
Rok temu byłem z przyjaciółmi na wycieczce w górach. Ja pstrykałem zdjęcia smartfonem, kolega – zaawansowaną lustrzanką cyfrową. Gdy je porównaliśmy, okazało się, że moje są… ładniejsze. Owszem, ujęcia z lustrzanki były technicznie o wiele doskonalsze i obróbka w „cyfrowej ciemni” pozwoliłaby wydobyć z nich naprawdę piękne obrazy. Nie było jednak wątpliwości, że komórka z obiektywem wielkości łebka od szpilki dostarczała na poczekaniu fotografie przyjemniejsze w odbiorze od tego, co rejestrował aparat za milion monet.
Przez długi czas chciałem napisać artykuł opisujący ten fenomen. Okazało się, że nie muszę – tekst taki przygotował rok temu Wasilij Zubariew prowadzący bloga vas3k.com. Oryginał dostępny jest w języku rosyjskim, tutaj znajdziesz wersję angielską. Poniżej prezentuję polskie tłumaczenie, w którym – za zgodą autora – wprowadziłem kilka zmian. Zapraszam do lektury!
tłumaczenie – Tomasz Zieliński
korekta – Ewa Dacko, Wojtek Sz., Michał Bielecki
Wasilij Zubariew
Fotografia obliczeniowa
Od selfiaków do czarnych dziur
Gdy na rynku debiutuje nowy model smartfona, nie sposób wyobrazić sobie jego premiery bez wychwalania wbudowanego aparatu fotograficznego. Co chwilę dostajemy coś nowego – Pixel od Google robi zdjęcia w ciemności, Huawei ma zoom jak teleskop, Samsung dorzuca do zestawu lidar, zaś Apple prezentuje światu najbardziej zaokrąglone narożniki w branży. Innowacja goni innowację.
Cyfrowe lustrzanki przeciwnie – tkwią w letargu. Sony co roku wypuszcza na rynek nowe wielomegapikselowe matryce, a producenci aparatów robią w kwestii ulepszania swoich produktów to, co wszystkie tłuste misie, czyli niewiele. W najlepszym razie podbijają numery wersji zeszłorocznych konstrukcji. Mam na biurku Nikona za 3000 dolarów, ale na wycieczki zabieram iPhone’a. Dlaczego?
Odpowiedzi na to pytanie szukałem w sieci. Znalazłem wiele dyskusji na temat „algorytmów” i „sieci neuronowych”, ale nikt nie potrafi precyzyjnie wyjaśnić ich wpływu na fotografię. Dziennikarze podniecają się liczbą megapikseli, blogerzy zasrywają internet kolejnymi „unboxingami” a foto-nerdzi nie przestają rozwodzić się nad „zmysłową percepcją palety barw matrycy”. Ach, internecie, krynico mądrości. Kochamy cię.
Nie pozostało mi nic innego, jak doktoryzować się w zakresie fotografii cyfrowej. Spiszę tu wszystko, czego się dowiedziałem, w przeciwnym razie zapomnę to za miesiąc.
Czym jest fotografia obliczeniowa
Definicja fotografii obliczeniowej brzmi mniej więcej tak: techniki cyfrowego rejestrowania i przetwarzania obrazu, które wykorzystują obliczenia cyfrowe zamiast procesów optycznych. Niby prawda, a jednak bzdura, bo choć taka definicja obejmuje autofocus, to poza zakresem zostaje choćby aparat plenoptyczny (rejestrujący pole światła, jeszcze do niego wrócimy). Tak naprawdę więc nadal nie wiemy, o czym mowa.
Mark Levoy, profesor Uniwersytetu Stanforda i pionier fotografii obliczeniowej (przez wiele lat odpowiedzialny za aparaty w smartfonach Google Pixel), sformułował inną definicję: techniki wspomagania lub rozszerzania możliwości fotografii cyfrowej w taki sposób, by efektem było zdjęcie niemożliwe do wykonania tradycyjnym aparatem. Ta definicja bardziej mi się podoba i będę z niej korzystał w dalszej części tego artykułu.
Twórcy smartfonów nie mieli innej możliwości, jak tylko powołać do życia nową technikę uwieczniania obrazu – fotografię obliczeniową
Smartfony są wyposażone w szumiące matryce i malutkie, ciemne obiektywy. Praw fizyki nie oszukamy – takie parametry sprzętu będą dla użytkownika jedynie źródłem cierpienia. A raczej były, zanim programiści nie nauczyli się kompensować ułomności sprzętu technikami cyfrowymi: nowatorskim oprogramowaniem działającym na mocnych procesorach.

Większość istotnych badań w zakresie fotografii obliczeniowej przeprowadzono w latach 2005-2015, to w nauce raptem dzień wczorajszy. Telefon w twojej kieszeni korzysta z technologii, które kilkanaście lat wcześniej zwyczajnie nie istniały.

Fotografia obliczeniowa to nie tylko rozmywanie tła w selfiakach, ale także zdjęcie czarnej dziury, niemożliwe do realizacji bez technik cyfrowych. W klasycznej fotografii teleskop musiałby być rozmiarów Ziemi, jednak pierwsze w historii zdjęcie horyzontu zdarzeń czarnej dziury uzyskaliśmy dzięki ośmiu rozsianym po powierzchni planety radioteleskopom zbierającym dane, które potem połączono zmyślnymi skryptami Pythona.
Rozmywanie tła też oczywiście działa jak należy, bez obaw.
📝 Computational Photography: Principles and Practice
📝 Marc Levoy: Nowe techniki w fotografii obliczeniowej
W dalszej części tekstu takie odnośniki, jak powyżej, skierują cię do artykułów lub filmów pogłębiających dane zagadnienie. Zajrzyj do nich, gdy temat szczególnie cię zainteresuje. Jedna blogonotka nie pomieści wszystkiego.
Początek: obróbka cyfrowa
Cofnijmy się do roku 2010. Justin Bieber właśnie wydał pierwszy album, w Dubaju otworzono Burj Khalifa a my nie mogliśmy godnie uwiecznić tych wiekopomnych wydarzeń komórkami, bo na wyjściu dostawaliśmy zaszumione, dwumegapikselowe JPEG-i. Ich nędza była tak wielka, że ukrywaliśmy ją za filtrami postarzającymi obraz. Tak narodził się Instagram.

Matematyka i Instagram
Wraz ze wzrostem popularności Instagrama wszystkich ogarnęła mania nakładania na fotografie filtrów. Jako człowiek, który dokonał reverse engineeringu filtrów X-Pro II, Lo-Fi i Valencja – oczywiście w celach badawczych (hehe) – wciąż pamiętam trzy główne składniki każdego filtra:
- ustawienia kolorystyczne (barwa, nasycenie, jasność, kontrast, poziom itd.) to zwykłe mnożniki, jakie stosowano w fotografii od niepamiętnych czasów

- tone mapping czyli tablica wartości mówiąca „czerwień o nasyceniu 128 ma zmienić nasycenie na 240”. Często reprezentowana jest jako obrazek o wysokości jednego piksela, taki jak ten (przykład z filtra X-Pro II)

- nakładka (overlay) – półprzezroczysty obrazek z szumem, ziarnem, winietowaniem czy innymi ramkami, które po nałożeniu dadzą np. efekt starego filmu. Rzadko używane.

Współczesne filtry są zbliżone do powyższych, ale wymagają przeprowadzenia bardziej złożonych obliczeń matematycznych. Gdy na komórkach pojawiły się shadery i OpenCL, zaczęto używać ich do implementacji filtrów, co było istotną nowością. W roku 2012. Dziś taki efekt może osiągnąć w CSS byle pryszczaty nastolatek.
Rozwój nie zatrzymał się na tamtym etapie, ludzie z Dehancera weszli w filtry nieliniowe. Zamiast biednego tone-mappingu stosują transformacje bardziej wyrafinowane, dające – według nich – o wiele większą swobodę twórczą. Transformacje nieliniowe są jednak bardzo skomplikowane, zaś my – ludzie – jesteśmy prości. Jak zwykle w takich sytuacjach wspomagamy się więc metodami numerycznymi lub sieciami neuronowymi.
Automatyzacja i sen o magicznym przycisku
Gdy wszyscy przywykli do obecności filtrów, zaczęto implementować je bezpośrednio w aparatach. Wiedza o pierwszych takich przypadkach zaginęła w pomroce dziejów. Dość powiedzieć, że już w roku 2011 system iOS 5 miał publiczne API do poprawiania jakości obrazów. Jeden Steve Jobs wie, jak długo było w użyciu przed debiutem publicznym.
Automaty zaczęły aplikować te poprawki, które wcześniej trzeba było wyklikać w aplikacjach graficznych – optymalizację świateł i cieni, korektę ekspozycji, usuwanie efektu czerwonych oczu i retusz koloru skóry. Użytkownicy nawet nie wiedzieli, że „udoskonalona funkcja aparatu” w ich ulubionej aplikacji sprowadzała się do kilku nowych linii kodu dodanych przez programistę.

Dziś poszukiwania magicznego przycisku do mistrzowskiego retuszu odbywają się w obszarze machine learningu. Wszyscy znużeni tone mappingiem zajęli się trenowaniem sieci konwolucyjnych (CNN) i generatywnych sieci z adwersarzem (GAN), by te lepiej dobierały pozycje suwaczków. Innymi słowy – by obraz wejściowy przekształcić do stanu możliwie bliskiego „dobrej fotografii”. Możesz zobaczyć, jak funkcje takie implementuje Pixelmator Pro i inne edytory reklamujące się hasłem „Machine Learning”. Nietrudno zgadnąć, że efekty nie zawsze będą zgodne z oczekiwaniami. Zawsze jednak możesz sięgnąć do podlinkowanych poniżej materiałów i wytrenować własne sieci neuronowe, osiągając lepsze rezultaty. Albo i nie.
📝 Artykuły naukowe o ulepszaniu obrazów
📝 DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks
Nakładanie (stacking)
źródło 90% sukcesu fotografii mobilnej
Fotografia obliczeniowa zaczęła się od nakładania – metody łączenia serii obrazów w jeden (angielski termin „stacking” oznacza tu dosłownie „układanie jeden na drugim” i to właśnie będziemy mieć na myśli, gdy mowa o „nakładaniu”). Aparat smartfona może zrobić tuzin zdjęć w pół sekundy, bo nie ma w nim ruchomych części – przysłona jest stała zaś elektroniczna migawka reaguje natychmiast. To procesor decyduje, przez ile mikrosekund matryca ma rejestrować fotony.
Teoretycznie telefon mógłby robić zdjęcia z taką wydajnością, z jaką kręci klipy wideo (zaś wideo rejestrować z taką rozdzielczością, z jaką robi fotki), jednak w praktyce przepustowość szyny danych i procesora jest dalece niewystarczająca.
Technikę nakładania znamy od dawien dawna. Już starożytni mędrcy używali pluginów Photoshopa 7.0 do produkcji ostrych jak żyleta fotek HDR albo łączyli zdjęcia w panoramy rozmiaru 18000×600 pikseli i… nie do końca wiedzieli, co z nimi potem robić. To były piękne czasy.
Nazywamy tę technikę „fotografią epsilonową”, co oznacza modyfikowanie jednego z parametrów (ostrości, czasu ekspozycji, czułości matrycy) w serii zdjęć tak, by po ich połączeniu uzyskać efekt niemożliwy do osiągnięcia w pojedynczym ujęciu. Prostsza nazwa tego procesu to właśnie „nakładanie” (stacking) i bazuje na nim 90% innowacji w smartfonowych aparatach.

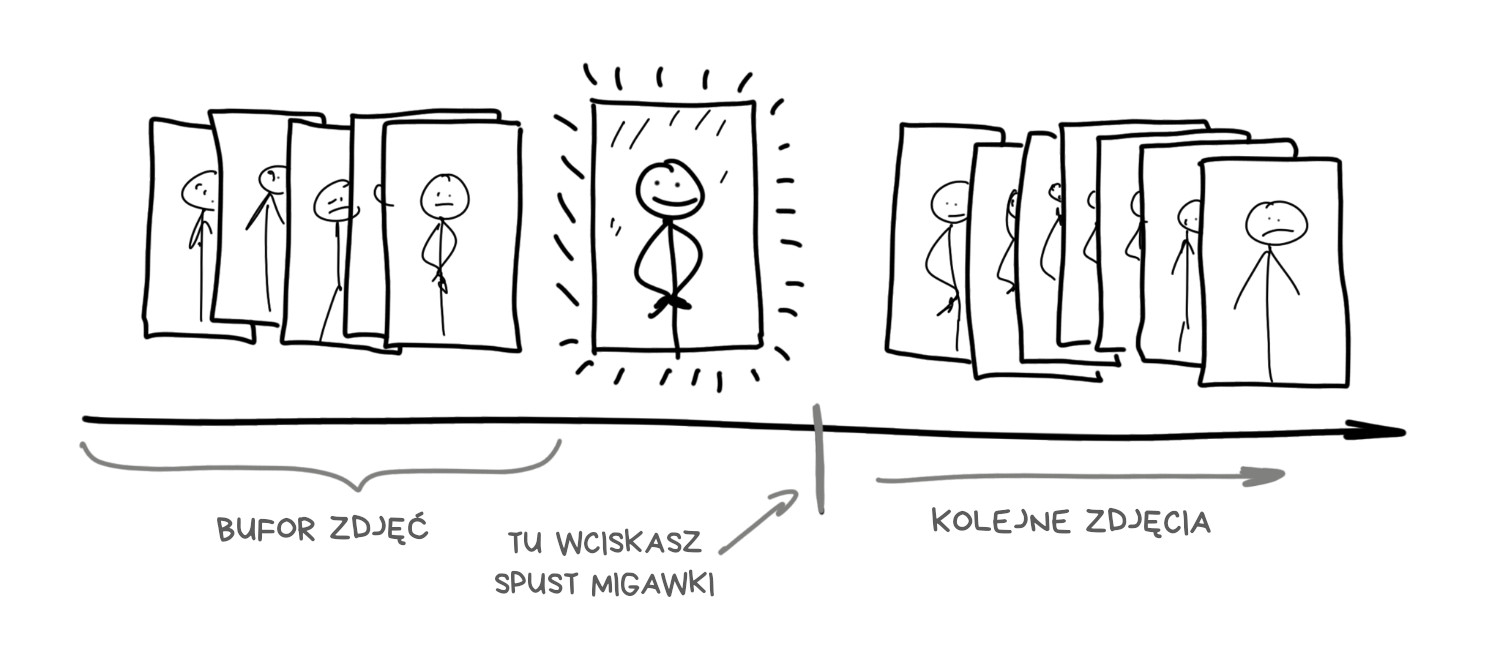
Oto fakt kluczowy dla mobilnej fotografii, choć nieznany większości użytkowników: nowoczesny smartfon zaczyna robić zdjęcia, gdy tylko uruchomisz aplikację aparatu. To logiczne, na ekranie widzisz przecież podgląd kadru. Jednocześnie jednak obrazy w wysokiej rozdzielczości trafiają do zapętlonego bufora i są tam przechowywane przez kilka sekund.
Gdy wciskasz przycisk spustu migawki, zdjęcie tak naprawdę zostało już zrobione, teraz jest tylko wyciągane z bufora.
Tak działa większość aparatów w smartfonach, przynajmniej tych lepszych. Buforowanie pozwala osiągnąć nie tylko zerowe, lecz wręcz ujemne opóźnienie migawki. Po wciśnięciu przycisku smartfon wyciąga 5-10 ostatnich ujęć z bufora i zaczyna je analizować oraz łączyć. Użytkownik nie musi czekać na wykonanie serii zdjęć do HDR czy ujęcia nocnego – potrzebne dane są dostępne od razu.
Tak działa np. Live Photo w iPhone’ach. Bliźniaczą funkcję w smartfonach HTC obdarzono w roku 2013 dziwną nazwą Zoe.
Nakładanie ekspozycji (exposure stacking)
HDR i kontrola jasności

