
Natrętne reklamy są prawdziwą plagą stron internetowych, często spoza bannerów i popupów nie widać w ogóle treści redakcyjnych. Nic więc dziwnego, że czytelnicy masowo instalują w przeglądarkach dodatki blokujące treści reklamowe. Blokery reklam często idą za ciosem i wycinają także skrypty śledzące ruch na stronie, np. te z Google Analytics (dlaczego? bo mogą).
Twórcy internetowi, tacy jak ja, stają wówczas przed zagadką – ile osób naprawdę odwiedza stronę? Prawdziwe liczby dobrze znać choćby po to, by móc je wskazać potencjalnym sponsorom. Instalacja i samodzielne utrzymanie mechanizmu statystyk opartego o Javascript mija się z celem, bo skrypty Google Analytics są wycinane tak samo, jak hostowanego samodzielnie Matomo czy chmurowego Piwika Pro. Aby było jasne – każdy odwiedzający może sobie blokować co zechce i nic mi do tego. Po prostu moje zainteresowanie statystykami lekko ściera się z dążeniem części odwiedzających do pełnej anonimowości.
Aby raz na zawsze odpowiedzieć na pytanie, jaki procent ruchu na tej stronie jest niewidoczny na Google Analytics, sięgnąłem do surowych statystyk serwera WWW. W poniższym tekście pokazuję, jak porównać dane z tych dwóch źródeł przy użyciu pakietu Microsoft Power BI Desktop. Jest to narzędzie, które stanowi krok pośredni między Excelem (przykładowa analiza tutaj tutaj) a językami przeznaczonymi do analizy statystycznej (wspomnianymi tutaj).
Co będziemy porównywać
W porównaniu udział wezmą statystyki pochodzące z Google Analytics – eksport danych z tego narzędzia opisałem w artykule „Obrabiamy dane z Google Analytics w arkuszu kalkulacyjnym”. Skąd Google bierze te dane? Niniejsza strona zawiera osadzone skrypty, które wysyłają informacje o jej otwarciu do serwerów Google Analytics. Odpowiada za to np. taki kawałek kodu:
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-146136328-1"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-146136328-1');
</script>Jeśli dodatek blokujący reklamy zapobiegnie wykonaniu tego skryptu, Google Analytics nie dowie się o wejściu na stronę przez danego użytkownika.
Do oszacowania wiarygodności Google Analytics będziemy potrzebować danych referencyjnych z logów programu Apache. Apache to serwer WWW czyli program, który działa na serwerze obsługującym domenę informatykzakladowy.pl, przyjmuje żądania wysyłane przez przeglądarki czytelników i odsyła im potrzebne pliki – głównie z treścią artykułu oraz obrazkami stanowiącymi wystrój strony. Logi serwera WWW zawierają więc dane o wszystkich odwiedzinach na stronie.
Ładujemy logi Apache do Microsoft Power BI
W niniejszym tekście będziemy analizować dane przy użyciu aplikacji Microsoft Power BI Desktop. Rozwinięcie liter „BI” w nazwie to „business intelligence” czyli „analityka biznesowa”. Power BI bywa naprawdę przydatny; w końcu narzędzia do analityki biznesowej oferują znacznie większe możliwości przekształcania i analizy danych, niż arkusz kalkulacyjny Excel. Dodatkowa zaleta – Power BI jest dostępny za darmo, więc każdy może wypróbować go bez zobowiązań i bez ponoszenia jakichkolwiek kosztów.
W tym miejscu normalnie umieściłbym obszerne, ilustrowane wprowadzenie do Power BI Desktop, ale… już takie napisałem. Dwa tygodnie temu zostało opublikowane jako osobna blogonotka na stronach PGS Software, mojego pracodawcy.
