. MZ cały czas manupuluje regulaminem sądów , nawet dokonuje zmian z mocą wsteczna. Sprawą niedługo zajmie sie TK i ETPCz. SLPS neguje nawet KRS