Przedmiotem polemik jest, czy matryce w aparatach cyfrowych potrafią zarejestrować całe spektrum jasności odbierane przez ludzki wzrok. Niektórzy mówią, że nie, bo oko człowieka odróżnia obiekty których jasność różni się o 25 podziałek przysłony zaś nawet najlepsze matryce zatrzymują się na 14 podziałkach. Inni sugerują, że takie porównanie jest niewłaściwe, bo oczy wspomaga mózg sterujący średnicą źrenic i uzupełniający braki w postrzeganym obrazie – a sam zakres dynamiczny oka w danej chwili to nie więcej niż 10-14 podziałek przysłony. Ale zostawmy ten spór naukowcom.
Faktem pozostaje, że gdy sfotografujemy komórką sylwetki ludzkie na tle jasnego nieba bez HDR, to albo otrzymamy naturalne niebo i ciemne twarze, albo naturalny kolor twarzy i całkowicie prześwietlone niebo.
Rozwiązanie wymyślono dawno temu – rozszerzenie zakresu jasności przy użyciu techniki HDR (High Dynamic Range – wysoka rozpiętość tonalna). Gdy jedno ujęcie nie wystarczy do rejestracji pełnego zakresu, użyjemy trzech lub więcej. Jedna fotka będzie niedoświetlona, druga „normalna”, trzecia prześwietlona. Wówczas bardzo jasne obszary weźmiemy z pierwszego ujęcia zaś bardzo ciemne – z trzeciego.
Ostatnim problemem jest automatyczny bracketing, czyli określenie, jakie powinno być optymalne przesunięcie ekspozycji każdego z obrazów składowych. W dzisiejszych czasach rozwiązanie poda każdy student drugiego roku informatyki, pomagający sobie kilkoma bibliotekami Pythona.

Najnowsze modele iPhone, Pixela i Galaxy włączają HDR automatycznie, gdy algorytm wykryje zbyt dużą rozpiętość tonalną. Czasem możesz zobaczyć moment przełączenia trybu – płynność podglądu spada, zaś kolory stają się bardziej nasycone. Na moim iPhone X widać to za każdym razem. Przy najbliższej okazji sprawdź, jak jest w twoim smartfonie.

Główną wadą trybu HDR jest jego bezużyteczność przy słabym oświetleniu. Nawet w świetle lampy pokojowej obrazy są zbyt ciemne, by ich łączenie przynosiło jakąkolwiek korzyść. Aby rozwiązać ten problem, Google zastosowało w 2013 roku, w smartfonach serii Nexus, nowe podejście do HDR. Było to nakładanie temporalne.
Nakładanie temporalne (time stacking)
Długa ekspozycja i filmy poklatkowe

Nakładanie temporalne pozwala na osiągnięcie pozornie długich czasów ekspozycji przy użyciu serii obrazów o krótszej ekspozycji. Pionierami tej techniki byli ludzie fotografujący ruch gwiazd na tle nocnego nieba. Nawet ze statywem nie da się zrobić takich zdjęć, otwierając migawkę aparatu cyfrowego na bite dwie godziny – szumy matrycy zbytnio by się kumulowały. Rozwiązaniem było więc robienie każdej fotki z kilkudziesięciosekundową ekspozycją i ich późniejsze połączenie w Photoshopie.

Tak więc aparat nigdy nie robi zdjęć z naprawdę długą ekspozycją, symulujemy ten efekt nakładając serię kolejnych kadrów. Dawniej robiły to specjalne aplikacje, dziś taka funkcja prawie zawsze jest dostępna w standardowej apce do robienia zdjęć.

Wróćmy do Google i nocnego HDR. Okazuje się, że przy użyciu nakładania temporalnego da się osiągnąć przyzwoity HDR w ciemności. Technologia ta pojawiła się w 2013 roku w modelu Nexus 5 pod nazwą HDR+ i jest tak dobra, że pięć lat później nadal wyróżnia na rynku model Google Pixel 4 (który skądinąd doczekał się specjalnego trybu astrofotografii).
HDR+ jest nieskomplikowany – gdy kamera wykryje zdjęcie robione w mroku, wyciąga z bufora 8-15 surowych klatek i łączy je ze sobą. W ten sposób zbiera wystarczająco dużo informacji o ciemniejszych obszarach, by zminimalizować szum generowany przez piksele, które w poszczególnych ujęciach zostały pobudzone zbyt mocno lub zbyt słabo.
Wyobraź sobie, że nie wiesz, jak wygląda kapibara, i pytasz o nią pięcioro ludzi. Ich opowieści są podobne, ale każda wnosi jakiś unikalny szczegół, więc w sumie dowiesz się więcej, niż pytając jednej osoby. Tak samo jest z pikselami na zdjęciu – więcej informacji to czystszy i mniej zaszumiony obraz.
📝 HDR+: Low Light and High Dynamic Range photography in the Google Camera App
Łączenie obrazów zrobionych z tego samego miejsca daje sztuczny efekt wydłużonej ekspozycji, jak w przykładzie ze zdjęciem nieboskłonu. Błędy i artefakty pojedynczego obrazu są redukowane na podstawie informacji z pozostałych ujęć. Wyobraź sobie, ile trzeba by się napstrykać cyfrową lustrzanką, by osiągnąć taki sam efekt.

Do omówienia została tylko automatyczna korekcja kolorów. Zdjęcia robione w mroku mają zazwyczaj zaburzony balans bieli – dominuje żółć lub zieleń. We wcześniejszych wersjach HDR+ załatwiały to proste filtry tone-mapping, jak te z Instagrama. Potem z pomocą przyszły sieci neuronowe.
Tak narodził się Night Sight (Widzenie w Ciemności) – technologia „nocnego fotografowania” obecna w Pikselach 2, 3 i nowszych. Zgodnie z opisem „Night Sight dostosowuje kolory na zdjęciu z użyciem uczenia maszynowego, by nawet na zdjęciach nocnych pokazać naturalną kolorystykę”. Tak naprawdę do opisanych już mechanizmów HDR+ dołącza sieć neuronowa, którą trenowano na zestawach ujęć przed i po korekcji – dzięki niej obraz o zaburzonej kolorystyce zostaje przerobiony na piękne zdjęcie wynikowe.

Night Sight kontroluje też przesunięcia kadru, by zidentyfikować nieostrości, których trudno uniknąć przy długim czasie ekspozycji. Dzięki temu do łączenia trafią tylko ostre obszary klatek składowych. Ciekawostka – zbiór zdjęć, na których trenowano sieć neuronową Night Sight, jest dostępny publicznie.
📝 Night Sight: Seeing in the Dark on Pixel Phones
📝 Introducing the HDR+ Burst Photography Dataset
Nakładanie z przesunięciem (motion stacking)
Panoramy, superzoom i kontrola zaszumienia

Fotografie panoramiczne zawsze były niepoważne. Historia nie zna ani jednego przykładu kiszkowatego zdjęcia, które byłoby interesujące dla kogokolwiek poza autorem. To jednak właśnie tą drogą nakładanie z przesunięciem trafiło do naszego życia.

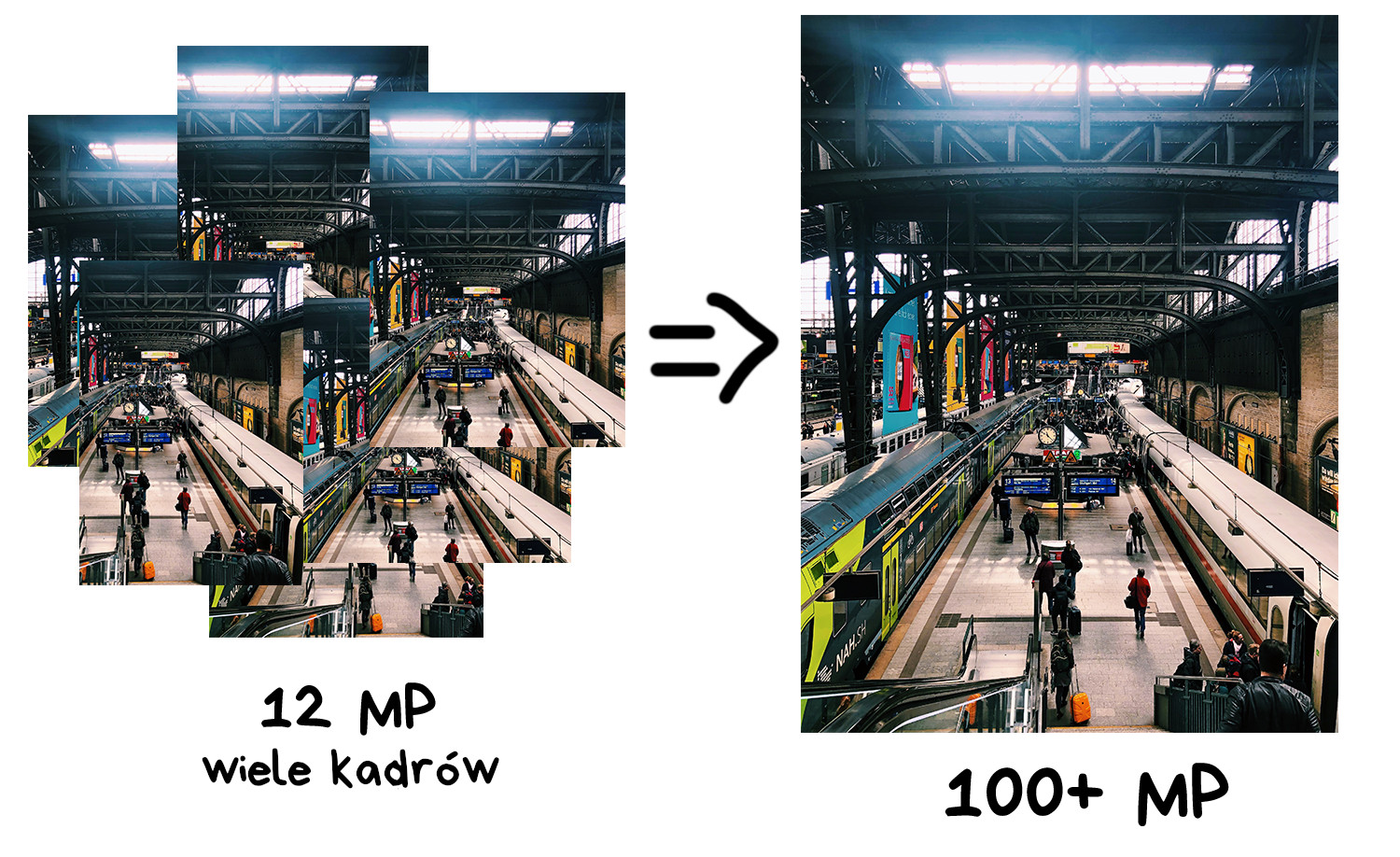
Użytecznym zastosowaniem takiego kadrowania jest tworzenie obrazów o wielkiej rozdzielczości. Dzięki łączeniu wielu kadrów przesuniętych względem siebie otrzymujemy ujęcie o rozdzielczości znacznie wyższej niż możliwości aparatu. W ten sposób da się tworzyć obrazy o rozdzielczości setek gigapikseli, przydatne np. do druku wielkoformatowych billboardów.
📝 A Practical Guide to Creating Superresolution Photos with Photoshop
Innym, ciekawszym zastosowaniem nakładania z przesunięciem są przesunięcia pikselowe (Pixel Shifting). Niektóre bezlusterkowe aparaty Sony czy Olympus zaczęły oferować tę technologię już w roku 2014, ale składowe obrazy trzeba było łączyć samodzielnie. Poziom innowacji typowy dla lustrzanek.
Smartfony wygrały tu z zabawnego powodu – podczas robienia zdjęcia twoje ręce drżą. To, co normalnie jest problemem, tym razem pozwala wdrożyć technologię podnoszącą rozdzielczość zdjęć ponad rozdzielczość matrycy obecnej w urządzeniu.
Przypomnijmy sobie, jak działa sensor w aparacie cyfrowym. Każdy piksel (fotodioda) mierzy natężenie światła, proporcjonalne do liczby fotonów, które w niego uderzyły. Sensor nie rejestruje jednak koloru (długości fali). Aby otrzymać kolorowy obraz RGB, musimy zakryć matrycę siatką kolorowych filtrów. Najpopularniejszy układ to filtr Bayera, używany w większości dzisiejszych matryc.
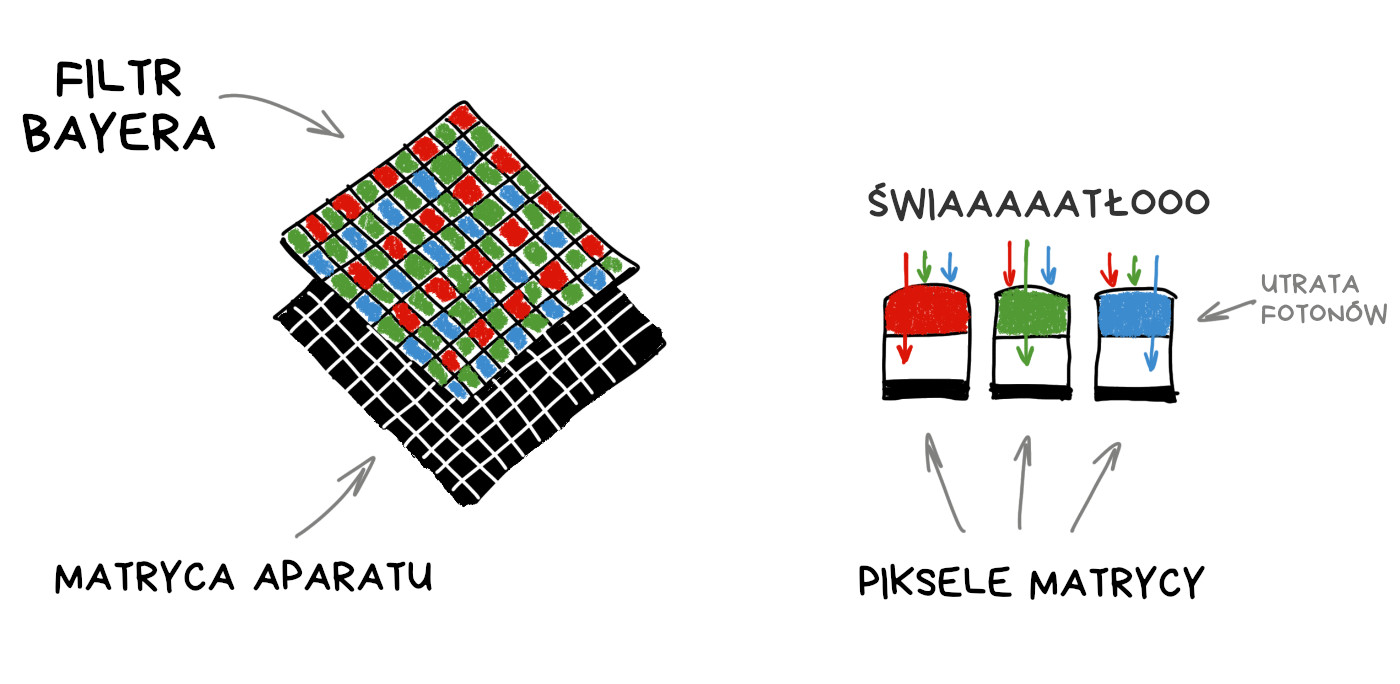
W efekcie każdy z pikseli rejestruje tylko natężenie jednej ze składowych R, G lub B – pozostałe eliminuje filtr Bayera. Brakujące wartości uzupełniane są z uśrednionych pomiarów sąsiednich pikseli danej barwy.