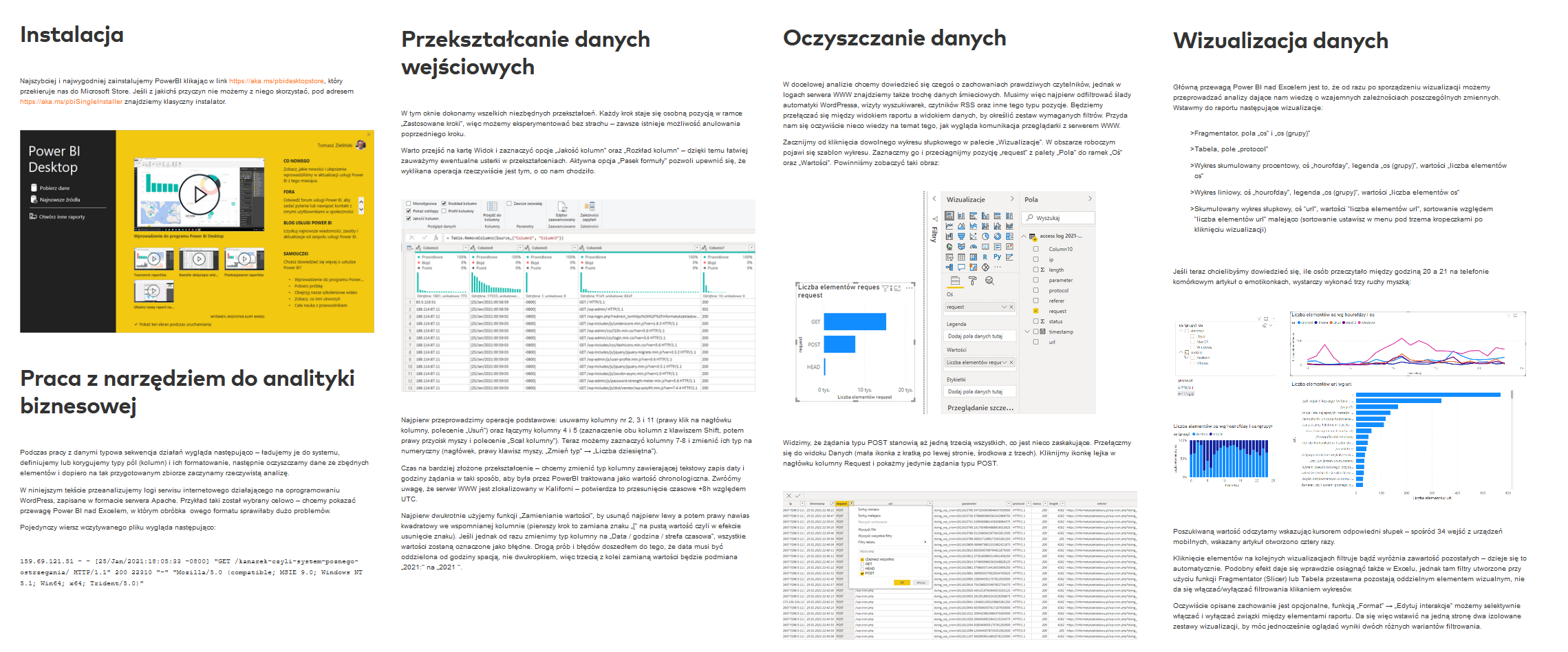
Umówmy się więc, że tekst dostępny tutaj jest osobnym rozdziałem niniejszego artykułu. Zapraszam do przeskoczenia, przeczytania i powrotu.
Już? W porównaniu do opisanej w tym drugim tekście obróbki logów Apache, załadowanie danych z Google Analytics będzie trywialne. To raptem dwie kolumny (indeks godzinowy i liczba odsłon), które można zaimportować z pliku CSV albo przekopiować bezpośrednio z Google Sheet.
Porównujemy dane
Aby porównać dane pochodzące z logów Apache i statystyk Google Analytics, musimy najpierw sprowadzić je do „wspólnego mianownika” czyli uzgodnić różnice stref czasowych. Chyba najprościej zrobić to poprzez wyliczenie dla każdego wiersza różnicy między wskazaniem daty i godziny a arbitralnie ustaloną godziną zero; trzeba też pamiętać, aby godziny zaokrąglać „w dół” a nie do najbliższej pełnej wartości.