Podobnie jak ludzie oko, filtr Bayera reaguje najbardziej na kolor zielony. Spośród przykładowych 50 milionów pikseli na jednej matrycy, aż 25 milionów będzie wyposażonych w filtr zielony, a na kolory niebieski i czerwony przypada po 12.5 miliona pikseli. Cała reszta jest uśredniana podczas procesu zwanego demozaikowaniem.
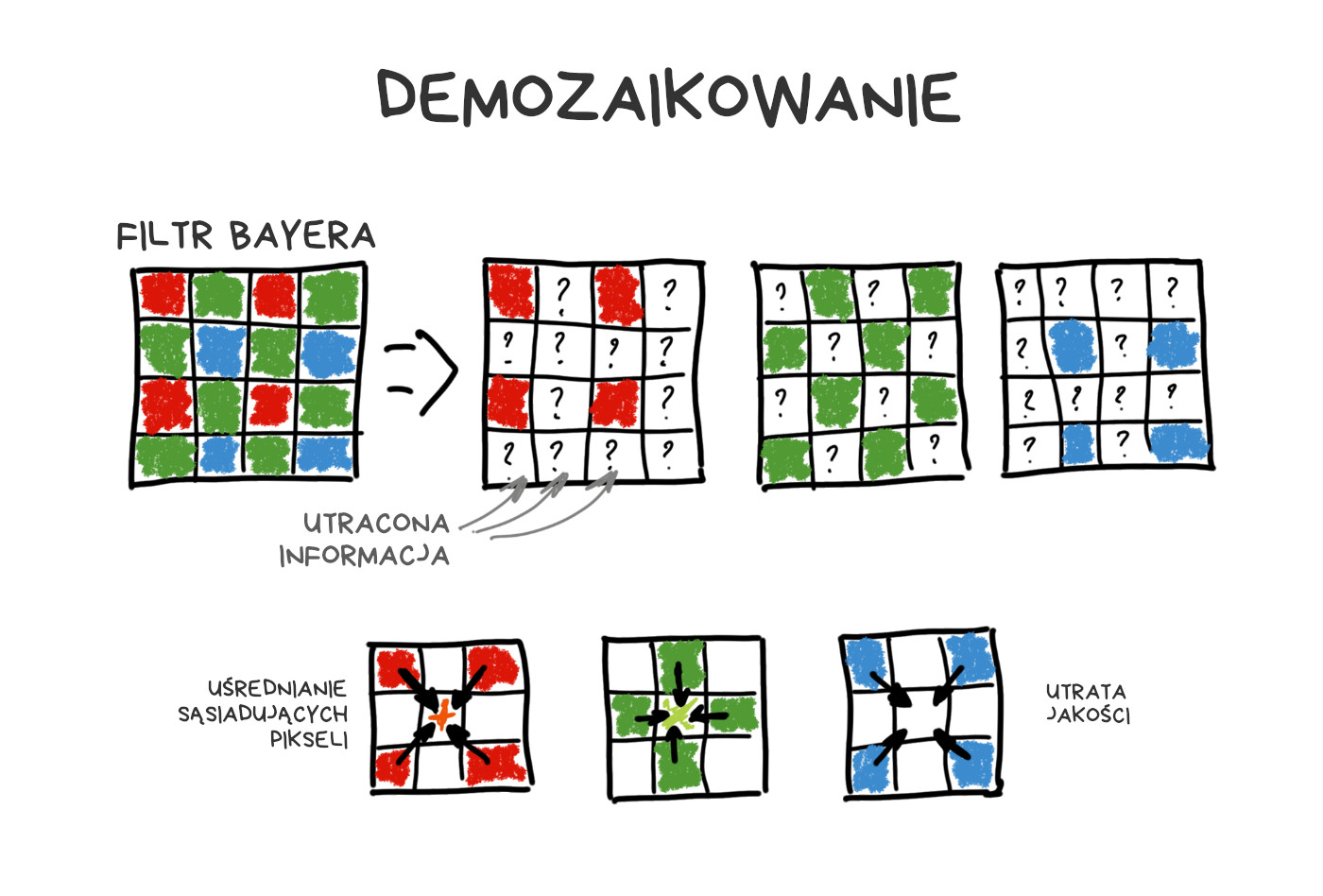
Inne rodzaje sensorów (jak Foveon) nie zyskały popularności. Niektórzy producenci smartfonów próbowali używać filtrów innych niż Bayera, by zwiększyć ostrość lub zakres dynamiczny zdjęć. Zazwyczaj bez powodzenia.
Filtr Bayera zatrzymuje całe mnóstwo fotonów, które w efekcie nie docierają do matrycy. Tu pojawia się pomysł na przesunięcia pikselowe – poruszenie matrycy o jeden piksel w osi góra-dół oraz lewo-prawo, by dla każdego punktu obrazu zebrać komplet wartości RGB. Obraz nie będzie przez to cztery razy większy, za to algorytm demozaikowania dostanie na wejściu bardziej kompletne dane.
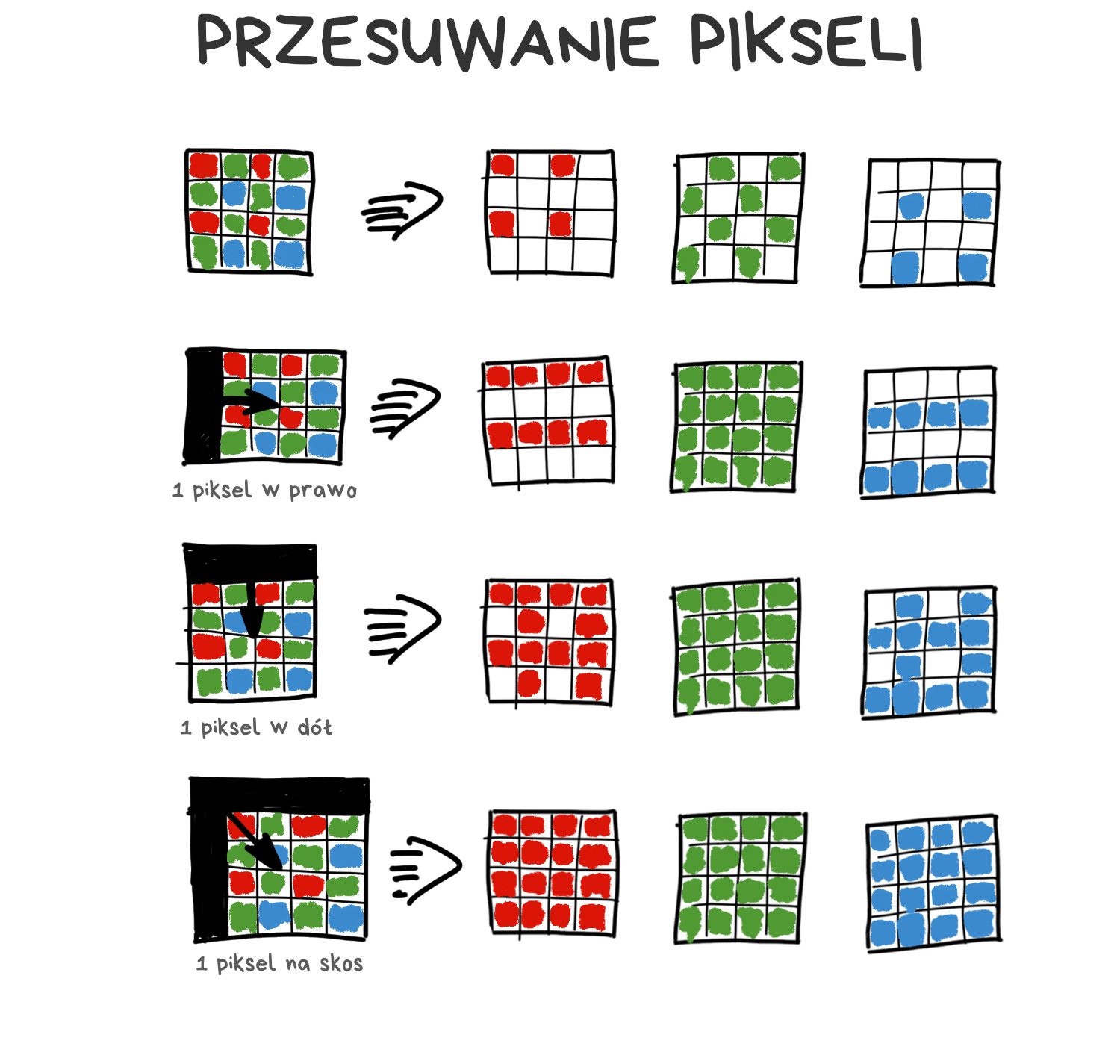

Dzięki drżeniu rąk przesunięcia pikselowe są czymś normalnym w fotografii mobilnej. Technologii tej – nazwanej Super Res Zoom – używają nowsze modele Google Pixel. Możesz obserwować ją w akcji, gdy mocno powiększysz kadr w swoim telefonie. Technologia ta została już skopiowana przez chińskich producentów telefonów, choć działa w nich gorzej niż w oryginale.
📝SIGGRAPH 2019: Handheld Multi-frame Super-resolution
📝See Better and Further with Super Res Zoom on the Pixel 3
Nakładanie nieznacznie przesuniętych obrazów pozwala na zebranie większej ilości informacji o każdym punkcie obrazu, co eliminuje szum, wyostrza zdjęcie i podnosi jego efektywną rozdzielczość. Współczesne telefony z Androidem robią to automatycznie, zazwyczaj bez wiedzy użytkowników.
Nakładanie ogniskowych (focus stacking)
Przeogniskowanie w postprodukcji

Ta metoda wywodzi się z makrofotografii, gdzie mała głębia ostrości zawsze była problemem. Aby cały fotografowany obiekt był ostry, konieczne jest zrobienie serii zdjęć z odmiennymi nastawami ostrości i późniejsze połączenie ich w jedno ostre ujęcie w Photoshopie. Tej samej metody używa się do zdjęć krajobrazowych, gdzie ostre są jednocześnie wszystkie plany.

Technika trafiła do smartfonów, a jakże, tym razem jednak bez wielkiego hałasu. Nokia wyprodukowała Lumię 1020 z aplikacją „Refocus App” w roku 2013, w Samsungu Galaxy S5 z roku 2014 funkcja ta nosiła nazwę „Selective Focus”. W obu przypadkach chodziło o to samo – aparat robił szybko trzy zdjęcia, jedno z właściwą ostrością i dwa z ostrością przesuniętą w tył i w przód. Użytkownik mógł następnie wskazać najlepsze ujęcie.
Mimo braku zaawansowanego przetwarzania ten prosty trick stanowił kolejny gwóźdź do trumny aparatu Lytro i innych rozwiązań pozwalających na rzeczywisty wybór ostrości po wykonaniu ujęcia. Omówimy je teraz po kolei (mistrzowska zmiana tematu, nieprawdaż?).
Matryce obliczeniowe
Plenoptyka i pole świetlne
Matryce w aparatach są do dupy. Przyzwyczailiśmy się do tego i próbujemy z nich wycisnąć, ile się da. Zasada działania nie zmieniła się jednak od zarania dziejów. Ulepszamy jedynie proces produkcyjny – pakujemy piksele gęściej, zmniejszamy szum, dodajemy elementy służące fazowemu autofocusowi itd. Wciąż jednak nawet najdroższy aparat przegra z biegnącym kotem, którego próbujemy sfotografować przy sztucznym świetle.

🎥 The Science of Camera Sensors
Przez długi czas próbowaliśmy wymyślić lepsze matryce. Możesz znaleźć wyniki tych badań, wrzucając w Google hasła „computational sensor” czy „non-Bayer sensor”. Przesunięcia pikselowe też można uznać za próbę ulepszania matrycy przy pomocy technik obliczeniowych.
Największy potencjał w ciągu ostatnich dwudziestu lat zdawały się jednak mieć aparaty plenoptyczne. Zamiast nudnej matematyki ciekawostka: kamery w nowszych Pikselach grupują po dwa piksele w jednym klastrze – to wystarcza, by obliczyć rzeczywisty rozkład głębi obrazu bez używania drugiej kamery, jak to robią wszyscy inni.
Plenoptyka to potężna broń, która jeszcze nie wypaliła.
Aparat plenoptyczny

Wymyślony w roku 1994. Pierwszy raz skonstruowany na Uniwersytecie Stanforda w roku 2004. Pierwszy produkt na rynku konsumenckim – Lytro z roku 2012. Z podobnymi technologiami eksperymentuje branża VR.
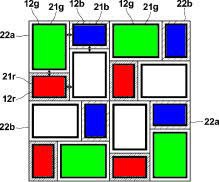
Aparat plenoptyczny różni się od klasycznego jednym szczegółem: sensor pokryty jest siatką soczewek, z których każda przykrywa od kilku do kilkudziesięciu pikseli. Wygląda to jakoś tak:
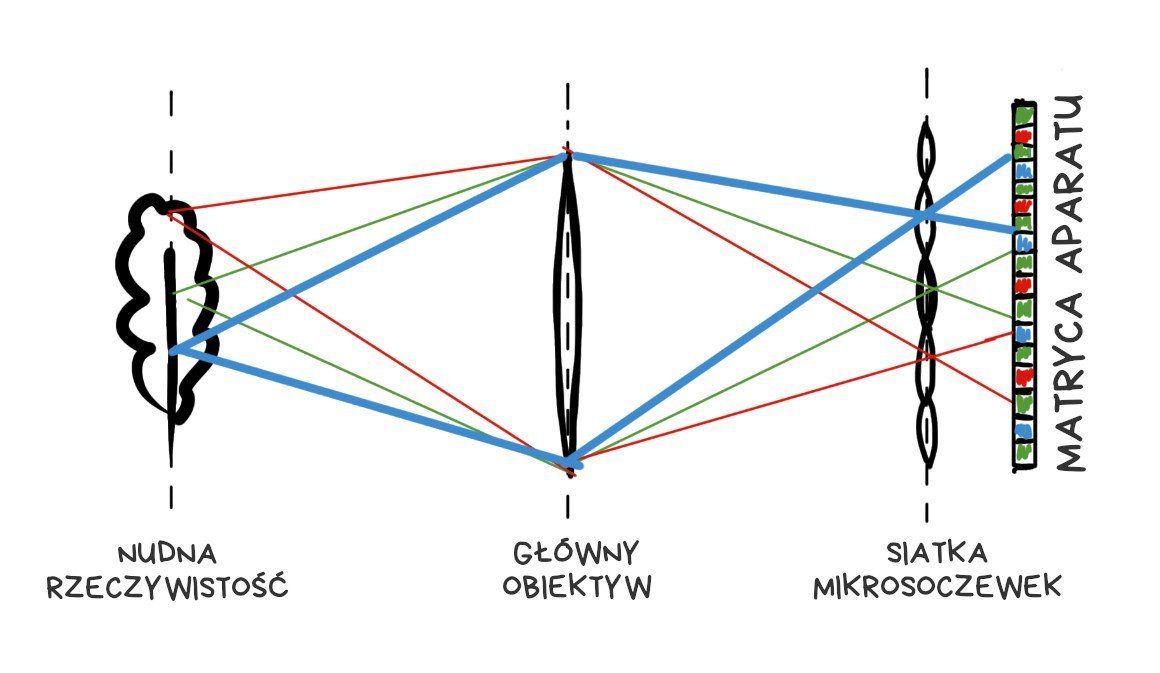
Jeśli soczewki i sensor będą odpowiednio zestrojone, na matrycy zobaczymy zestaw mini-obrazów odwzorowujących fragmenty docelowej fotografii.

🎥 Muted video showing RAW editing process
Gdy z każdego miniobrazu (klastra) weźmiemy tylko środkowy piksel, wynikowy obraz nie będzie się różnił od zdjęcia ze zwykłego aparatu. Owszem, rozdzielczość będzie niższa, ale zawsze możemy poprosić Sony o gęstsze upakowanie pikseli w następnej wersji matrycy.
Prawdziwa zabawa zaczyna się teraz – jeśli z każdego klastra weźmiemy po innym pikselu (np. sąsiadującym z pikselem środkowym) i złożymy obraz z takiego zestawu, w efekcie dostaniemy obraz, który powstałby po nieznacznym przesunięciu klasycznej matrycy. Jeśli pod każdą soczewką mamy siatkę 10×10 pikseli, możemy wygenerować 100 obrazów, każdy odpowiadający fotografii zrobionej z odrobinę innego miejsca.
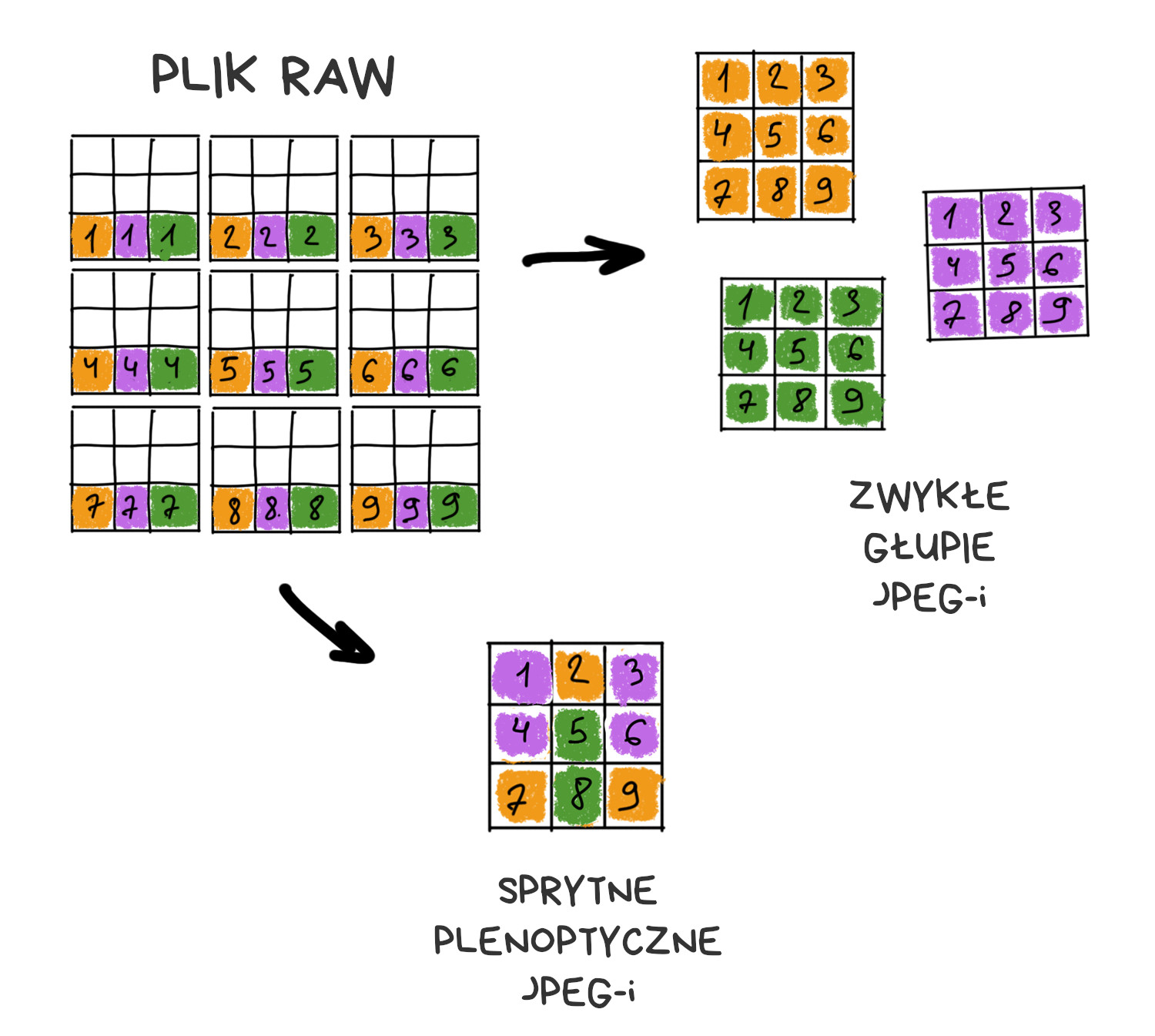
Im większy rozmiar klastra, tym więcej obrazów uzyskamy – oczywiście kosztem rozdzielczości. Gdy matryce w smartfonach mają nawet 48 megapikseli, mamy co poświęcać, niemniej konieczne jest zachowanie zdrowej równowagi.
📝 plenoptic.info – about plenoptics, with python code samples
Wiemy już, jak działa aparat plenoptyczny. Co możemy zrobić z jego pomocą?
Prawdziwe przeogniskowanie
O tej funkcji wspominały wszystkie artykuły opisujące aparat Lytro: w pochodzących z niego zdjęciach płaszczyznę ostrości można regulować po wykonaniu ujęcia. Pisząc o „prawdziwej” regulacji ostrości, mamy na myśli nie algorytmy wyostrzające, lecz generowanie obrazu na bazie odpowiednio dobranych pikseli z surowego zapisu pochodzącego z matrycy.

Surowy zapis (RAW) z kamery plenoptycznej wygląda dziwacznie. Aby uzyskać zwykłe zdjęcie, należy najpierw odpowiednio wybrać z niego piksele źródłowe.
Im bardziej soczewka odchyla promień odwzorowujący dany detal od centralnego piksela w klastrze, tym bardziej „nieostre” odwzorowanie rejestruje ów klaster. Aby przywrócić temu detalowi ostrość, musimy sięgnąć po piksele pochodzące z klastrów, które rejestrowały ów detal w centrum klastra.

Ten obrazek należy czytać od prawej do lewej, bo tak naprawdę generujemy docelową fotografię z zapisu już zarejestrowanych pikseli. Na górnym obrazku widzimy, jak odzyskać ostry obraz danego detalu. Na dolnym obrazku – jak przesunąć płaszczyznę ostrości za ten detal. Zmieniając sposób obliczeń – zmieniamy ostrość na obrazie wynikowym.
Proces przesuwania płaszczyzny ostrości przed dany detal jest nieco bardziej skomplikowany, bo informacje o nim zbiera mniejsza liczba klastrów. Na początku twórcy Lytro nie dawali użytkownikom takiej możliwości. Funkcja taka pojawiła się pod nazwą „tryb kreatywny” w późniejszym okresie.
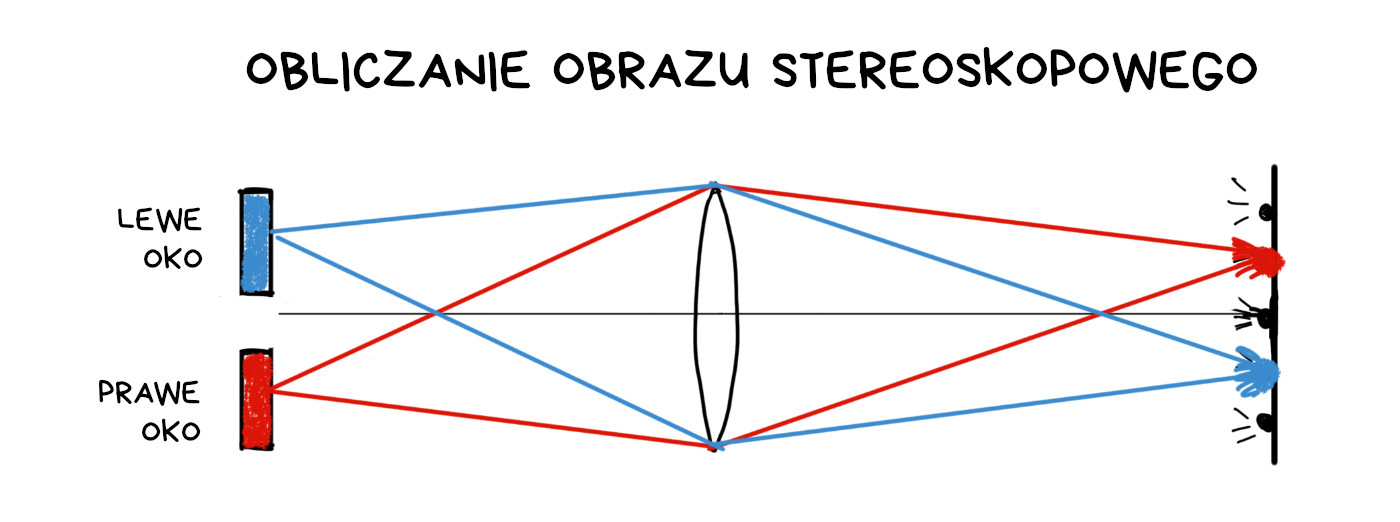
Mapowanie głębi obrazu i 3D z pojedynczego obiektywu
Jedną z prostszych operacji w aparacie plenoptycznym jest wyliczenie mapy głębi obrazu, czyli określenie, jak daleko od obiektywu znajdowały się poszczególne obszary i obiekty. W tym celu bierzemy dwa różne obrazy (z różnych pikseli w klastrze) i sprawdzamy, jakim przesunięciom te obiekty podlegały. Większe przesunięcie odpowiada większemu oddaleniu.
Google kupiło firmę Lytro, zabiło jej produkty, lecz używa przejętej technologii w zastosowaniach VR i… aparatach Pixela. Począwszy od wersji 2, kamery Pixela są „troszkę” plenoptyczne, z dwoma pikselami na klaster. Dzięki temu mapę głębi można wyliczyć z pojedynczego zdjęcia pochodzącego z jednego obiektywu.


📝 Portrait mode on the Pixel 2 and Pixel 2 XL smartphones
Mapa głębi powstaje na bazie dwóch zdjęć przesuniętych o jeden piksel. To wystarcza, by odseparować pierwszy plan od tła i nałożyć na tło sztuczne rozmycie ostrości. Separacja jest wygładzana i „poprawiana” przez sieć neuronową.
Plenoptykę dostaliśmy w smartfonach prawie gratis – już wcześniej montowaliśmy nad pojedynczymi pikselami soczewki, by zwiększyć ilość światła docierającego do każdej fotodiody. W następnych Pixelach Google planuje pójść krok dalej i przykrywać jedną soczewką nie dwa, a cztery piksele.
Wycinanie warstw i obiektów
Nie widzisz swojego nosa, bo twój mózg łączy obraz z obu oczu. Zamknij jedno oko, a nagle zobaczysz w polu widzenia wielką piramidę.
Taki sam efekt możemy osiągnąć dzięki aparatowi plenoptycznemu. Łącząc obrazy z różnych części klastrów, możemy widzieć obiekty tak, jakbyśmy patrzyli na nie z różnych miejsc (tak, jak nasze oczy). Otwiera nam to dwie możliwości. Po pierwsze możemy oszacować odległość do obiektów i wyciąć bliższe obiekty z tła. Po drugie – jeśli obiekt jest niewielki, możemy go całkiem wyeliminować z obrazu wynikowego. Bez Photoshopa, wyłącznie na bazie danych optycznych.
Dzięki temu możemy wyciąć z kadru siatkę ogrodzeniową albo usunąć konfetti, jak w przykładzie poniżej.