Gdy w obu zestawach danych będziemy mieli indeks liczący godziny od tego samego momentu zerowego, możemy zweryfikować poprawność danych tworząc dwa wykresy z dwóch źródeł danych:
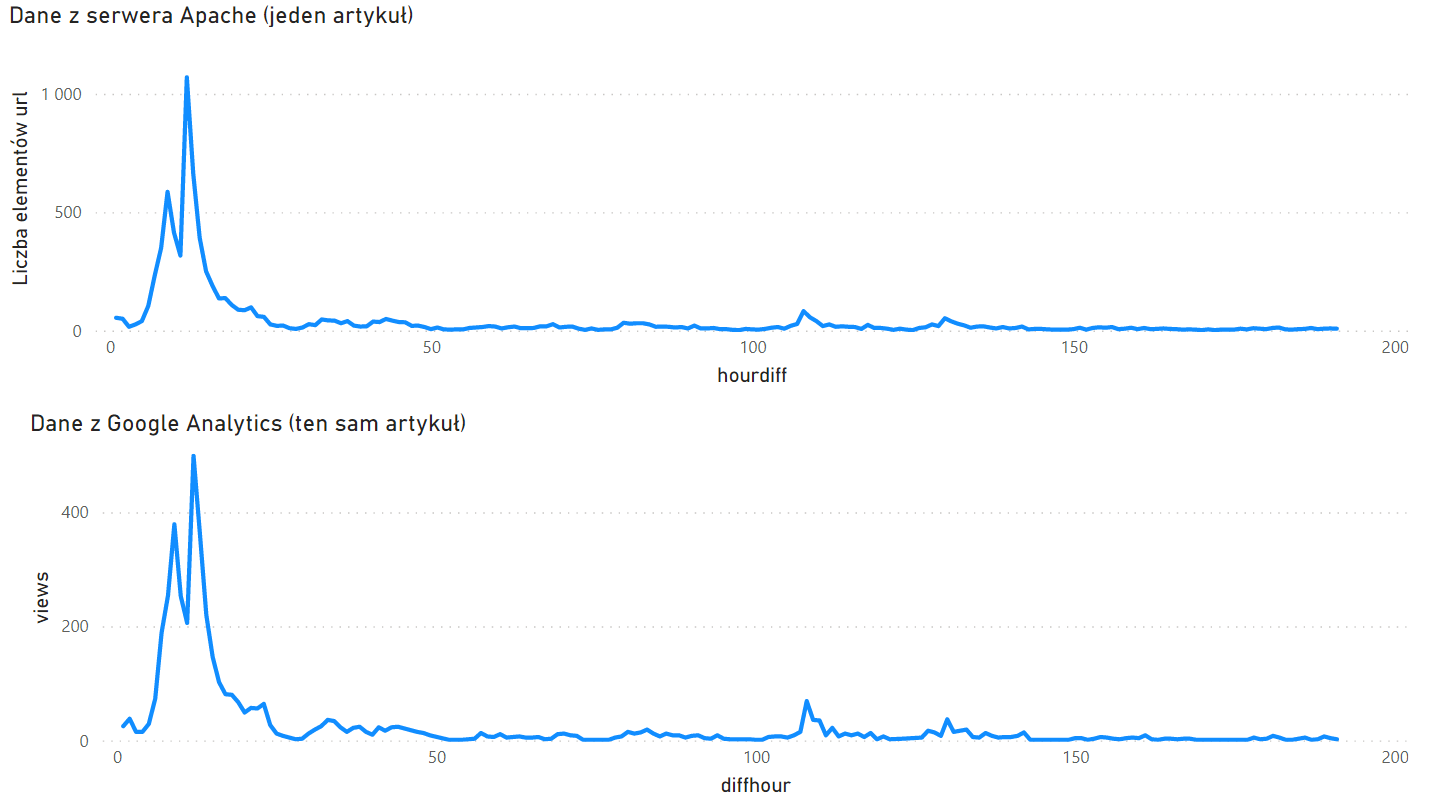
Ręczna inspekcja uwidacznia, że górki i dołki, choć różnią się wartościami, występują na tych samych pozycjach osi X. W ten sposób potwierdzamy, że udało nam się poprawnie uzgodnić osie czasu z obu źródeł.