„Optyczna” stabilizacja bez optyki stabilizującej
Plik RAW z aparatu plenoptycznego może posłużyć do wygenerowania dziesiątek obrazów przesuniętych o kilka pikseli w obu osiach. Jeśli weźmiemy dwa pliki RAW ze zdjęciami zrobionymi jedno po drugim, możemy skompensować ewentualne przesunięcia w dwóch obrazach docelowych – wystarczy tak dobrać generowane obrazy, by pokryły dokładnie taki sam kadr. Możemy więc „stabilizować” klatki przeznaczone do nakładania nawet wtedy, gdy obiektyw ani matryca nie są wyposażone w mechaniczną stabilizację obrazu.
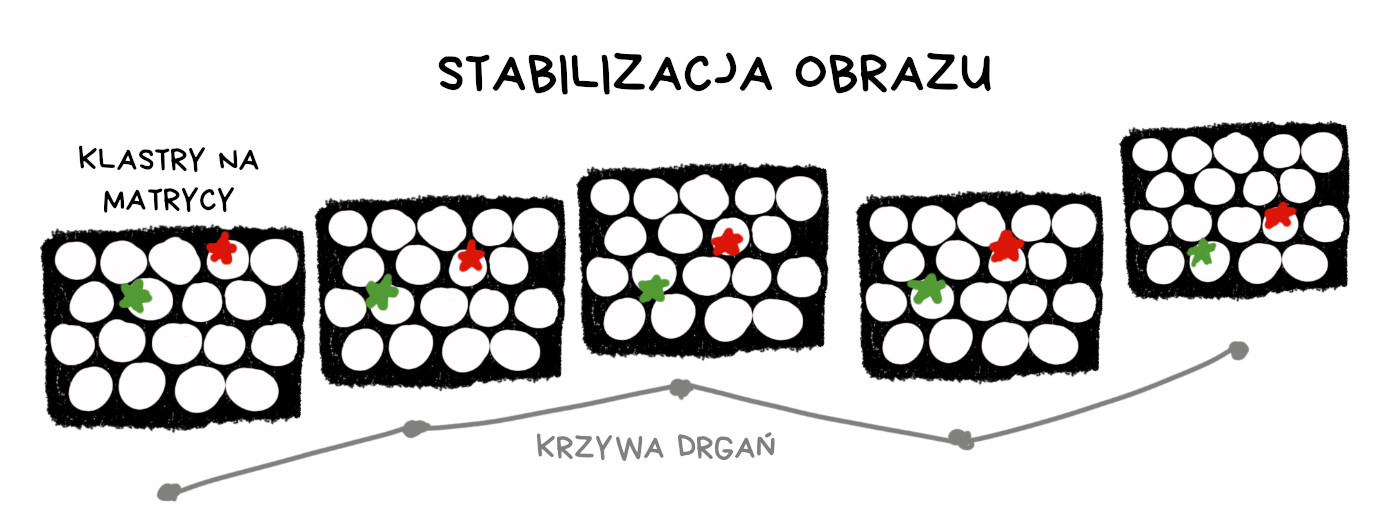
Ściśle rzecz biorąc, to nadal stabilizacja optyczna, bo niczego tu nie obliczamy – wykorzystujemy tylko piksele z odpowiednich pozycji klastra. Trzeba pamiętać, że aparat plenoptyczny poświęcił megapiksele na rzecz innych korzyści, o ile więc opisana możliwość stabilizowania obrazu jest miłym dodatkiem, to ceną, jaką wciąż płacimy jest znacznie niższa rozdzielczość obrazu wynikowego.
Walka z filtrem Bayera
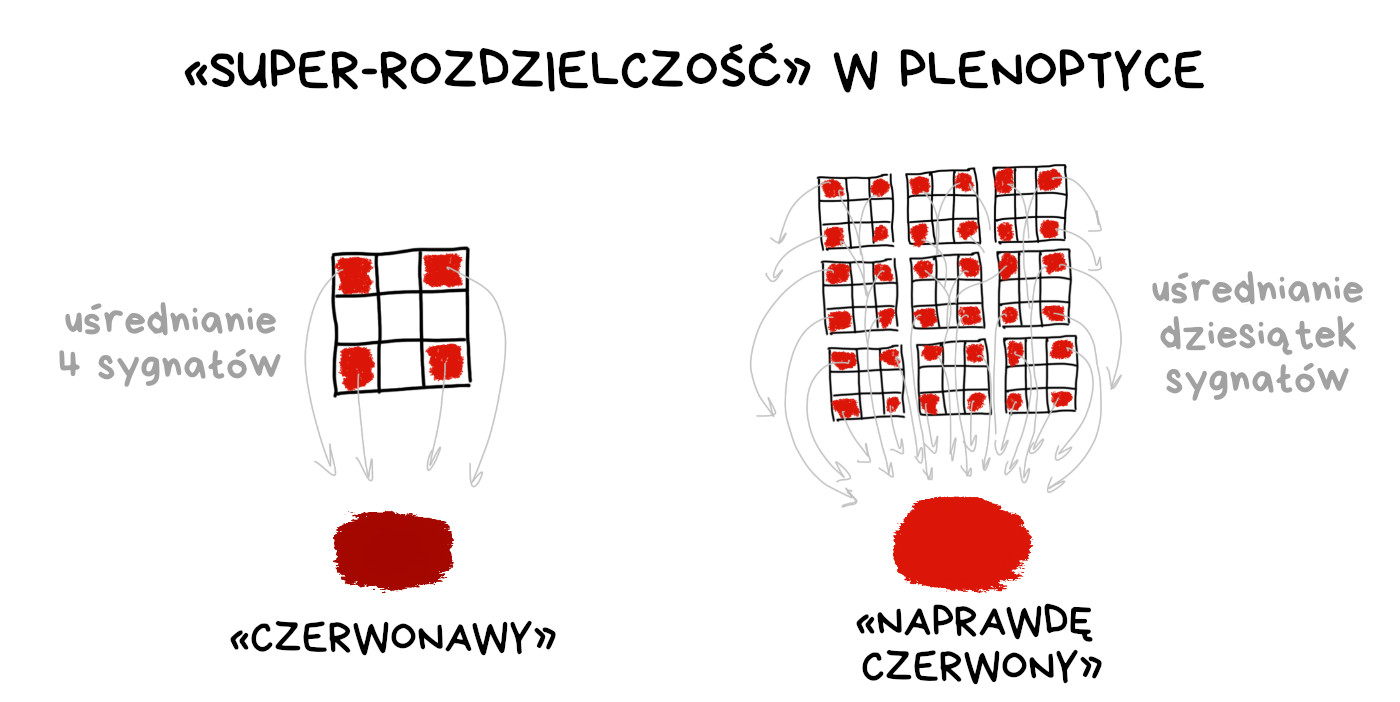
W aparatach plenoptycznych nadal potrzebujemy kolorowych filtrów na pikselach matrycy. Nie mamy żadnego innego sposobu na rejestrację cyfrowego obrazu w kolorze. W surowym zapisie obrazu z kamery plenoptycznej możemy uśredniać brakujące informacje o kolorach nie tylko z sąsiednich pikseli, jak w klasycznym demozaikowaniu, lecz także z kopii tego samego fragmentu obrazu w innych klastrach.
W niektórych tekstach jest to określane jako „superrozdzielczość obliczeniowa” ale ja pozostaję sceptyczny. W układzie plenoptycznym obniżyliśmy przecież rzeczywistą rozdzielczość matrycy dziesiątki razy, by teraz z dumą część tego odzyskać. Ciężko takie coś sprzedać jako rzeczywistą zaletę.
Od strony technicznej jest to oczywiście ciekawsze niż prostackie przesunięcia pikselowe.
Przysłona obliczeniowa (bokeh)

Wszyscy, którzy lubią bokeh w kształcie serca, będą wniebowzięci. W aparacie plenoptycznym mamy kontrolę nad płaszczyzną ostrości, możemy do końcowego obrazu wybierać część pikseli tworzących obraz rozmyty, a część – obraz ostry. Możemy więc symulować przysłonę o dowolnym kształcie bez używania nasadek na obiektyw. Hura!
Plenoptyka w zastosowaniach wideo
Pozostajemy przy temacie fotografowania, jednak wszyscy zainteresowani kręceniem filmów powinni zerknąć na link poniżej. Znajdziecie tam pół tuzina innych interesujących zastosowań optyki plenoptycznej.
🎥 Watch Lytro Change Cinematography Forever
Pole świetlne
Więcej niż fotografia, mniej niż VR
Zazwyczaj objaśnianie zasady działania aparatów plenoptycznych zaczyna się od omówienia koncepcji pola świetlnego. Z naukowego punktu widzenia kamera plenoptyczna rejestruje właśnie pole świetlne, nie samą tylko fotografię. „Plenus” oznacza po łacinie „pełny, kompletny” – tak jak np. sesja plenarna. Tu jednak chodzi nam o zbieranie pełnej informacji o promieniach światła.
Zacznijmy od tego, co to jest pole świetlne i do czego będzie nam potrzebne.
Tradycyjna fotografia jest dwuwymiarowa. Tam, gdzie promień światła trafił w matrycę, rejestrujemy jasny piksel. Aparatu nie obchodzi, czy promień ten wpadł gdzieś przypadkiem z boku, czy odbił się od krągłości fotografowanej modelki. Rejestrowane są tylko współrzędne miejsca przecięcia promienia z powierzchnią sensora.
Pole świetlne zbiera więcej informacji – do wspomnianych współrzędnych dochodzi jeszcze informacja, skąd przybył dany promień. Efektywnie rejestrujemy więc wektor w przestrzeni trójwymiarowej. Coś, jak obliczanie oświetlenia w grze 3D, tylko w drugą stronę – staramy się zarejestrować scenę, a nie ją wygenerować. Pole świetlne składa się ze wszystkich promieni świetlnych w naszym kadrze, tak pochodzących ze źródeł światła, jak i odbitych.
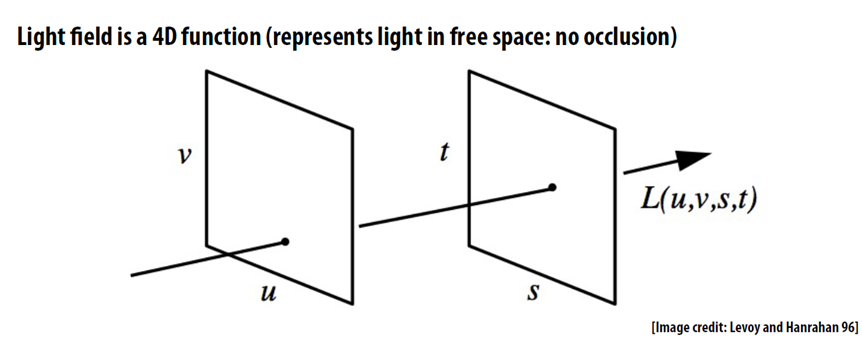
Pole świetlne to wizualny model pewnego wycinka przestrzeni. Jesteśmy w stanie obliczyć dowolne ujęcie wewnątrz tego obszaru. Punkt widzenia, głębia ostrości, przysłona – wszystko daje się wyliczyć.
Jako analogii można użyć miejskiej siatki ulic. Fotografia jest jak znana ci dobrze trasa z domu do knajpy. Pole świetlne jest jak mapa całego miasta. Używając mapy, możesz wyznaczyć trasę między dwoma dowolnymi punktami, zaś używając pola świetlnego, możesz wyliczyć dowolną fotografię.
Do robienia zwykłych zdjęć to oczywiście o wiele za dużo, ale w tym miejscu wchodzi VR – wirtualna rzeczywistość – gdzie pola świetlne mają przed sobą świetlaną (hehe) przyszłość.
Znajomość pola świetlnego obiektu lub pomieszczenia pozwala oglądać ów obiekt lub pomieszczenie z dowolnej perspektywy. Nie trzeba budować trójwymiarowego modelu pokoju, by zasymulować widok wnętrza, wystarczy „po prostu” zarejestrować wszystkie promienie światła wewnątrz i wyliczyć z nich potrzebne obrazy. Po prostu, taaaaa. O to w tej chwili walczymy.
📝 Google AR and VR: Experimenting with Light Fields

Optyka obliczeniowa
Gdy mówimy o optyce, mamy na myśli to, co goście z Uniwersytetu Stanforda – czyli nie tylko soczewki, ale wszystko, co znajduje się między obiektem a matrycą. Także przysłonę i migawkę. Jeśli to dla ciebie nie są elementy optyczne, masz pecha.
Wiele aparatów naraz

W roku 2014 firma HTC wypuściła na rynek model One (M8), który był pierwszym smartfonem z dwoma aparatami. Udostępniał on wiele funkcji realizowanych przez fotografię obliczeniową, jak rozmywanie tła czy dodawanie do zdjęć symulowanego opadu deszczu.
Wyścig się rozpoczął. Wszyscy producenci smartfonów zaczęli umieszczać w swoich urządzeniach dwa, trzy lub cztery aparaty, kłócąc się, czy bardziej przydatne są obiektywy wąsko- czy szerokokątne. Na końcu tej ścieżki był Light L16, aparat wyposażony w szesnaście obiektywów.

L16 to nie smartfon, tylko nowy rodzaj aparatu kompaktowego. Obiecywał jakość porównywalną z pełnoklatkowymi lustrzankami o jasnych obiektywach przy wymiarach pozwalających schować go do kieszeni. Zalety te miały wynikać z możliwości, jakie stwarza fotografia obliczeniowa.

Na szesnaście obiektywów składało się: pięć szerokokątnych o ogniskowej 28 mm, pięć o ogniskowej 70 mm oraz sześć długoogniskowych 150 mm. Każdy teleobiektyw miał układ peryskopowy, z lusterkiem pozwalającym zmieścić długi układ optyczny w płaskiej obudowie. Takie rozwiązanie pojawia się coraz częściej w smartfonach.
Każde ujęcie było rejestrowane przez 10 lub więcej obiektywów, zaś aparat łączył je w jedną 52-megapikselową fotografię. Według twórców tego rozwiązania jednoczesna rejestracja obrazu przez wiele matryc pozwalała na złapanie tej samej ilości światła, jaka pada w lustrzance na dużą matrycę przez duży obiektyw.
Oprogramowanie pozwalało na regulację głębi oraz płaszczyzny ostrości po wykonaniu ujęcia. Było to możliwe dzięki temu, że każdy obiektyw miał nieco inną perspektywę, więc aparat mógł odróżnić obiekty na różnym planie. Na papierze wygląda to nieźle i przed premierą wszyscy mieli spore nadzieje związane z tą technologią.
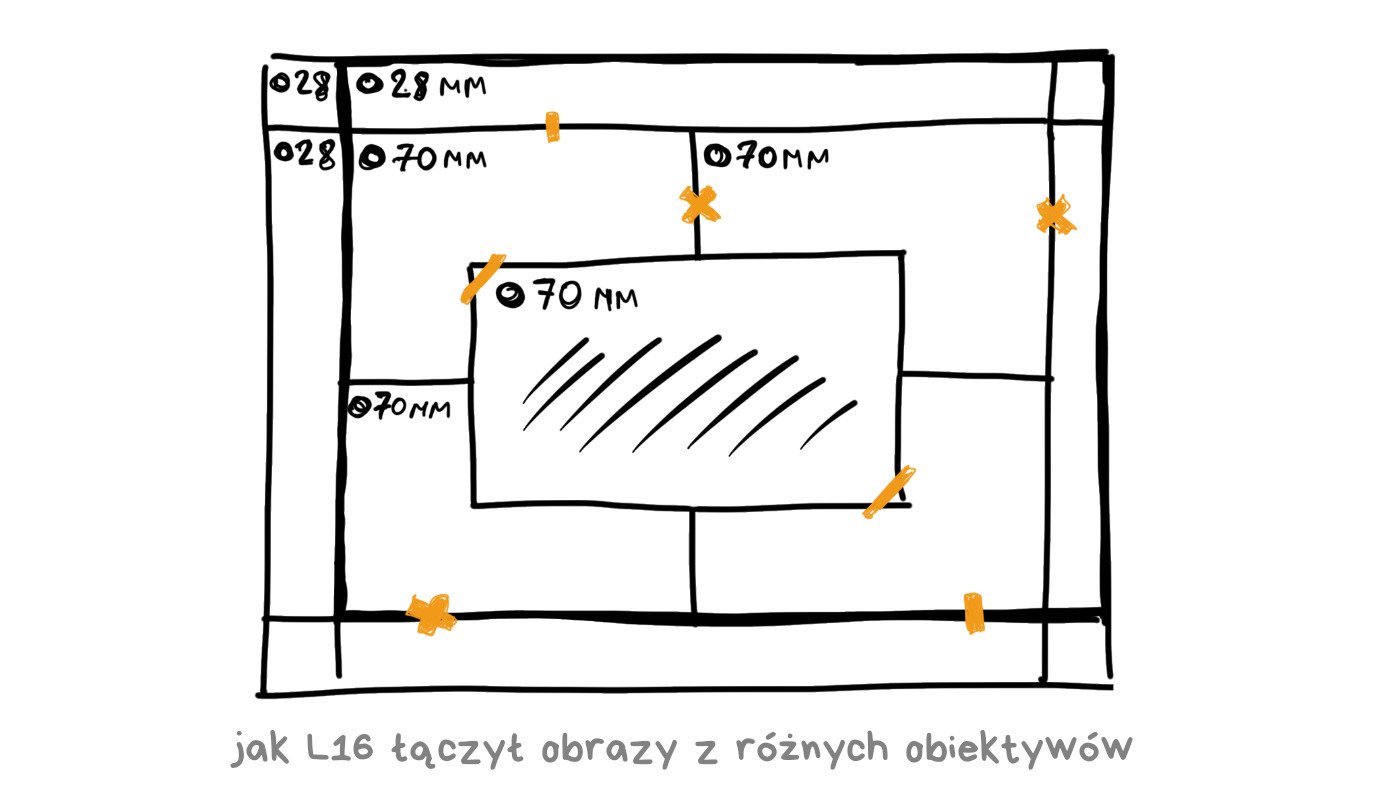
W marcu 2018 Light L16 trafił do sklepów i… zaliczył wielką klapę. Owszem, technologia pochodziła z przyszłości, ale mimo ceny wynoszącej 2000 USD zabrakło optycznej stabilizacji matryc (zdjęcia zawsze wychodziły rozmyte, to w końcu 70-150 mm ogniskowej), autofokus był powolny, zdjęcia powstałe z połączenia kilku klatek miały niejednorodną ostrość, zaś przy słabym oświetleniu nie dało się fotografować (zabrakło takich technologii jak HDR+ czy Night Sight). Nowoczesne kompakty za 500 USD obsługujące zapis RAW potrafiły to wszystko, więc sprzedaż L16 szybko zakończono.
Firma Light nadal istnieje. Zebrała kolejną rundę finansowania i prowadzi badania, których efekty sprzedaje innym firmom. Technologie Light można znaleźć m.in. w aparacie Nokia 9 (koszmarze trypofobów), w opracowaniu są też urządzenia do określania pozycji autonomicznych samochodów.
🎥 Light L16 Review: Optical Insanity
Kodowana przysłona
Wyostrzanie obrazu i mapowanie głębi
Zbliżamy się teraz do rejonów związanych z teleskopami i promieniami Roentgena. Nie zanurzymy się zbyt głęboko, ale i tak zapnijcie pasy. Historia kodowanej przysłony zaczyna się tam, gdzie nie da się skupić wiązki promieni – mowa o promieniowaniu gamma i rentgenowskim. Jeśli nie wiesz, czemu tak jest, spytaj nauczyciela fizyki.
Kodowana przysłona zastępuje owalny otwór tworzony w obiektywie przez metalowe lamelki. Zamiast nich stosuje się płytkę z licznymi nieregularnymi otworami różnych kształtów, ułożonymi tak, by ich obraz różnił się w zależności od stopnia rozogniskowania. Astronomowie wymyślili całą paletę wzorów używanych w teleskopach, poniżej widzimy jeden z najbardziej typowych.

Jak to działa?
Gdy ustawimy pierścień ostrości, wszystko, co leży poza obraną płaszczyzną ostrości, będzie mniej lub bardziej rozmyte. Rozmycie ma miejsce wtedy, gdy jeden promień światła jest rozpraszany na wiele pikseli matrycy. Rezultatem jest bokeh, np. żarówka zamiast jasnego punktu staje się świecącym owalem.
Matematycy opisują to zjawisko za pomocą terminów konwolucja i dekonwolucja. Zapamiętajmy te terminy.
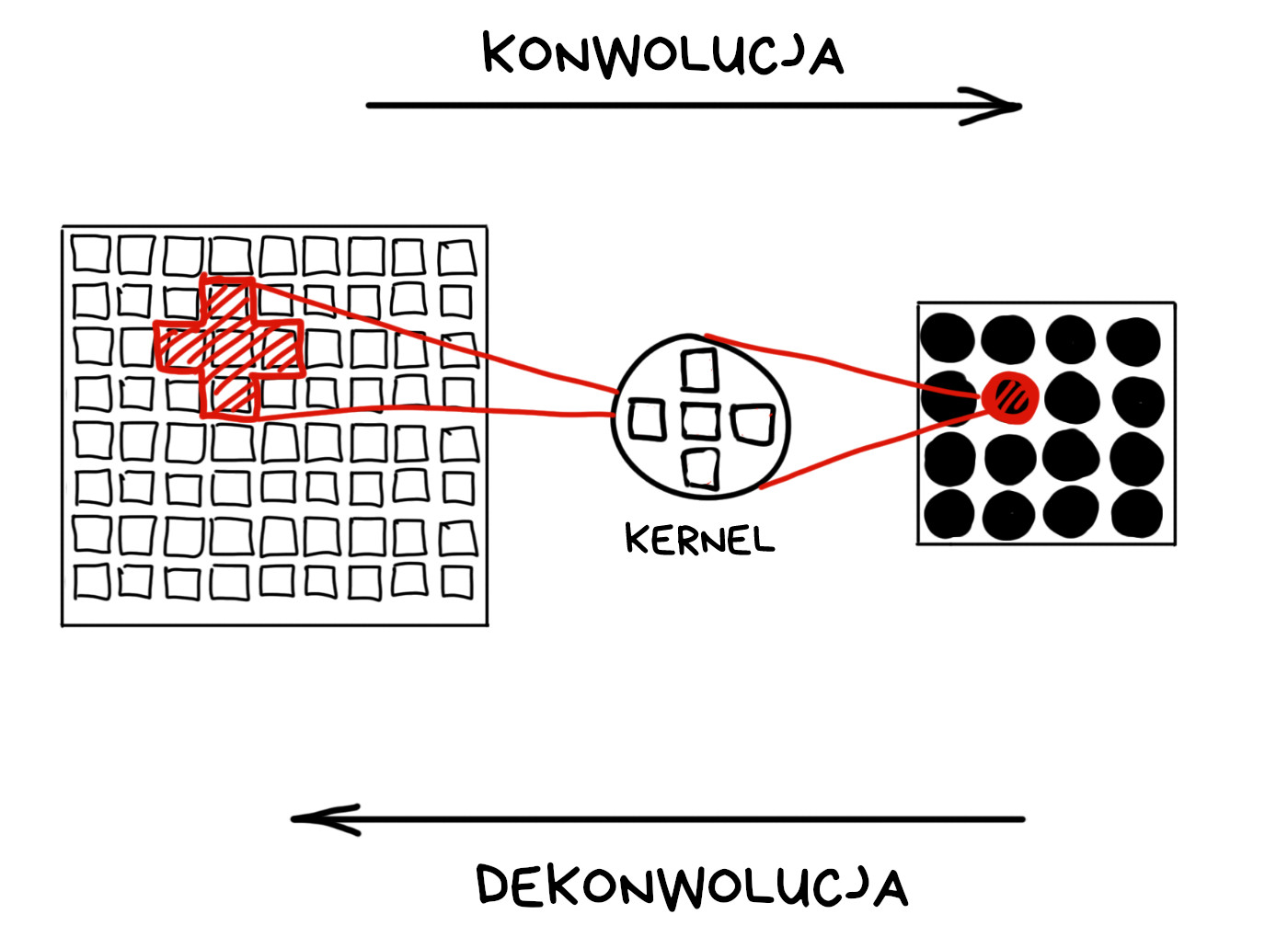
Jeśli znamy kernel (inaczej filtr, jądro przekształcenia), możemy odwrócić każdą konwolucję – tak mówi matematyka. W praktyce sensory mają ograniczoną czułość a obiektywy są dalekie od matematycznego ideału, więc efektu bokeh nie cofniemy całkowicie.
📝 High-quality Motion Deblurring from a Single Image
Możemy jednak próbować, gdy znamy kernel. Odgadliście już pewnie, że kernelem będzie kształt przysłony. Innymi słowy – przysłona robi przekształcenie konwolucyjne w paśmie optycznym.
Standardowa przysłona pozostaje okrągła niezależnie od stopnia rozmycia. Kernel jest niezmienny, a więc niezbyt użyteczny. W przypadku kodowanej przysłony promienie o różnym stopniu rozproszenia są przekształcane odmiennymi kernelami. Inteligentni czytelnicy wiedzą już, co się zaraz stanie.
Musimy dowiedzieć się, który kernel zakodował którą część obrazu. Można to robić ręcznie, ale lepiej zastosować transformatę Fouriera. Nie będziemy torturować tu nikogo rachunkiem różniczkowym, zainteresowani znajdą objaśnienie w poniższym filmie.
🎥 But what is the Fourier Transform? A visual introduction
Wystarczy nam wiedza, że transformata Fouriera pozwala znaleźć fale (częstotliwości) dominujące w wielu falach nałożonych na siebie. W przypadku dźwięków transformata Fouriera wskaże nam składowe nuty akordu. W przypadku fotografii – dominujący wzór nałożonych na siebie promieni światła, czyli właśnie jądro przekształcenia.
Ponieważ kształt kodowanej przysłony zależy od stopnia rozogniskowania, możemy obliczyć dystans od obiektu, korzystając z pojedynczego zdjęcia pochodzącego ze zwykłej matrycy!
Gdy użyjemy dekonwolucji z wyznaczonym kernelem, wyostrzymy rozmyte fragmenty fotografii.
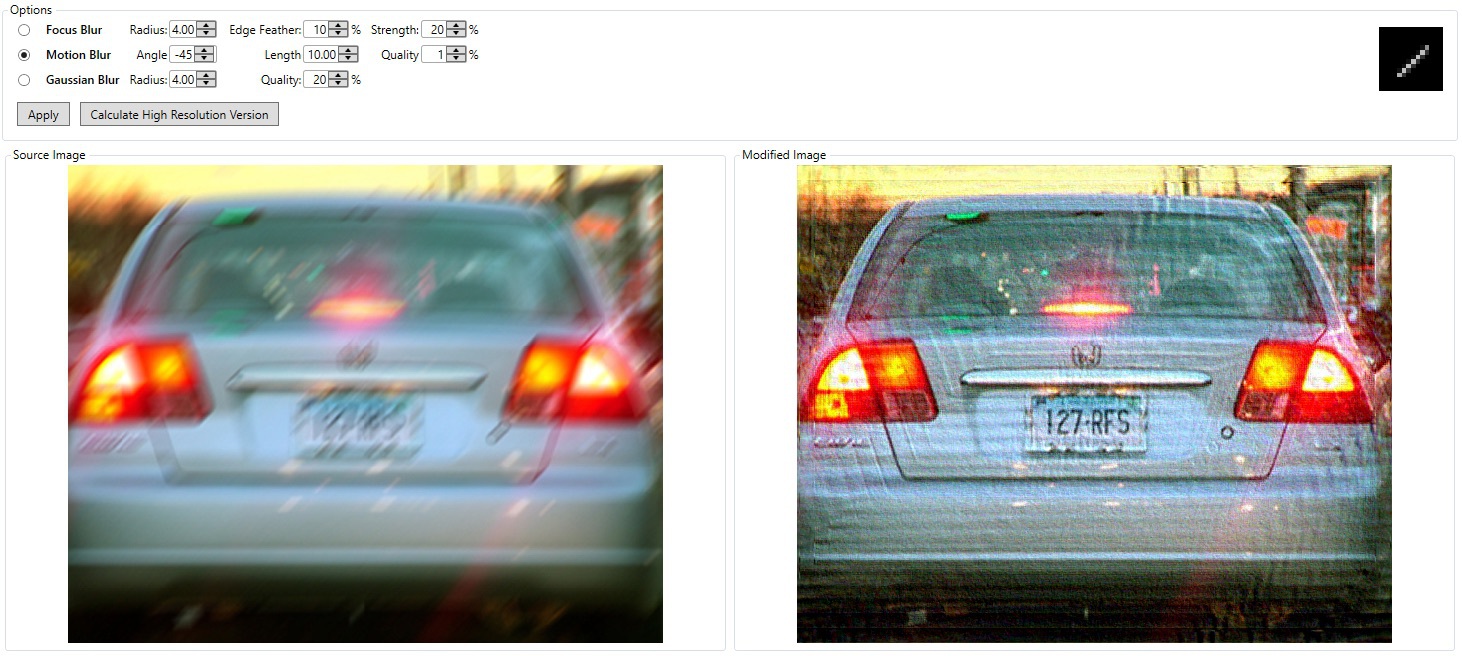
Tak działa większość narzędzi do wyostrzania obrazu. Radzą sobie one także z okrągłą przysłoną, ale efekty są mniej dokładne.
Do słabych stron kodowanej przysłony należą szum i utrata (odfiltrowanie) sporej części światła padającego w obiektyw. Lidary i sensory „time of flight” całkowicie wyparły kodowane przysłony z elektroniki konsumenckiej. Dajcie znać, jeśli gdzieś na nie traficie.
📝 Image and Depth from a Conventional Camera with a Coded Aperture
📝 Coded Aperture. Computational Photography WS 07/08
🎥 Coded aperture projection (SIGGRAPH 2008 Talks)
Kodowanie fazy (częstotliwości)
Według najnowszych doniesień światło rozchodzi się jak fala. Gdy stosujemy kodowaną przysłonę, regulujemy przejrzystość obiektywu, więc w efekcie kontrolujemy amplitudę (natężenie) tej fali. Oprócz amplitudy możemy kodować także fazę (częstotliwość) fali świetlnej.
Użyjemy do tego elementu optycznego dokonującego dyspersji, czyli załamującego z różną siłą światło o różnej częstotliwości. Tak jak pryzmat na okładce płyty „Dark Side of the Moon” Pink Floydów.