Aby umieścić te dane na jednym wykresie, musimy jeszcze użyć funkcji „Zarządzanie relacjami” z zakładki „Narzędzia tabel” (widok Danych). Power BI nie wie bowiem, które kolumny z różnych tabel zawierają tożsame wartości.
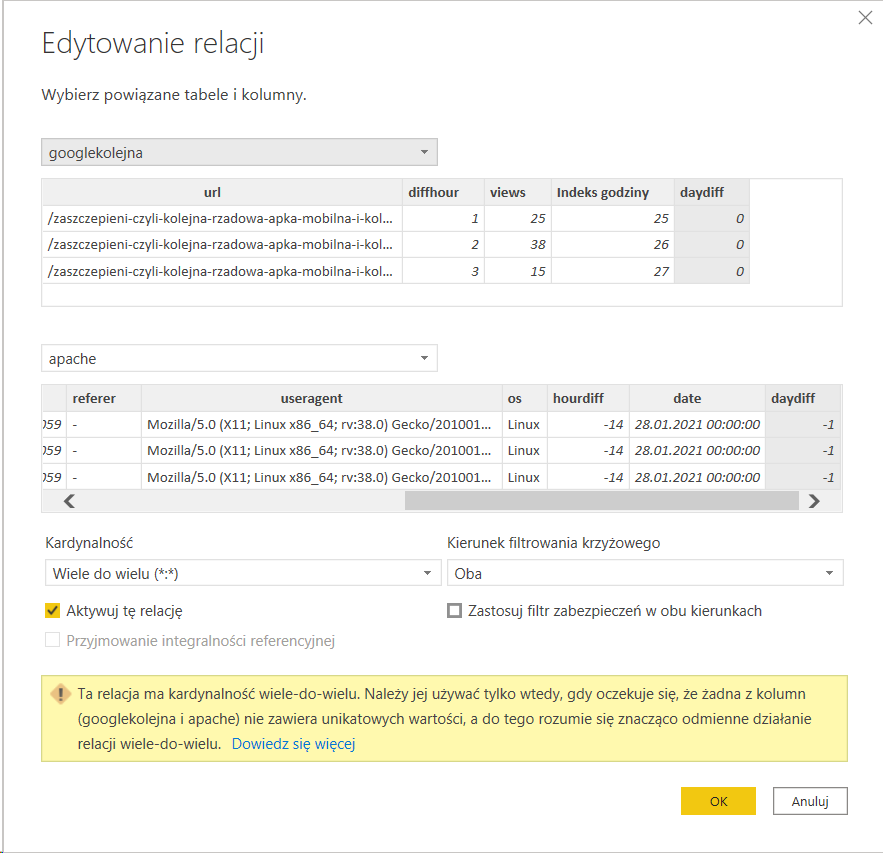
Na ilustracji widzimy, że relacja jest oparta o kolumnę „daydiff” wyliczoną w obu tabelach jako wynik dzielenia różnicy godzinowej przez 24. Żółta ramka ostrzega przed relacją jeden-do-wielu, ale z taką właśnie mamy tu do czynienia – na jedną godzinę obserwacji przypada w naszym raporcie jeden wiersz z Google Analytics i wiele żądań odnotowanych w logach Apache.
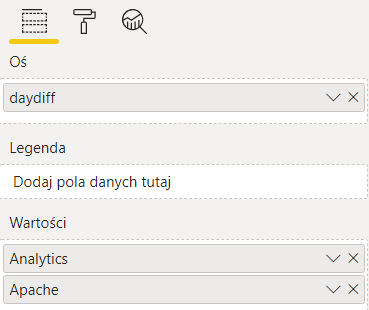
Gdy relacja między tabelami zostanie ustanowiona, ustawienia wizualizacji mogą wyglądać jak na ilustracji powyżej – pole „daydiff” pochodzi z dowolnej z dwóch tabel, będzie to oś wspólna dla obu serii danych występujących w ramce „Wartości”.
Analiza wyników
Na pierwszy ogień idzie porównanie czytelnictwa artykułu o aplikacji „Zaszczepieni”. Na wykresach poniżej widzimy liczbę odwiedzin według obu źródeł w ciągu pierwszych dziewięciu dni od premiery.