Dalej wszystko działa już tak, jak w dowolnym innym kodowaniu optycznym. Gdy znamy zniekształcenie, możemy wykryć je algorytmami i zmodyfikować odtwarzany obraz wynikowy – na przykład przesuwając płaszczyznę ostrości.
Zaletą kodowania fazy jest brak utraty jasności. Wszystkie fotony dotrą do matrycy – w przeciwieństwie do kodowanej przysłony, gdzie część z nich zatrzymywały nieprzezroczyste fragmenty płytki stanowiącej przysłonę.
Do wad należy utrata ostrości, bo nawet idealnie wyostrzony obraz obiektu zostanie rozszczepiony na składowe, które trafią na matrycę mniej lub bardziej rozproszone. Z powrotem złożymy je do ostrej kupy (hmmm) przy użyciu transformaty Fouriera. Pod poniższym linkiem znajdziecie dokładniejszy opis i więcej przykładów.
📝 Computational Optics by Jongmin Baek, 2012
Kodowana migawka
Walczymy z rozmyciem ruchu
Ostatnim elementem, którego możemy użyć do kodowania sygnału, jest migawka. Załóżmy, że chcemy w nocy zrobić zdjęcie jadącego samochodu, by z fotografii odczytać jego numery rejestracyjne. Po tajniacku, bez flesza. Nie możemy użyć długiego czasu naświetlania, bo wszystko się rozmyje; nie możemy użyć krótkiego czasu naświetlania, bo zdjęcie będzie czarne. Co robić?
Zamiast typowego cyklu „otwórz – odczekaj – zamknij”, będziemy otwierać i zamykać migawkę wielokrotnie podczas jednego ujęcia, na dłużej i krócej, w różnych interwałach. W efekcie dostaniemy wielokrotną ekspozycję tej samej sceny z kilku kolejnych chwil – na jednym obrazie.
Zamiast rozmazanej smugi, typowej dla zbyt długiego czasu naświetlania, otrzymamy „drabinkę” wywołaną ustaloną sekwencją otwierania i zamykania migawki. Wówczas proces dekonwolucji pozwoli na odtworzenie pierwotnego obrazu o wiele skuteczniej, niż jest to możliwe przy jednorodnym rozmyciu na poruszonym ujęciu.

Istnieje kilka algorytmów realizujących to zadanie. Wszystkie szczegóły znajdziecie w poniższych materiałach
📝 Coded exposure photography: motion deblurring using fluttered shutter
🎥 Flutter Shutter Coded Filter
Oświetlenie obliczeniowe
Kolejny pomysł jest już lekko zwariowany – chcielibyśmy kontrolować oświetlenie po zrobieniu zdjęcia. Podmienić pochmurną pogodę na słoneczną albo zmodyfikować oświetlenie twarzy modelki na gotowej fotografii. Dziś wydaje się to szalone. Pogadamy za dziesięć lat.
Teraz mamy do dyspozycji dość prymitywne urządzenie do kontroli oświetlenia – lampę błyskową. Flesze przebyły długą drogę, od ręcznie podpalanych zasobników z magnezją aż po nowoczesne lampy LED, których i tak częściej używamy jako latarek.

Programowalny flesz
We współczesnych smartfonach nie znajdziemy ksenonowych lamp błyskowych. Pochłaniały zbyt dużo energii, były droższe, nie dało się nimi doświetlać klipów wideo. Co z tego, że ich światło było mocniejsze i lepiej rozświetlało ciemną scenę? LED-y wygrały. A w zasadzie – podwójne LED-y. Czemu podwójne?
Jedna dioda LED ma odcień pomarańczowy a druga niebieskawy – dzięki temu możliwa jest regulacja temperatury barwowej światła, którym doświetlamy scenę. W telefonach iPhone technologia ta nosi nazwę True Tone i jest kontrolowana przez mały kawałek kodu realizujący sekretne obliczenia. Programiści aplikacji korzystających z aparatu nie mają nad nią kontroli.
📝 Demystifying iPhone’s Amber Flashlight

Jako drugi trafił na warsztat inny problem wszystkich lamp błyskowych – prześwietlanie twarzy i ogólnie całego pierwszego planu. Rozwiązania były różne. iPhone dostał Slow Sync Flash, w którym aparat krótko błyska fleszem, lecz wydłuża ogólny czas otwarcia migawki, co pomaga w rejestracji tła. Google Pixel i inne smartfony z Androidem wyliczają, które elementy obrazu znajdują się na pierwszym planie, a następnie używają tej informacji do nałożenia dwóch zdjęć zrobionych jedno po drugim, z fleszem i bez. Tło pochodzi z fotki zrobionej bez doświetlania.

Przyszłość programowalnych fleszy jest niejasna. Jedynym interesującym zastosowaniem jest póki co rozpoznawanie obrazów, gdzie używa się ich do bardziej precyzyjnego wyznaczania krawędzi fotografowanych obiektów. Szczegóły jak zwykle w artykule poniżej:
📝 Non-photorealistic Camera:
Depth Edge Detection and Stylized Rendering using Multi-Flash Imaging
Kodowanie światłem (Lightstage)
Światło porusza się szybko. To zawsze ułatwiało kodowanie informacji w paśmie widzialnym. Możemy zmieniać oświetlenie dziesiątki lub setki razy na sekundę i nadal ze wszystkim zdążymy. Dzięki temu w 2005 roku skonstruowano Lightstage.

Dzięki takiej konstrukcji możemy filmować modela kamerą szybkostrzelną, zmieniając oświetlenie dziesiątki lub setki razy na sekundę. To sprawia, że w ramach jednego klipu wideo rejestrujemy jednocześnie wiele różnych wariantów oświetlenia – na potrzeby filmu kinowego wystarczają bowiem 24 klatki na sekundę.
Podobne podejście jest używane, gdy przy użyciu efektów specjalnych wstawiamy obiekty lub postacie do istniejącego materiału filmowego. Gdy możemy sterować światłem w postprodukcji, cała trudność sprowadza się do wybrania odpowiedniego kąta oświetlenia, dostosowania gradacji kolorów i… już?


Ciężko zrealizować coś takiego na urządzeniach przenośnych, za to wiele firm próbuje zamienić smartfony w skanery 3D
Lidary i sensory „Time-of-flight”
Lidar to urządzenie określające odległość od wskazanego obiektu. Dzięki marzeniom o autonomicznych samochodach lidary stają się coraz tańsze i coraz lepsze. Choć są za duże, by zmieścić się w smartfonach, to ich młodsze rodzeństwo – sensory „Time-of-flight” (ToF) – trafiły już na wyposażenie co lepszych modeli. Przypominają radar działający w paśmie podczerwieni: flesz IR emituje bardzo krótki błysk, zaś przeznaczona do tego celu kamera mierzy czas powrotu światła odbitego od różnych obiektów w kadrze. Pomiar taki pozwala sporządzić mapę głębi danego obrazu.

Dokładność współczesnych sensorów ToF wynosi około centymetra. Najnowsze flagowe Samsungi i Huaweie używają ich do programowego rozmywania tła portretów i do ustawiania autofokusa w ciemności. To ostatnie działa naprawdę dobrze. Przydałoby się we wszystkich telefonach.
Precyzyjna mapa głębi kadru będzie kluczowa w zastosowaniach tzw. rzeczywistości rozszerzonej. Specjalizowane czujniki zawsze sprawdzą się lepiej niż programowe rekonstruowanie otoczenia 3D na podstawie obrazu z kamery.
Oświetlenie matrycowe
Aby na serio mówić o oświetleniu obliczeniowym, musimy przestawić się ze zwykłych fleszy LED na projektory – urządzenia zdolne do wyświetlania dwuwymiarowego obrazu na płaszczyźnie. Nawet monochromatyczny projektor będzie niezłym punktem wyjścia, jeśli uda się go umieścić w smartfonie.
Projektor będzie w stanie oświetlić tylko to, co wymaga oświetlenia. Koniec z prześwietlonymi twarzami na pierwszym planie. Obiekty będzie można identyfikować i omijać – podobnie jak matrycowe światła drogowe w nowoczesnych samochodach nie oślepiają kierowców jadących z naprzeciwka. Nawet przy niewielkiej rozdzielczości takiego projektora, choćby 100×100 punktów, otworzą się zupełnie nowe możliwości.

Inne zastosowania projektorów to wyświetlanie niewidzialnej siatki punktów używanych do wyznaczenia mapy głębi. Może to być alternatywa dla lidarów i sensorów ToF. Tak właśnie działał śp. Microsoft Kinect, niech spoczywa w pokoju.
Warto wspomnieć tu FaceID i wykorzystywany przez tę funkcję rzutnik wyświetlający podczerwone kropki na twarzach użytkowników iPhone X. To mały, ale istotny krok w stronę fleszy-projektorów.

Przyszłość fotografii
Zarządzanie sceną 3D i rozszerzona rzeczywistość

Czas na chwilę refleksji. Z obserwacji wielkich firm technologicznych wynika, że następne 10 lat będzie mocno związane z rozszerzoną rzeczywistością (Augumented Reality, AR). Dziś jest to jeszcze zabawka do przymierzania butów, eksperymentowania z makijażem lub szkolenia żołnierzy. Jutro z AR będziemy korzystać codziennie. Google i Nvidia już poczuły w tym trendzie konkretne pieniądze.
W świecie fotografii będzie to oznaczało możliwość pełnego kontrolowania zarejestrowanego kadru. Zeskanuj otoczenie, jak smartfon z Tango, dodaj nowe obiekty, jak w HoloLenz, i tak dalej. Nie zniechęcaj się kiepską grafiką współczesnych aplikacji AR. Gdy tylko na tę platformę wejdą modne gry, ich grafika przebije najnowsze Playstation.


{kind=link}
{kind=link}
Pamiętacie epicki tryb Fałszywego Księżyca w urządzeniach Huawei? Gdy aparat w telefonie Huawei wykrył, że robisz zdjęcie Księżyca, podmieniał jego tarczę na gotowy obrazek wysokiej rozdzielczości. O co chodzi, przecież teraz wygląda lepiej! Ot, taki chiński cyberpunk.

Gdy na Twitterze skończyły się już dowcipy na ten temat, przemyślałem całą sytuację – przecież Huawei dostarczył to, co obiecał. Księżyc był prawdziwy a aparat, którym go sfotografowano, naprawdę wyśmienity. Zero oszustwa. Jeśli jutro udostępnisz możliwość wstawienia w fotki pięknego wschodu słońca, połowa ludzkości będzie zachwycona.
W przyszłości maszyny będą ulepszać i retuszować nasze fotki za nas
Pixel, Galaxy i innej Androidowe telefony mają różne głupawe tryby AR. Możesz umieścić w kadrze postać z bajki, rozsypać po pokoju emotki albo nałożyć na twarz maskę, jak w Snapchacie.
To wszystko jednak tylko nieśmiałe początki. Już dziś aparaty Google mają Google Lens, który znajduje informacje o obiektach w kadrze. Samsung robi to samo z Bixby. Na razie triki te służą tylko poniżaniu użytkowników iPhone’a, ale łatwo wyobrazić sobie, że gdy następnym razem zrobisz selfiaka pod wieżą Eiffla, twój telefon powie: wiesz, ten selfiak jest do dupy; pozwól że podmienię zdjęcie w tle na ostre, poprawię ci fryzurę i usunę pryszcza. Jeśli chcesz wrzucić tę fotę na Instagrama, polecam filtr VSCO L4. Nie ma za co.
Potem aparat zacznie podmieniać trawę na bardziej zieloną a przyjaciółki na przyjaciółki z większymi cyckami. Czy jakoś tak. Nowy wspaniały świat.

Na początku będzie to wyglądało groteskowo. Albo strasznie. Fotografowie będą oburzeni, aktywiści będą protestować a użytkownicy… Użytkownicy będą zachwyceni. W fotografii zawsze chodziło o wyrażanie emocji i dzielenie się nimi. Za każdym razem, gdy te emocje można w obrazie zawrzeć w sposób prostszy i bardziej czytelny, zaczynamy tych możliwości używać — dlatego stosujemy emotki, filtry, stickery, maski, załączniki audio. Niektórym ta lista nie podoba się już teraz, ale na pewno będzie się wydłużać.
Fotografie „rzeczywistej rzeczywistości” będą uważane za tak nudne, jak pozowane zdjęcie praprababci na fotelu. Nadal będą istnieć, jak istnieją papierowe książki i płyty winylowe – coś dla pasjonatów i historyków. Dominować będzie jednak nastawienie w rodzaju „po co mam dobierać oświetlenie i kompozycję zdjęcia, mój smartfon zrobi to za mnie”. To nasza przyszłość. Przykro mi.
Masowego odbiorcy nie obchodzi prawda obiektywna. Chcą algorytmów, dzięki którym twarze na zdjęciach będą gładsze a wakacje – barwniejsze. No i koniecznie bardziej atrakcyjne niż wakacje na zdjęciach znajomych z pracy. Rozszerzona rzeczywistość zastąpi prawdziwą, będzie wręcz bardziej szczegółowa od tej drugiej. Może to zabrzmi śmiesznie, ale AR zacznie poprawiać wygląd świata.
Jak zawsze pionierami będą nastolatkowie i ich „dziwne, głupie pomysły interesujące tylko prostaków”. Tak dzieje się zawsze. Jeśli przestajesz za czymś nadążać, to JEST przyszłość.
Nowoczesne smartfony a fotografia obliczeniowa
Trudno wskazywać różnice między aparatami w nowoczesnych smartfonach, bo z powodu dużej konkurencji nowe funkcje wprowadzane przez jednego producenta są bardzo szybko replikowane przez pozostałych. Jeśli Google wypuści na rynek telefon z nowym trybem nocnym, po miesiącu Samsung i Xiaomi opublikują aktualizację oprogramowania z lepszym lub gorszym odpowiednikiem tej funkcji. To powiedziawszy, informuję, że w poniższym zestawieniu nie będę silił się na obiektywność.
Na obrazkach poniżej opisuję zwięźle główne cechy kilku telefonów interesujące w kontekście niniejszego artykułu. Pomijam takie oczywistości, jak flesze z podwójnych LED-ów, automatyczny balans bieli czy tryb panoramiczny. Do porównania trafiły tylko smartfony, które miałem w rękach osobiście.
[Od tłumacza: oryginalna wersja artykułu była opublikowana w czerwcu 2019]



Podsumowanie
Historia pokazuje, że każda technologia staje się doskonalsza, gdy przestajemy naśladować żywe organizmy. Trudno wyobrazić sobie samochód ze stawami i mięśniami zamiast kół, prawda? Samoloty latają 800 km/h, ptaki pozostają daleko w tyle. Nie ma w naturze żadnego odpowiednika mikroprocesora.
Na tej liście nie znajdziemy jednak matrycy aparatu fotograficznego. Wciąż nie mamy lepszego sposobu na rejestrację obrazu, niż naśladowanie struktury oka, z soczewką i czopkami reagującymi na poszczególne składowe widma. Fotografia obliczeniowa dodaje do procesu „mózg”, który uzupełnia rejestrację obrazu o wnioskowanie oparte na zgromadzonej wiedzy. Owszem, daje nam to sporo nowych możliwości, ale nadal jesteśmy na etapie doczepiania skrzydeł do ramion, nie zaś wymyślania samolotu. Kiedyś przyjdzie czas porzucić wszystkie te przysłony i filtry Bayera.
Najpiękniejsze jest, że dziś nie potrafimy nawet wyobrazić sobie, co zastąpi obiektywy, migawki i matryce. Wiemy tylko, że kiedyś coś takiego się pojawi i zmieni fotografię na zawsze.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

29 odpowiedzi na “Fotografia obliczeniowa”
A ja bym powiedział, że Twój kolega miał aparat, ale nie umiał robić nim zdjęć 😉
(bajdełej zdjęcie do dowodu robiłeś chyba u mojej Małżonki — ona mogłaby Tobie poopowiadać o tym do czego niekiedy prowadzi samoobsługa, zwłaszcza przy wykorzystaniu komórek)
Najpiękniejsze jest, że dziś nie potrafimy nawet wyobrazić sobie, co zastąpi obiektywy, migawki i matryce. Wiemy tylko, że kiedyś coś takiego się pojawi i zmieni fotografię na zawsze.
J: są też prowadzone badania w celu wykorzystania oka ludzkiego i mózgu do rejestracji obrazu. Obraz byłby rejestrować w taki sposób jaki widzi go obecnie człowiek swoim okiem.
Telefon służy do dzwonienia a nie do fotografowania sama nazwa mówi, że aparat służy do zdjęć. Kiedyś też tak uważałem że smartfony są niczym lub lepsze niż bezlusterkowce ale nie są. Masz kontrolę nad zdjęciem i wszystko co jest w nowych smartfonach nowością było u lustranek 20 lat temu 😄 jak chcesz zdjęcie w nocy ustawiasz czas naświetlania na 1s (lub więcej) zależy od światła w obiektywie. Pozatym smartfony mają ch*jowe przeostranie zdjęć i soft z kosmosu nic nie zmieni dalej będzie szum. Czy ktoś kto pracuje w zawodzie fotografa czy filmografa używa smartfon?
No dobrze ale ten artykuł jakby zwraca uwagę na inny aspekt, tj. rozwój technologi w telefonie. Sam jestem trochę w szoku, że wreszcie zrozumiałem dlaczego zawsze narzekałem, że żeby robić fajne foty lustrzanką z balkonu na zachodzące słońce nad stocznią gdańską (taki widok miałem akurat przez dwa lata) to była cała jakby celebracja, statyw, naświetlania, kombinacje, a w sumie jak trzeba było nagle cyknać fotę (bo burza nagle nadeszła i była super gra świateł) to mój HTC ogarniał sprawę i mam porównywalnie tyle samo dobrych fot ze smartfona jak i z lustrzanki. Dlatego ten artykuł trochę mnie rozgrzeszył z myślenia że „po cholerę mi ta lustrzanka!!!” 🙂 takie naukowe opisanie życiowego tematu. I jak sądzę, raczej w komórkach będzie zauważalny rozwój a w lustrzankach nie. A jak ktoś się zawodowo zajmuje tematem to i tak wybiera (albo dostaje) najlepsze narzędzia do pracy. Może kiedyś komórki „do dzwonienia” wygrają ten wyścig? 🙂
Dzięki za tekst, jest świetny i przystępnie napisany. Bardzo mnie zaskoczyło jak bardzo technika (czy raczej informatyka) w fotografii poszła do przodu.
„Nie ma w naturze żadnego odpowiednika mikroprocesora.”
A może mózg ?
Nope. Mózg to sieć neuronowa, działa na innej zasadzie niż mikroprocesor (maszyna Turinga).
Baaardzo dobry artykuł, widać mega napracowanko. I jeszcze ten humor między wierszami. Zostaję stałym czytelnikiem bloga 🙂
Swoją drogą to jest trochę niepokojące jak bardzo technologia się rozwija, nie jesteśmy w stanie przewidzieć co się wydarzy za dekadę. Fotografia przestaje wymagać od nas obróbki, wszystko jest zautomatyzowane w komputerze mniejszym od portfela. Analiza otoczenia, lidary, sieci neuronowe. Potem jeszcze agregacja tych danych przez operatora i wnioskowanie… przerażające!
To nie jest artykuł, to jest legenda
Za teza: najlepszy aparat to taki, który ma się przy sobie. Lecz w rozwiązaniach profesjonalnych, Pan Autor zamiast z kolegą amatorem idzie na sesję portretowa i przyniesie portfolio dla modelki, idzie na ślub i przyniesie pełny reportaż ślubny, jedzie nad Biebrzę i przywiezie klika zdjęć ptaków. Jeśli autor zrobi lepsze zdjęcia niż Ci pro fotografowie to można stwierdzić smartfon robi lepsze zdjęcia niż fotograf i aparat fotograficzny. Pozdrawiam😁
Podobno ludzkie oko jest optycznie słabym elementem a jednak mózg radzi sobie z tym bardzo dobrze. Być może ta sama idea przyświeca w smartfonach. Ale zróbcie sobie smartfonem zdjęcie w nocy i zapiszcie to do DNG, o ile smartfon obsługuje RAW-y a potem otwórzcie to chociażby FastStone. Jakość takiego zdjęcia powinna być żałosna ze względu na szumy. Wyobrażacie sobie jak by wyglądały zdjęcia ze smartfona gdyby nie te algorytmy odszumiania i wyostrzania? Poza tym nie ma przeszkód aby wymienione tu, choć może nie wszystkie techniki stosować fotografując lustrzanką.
Są przeszkody, bo lustrzanki nie dają hardware’u do tego. I nie implementują potem tego przetwarzania. Nie ma takich lustrzanek po prostu.
Panie Tomaszu, jestem pierwszy raz na Pana blogu, przekierował mnie tu link z bloga robię habilitację nie znam się na fotografii smartfonach, technice cyfrowej itp i wiele terminów, o których Pan i inne osoby piszą w komentarzach to dla mnie czarna magia. ALE jestem tłumaczem i muszę Panu pogratulować właśnie tłumaczenia. Tak lekko i dowcipnie napisanego tekstu specjalistycznego, będącego tłumaczeniem wykonanym przez, jak rozumiem, niezawodowego tłumacza (porównywałem z wersja ang.) z wykorzystaniem smaczków polszczyzny od dawna nie czytałem. Szacun 🙂
Dzięki za miłe słowa, pomagali mi lepsi ode mnie i tekst dużo zawdzięcza właśnie im. Pozdrawiam!
Bardzo ciekawy artykuł, o wielu rzeczach dowiedziałem się po raz pierwszy. Bronię jednak lustrzanek, gdy byłem dzieckiem, modne były zegarki na rękę elektroniczne, tak zwane „świerszcze” – wielu mówiło wówczas że to koniec „wskazówkowych”… czas pokazał co innego 🙂 P.S. Telefon Samsung Galaxy S10 chyba nie ma matrycy 48 Mpx (z tyłu 12/12/16)?
Świetna robota, super zebrane informacje o użytych technologiach, kilka lat temu interesowałem się tematem, więc sporo technologi kojarzę, ale dużo rzeczy nie znałem. Fajnie widzieć jak nowości z konferencji SIGGRAPH trafiają na półkę.
Ta matryca aparatu w smartfonie wielkości czubka szpilki ma w rzeczywistości co raz częściej przekątną dochodzącą do 2 cm co jeszcze do niedawna było rozmiarem imponującym w kompaktach. Zwykły budżetowy chiński smartfon za 500 złotych ma obecnie matrycę 1/2.55” co jest wielkością odpowiadającą pewnie 50 tym główką szpilki.
sensor 1/2.55” ma wymiary 6,17×4,55mm co daje przekątną 7,7mm , nawet matryca 1″ (13.2 x 8.8 mm) ma przekątną tylko 15.86 mm, a słyszałem tylko o jednym smartfonie z martycą 1″ (Lumix CM1 z 2014 roku) więc nie wiem gdzie widziałaś „coraz częściej” smartfony z matrycą o przekątnej 2cm
Świetny artykuł. Udowadniający niestety przykrą prawdę. Dotychczas podawano diagnozy: śmierć kompaktów, śmierć systemów foto z mniejszymi matrycami. Wyprą je smartfony. I rzeczywiście, smartfony wyprą prawie całą fotografię optyczną. Przy niej zostaną tylko Ci, którzy chcą posiąść podstawy wiedzy fotograficznej i chociaż podstawy postprodukcji. Ale masy nie chcą się uczyć niczego, więc dla nich fotka ze smartfona będzie lepsza. Że sztuczna – nawet nie zauważą. Efektem tej „ewolucji” będzie upadek większości firm produkujących sprzęt optyczny. I ogromny wzrost cen tegoż sprzętu, wynikający z małego popytu. Przykre, ale chyba nieuniknione. Szmira, jak zwykle, zwycięży
Powiem krótko.
Ja pi…..lę!
A tak poważnie, nie mam nic do dodania. Najlepsze jest jednak nie to, o czym jest ten artykuł, ale jak jest napisany.
Panie Tomaszu, niesamowite tłumaczenie, bardzo dziękuję. Otworzyło mi oczy na pewne sprawy związane z smartfonami.
[…] ktoś już napisał na ten temat (świetny zresztą) artykuł, więc nie będę się rozwodził nad detalami i powtarzał opowieści o tym, jak to jest […]
Oooo, super artykuł !! Bardzo ciężko znaleść takie techniczne „rozmyślenia” co w „smartfonie” piszczy. Kiedyś była gazetka np chip potem strony internetowe jak pclab, benchmark tez swego czasu pisal w ten sposob. No ale juz tego nie ma a wszystko inne jedzie na „hejcie” bo sie dobrze klika… jak np spiderweb (pisane z bykiem ) ale ci to naprawdę zaginają wszelkie granice przyzwoitości jak nasza polska tv i inne media.
Nie neguję komórczanej fotografii ale jakoś ona do mnie nie przemawia. Wolę robić zdjęcia klasycznym aparatem – to jest dla mnie swojego rodzaju wyzwanie aby zrobić dobre zdjęcie a nie nawalić snapshotów komórczanych i w zasadzie to tyle z nich pożytku. Dla mnie dobre zdjęcie kończy się wydrukiem nie mniejszym niż 10×15. To, że większość tandeciarzy akceptuje komórczane zdjęcia nie oznacza, że ja muszę je akceptować. Robię zdjęcia nie po to aby wychwalać wygładzoną przez software skórę na jakimś podrzędnym portalu ale po to aby potomni wiedzieli jak wyglądali ich rodzice, dziadkowie w rzeczywistości a nie jak upiększył je software używający AI. Zgodnie z ogólnie przyjętą tezą, że liczba ludzi na ziemi rośnie ale ogólny poziom inteligencji już nie widać w jakim kierunku zmierza fotografia, która trafiła pod strzechy w postaci smartfonów.
Ale tu nie o to chodzi. Podstawową zasadą dobrej fotografi jest ta: najlepszy aparat to ten, który masz pod ręką. Jak idę na rower, to nie biorę mojej lustrzanki, tylko komórkę. Jak idę na narty, to też nie wezmę lustrzanki, tylko co najwyżej kompaktowca. A super kadr można trafić w trakcie tych aktywności, oj można. I co, lepiej w ogóle nie mieć zdjęcia czy mieć zdjęcie wspomagane przez fotografię obliczeniową?
Popsuł mi Pan dzień. Poczułem się mały w obliczu tak epickiego artykułu. Pozamiatał Pan po totalu!
Super artykuł, czytałem po angielsku, bardzo fajnie, że jest polskie tłumaczenie dostępne 🙂
Artykuł wręcz niesamowity. Miałem iść spać ale było warto poświęcić ten kawał czasu bo ilość wiedzy tu zgromadzonej jest nieprawdopodobna. Bardzo chętnie przeczytałbym kontynuację wzbogaconą o to co zmieniło się od 2019 roku. Domyślam się, że szanse na to są nikłe, ponieważ zebranie takiej ilości informacji byłoby sporym wyzwaniem.
Pozdrawiam serdecznie i dziękuję za to tłumaczenie!
Lata miją, już prawie 5 lat minęło od publikacji artykułu. Lustrzanek prawie nie ma. Wyparły je bezlusterkowce, no bo po co lustro skoro teraz elektronika przetwarza obraz na żywo i wizjer może być elektroniczny. Niestety, są to drogie bezlusterkowce – mniejszy popyt, większa cena.
Za to producenci smartfonów wymyślili kolejny chwyt marketingowy czyli setki megapikseli. Może kiedyś na coś się przydadzą, nie przeczę. Ale obecnie to kolejny chwyt marketingowy. Kupi taki użytkownik smartfona z 200 Mpix, bo tak go wychwalali w reklamie. A potem robi zdjęcia, wrzuca na Facebooka i nawet nie wie, że po pierwsze jest pixel binning i zdjęcia realnie mają mniej Mpix, a po drugie ten Facebook albo inny komunikator kompresuje mu zdjęcia do zaledwie 2 Mpix.
A fotografia obliczeniowa doszła doszła do ściany, ludzie np. na forum Samsunga zaczęli narzekać na przeostrzone, nienaturalne zdjęcia. Są wątki typu „Dajcie wreszcie S24 Ultra możliwość wyłączenia procesowania zdjęć.”.
No i co teraz? Albo przebijemy ścianę i procesor telefonu zacznie upiększać zdjęcia jeszcze bardziej, np. korzystając z AI (wtedy to już nawet nie będą nasze zdjęcia) albo programiści w końcu postawią nacisk na obiektywną wierność rzeczywistości. A do zrobienia jest sporo. Choćby softwarowe usuwanie „blików” w iPhonie, które nocą całkowicie psują wideo. Taki dziwny obiektyw skonstruowali, widać wszelkie odbicia światła. Albo w końcu porządny i płynny zoom, bo to jest cecha aparatów/bezlusterkowców, której jeszcze żaden smartfon nie dorównał.
Albo w końcu implementacja brakujących wartość FPS. W niektórych telefonach nie dość, że brakuje kinowych 24 FPS, to jeszcze brakuje tego co jest standardem w Europie czyli 25 i 50 FPS, co całkowicie przekreśla je wśród profesjonalistów.
To tak pokrótce widać. Producenci i programiści smartfonów mają jeszcze naprawdę sporo do zrobienia.