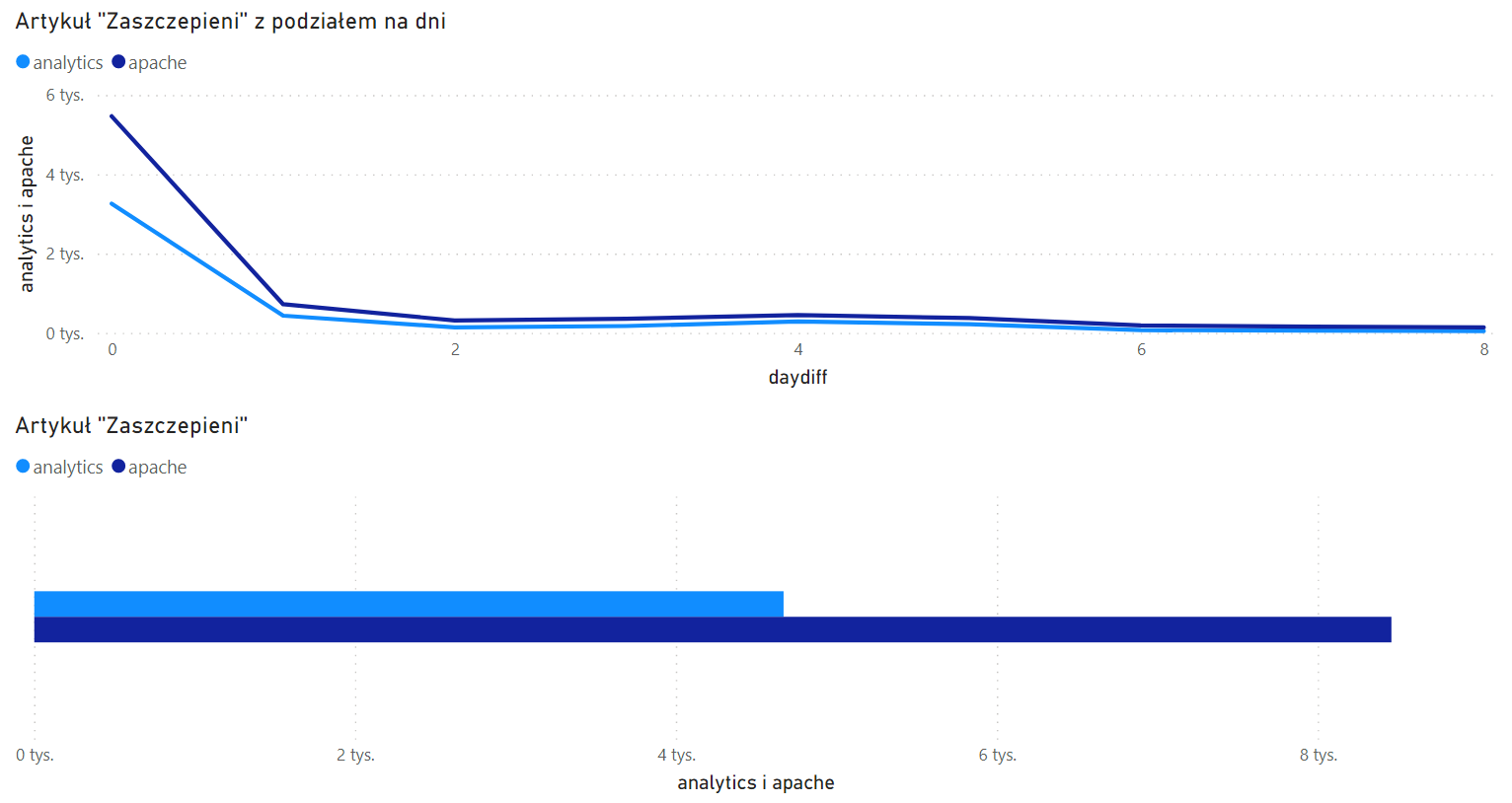
Widzimy, że różnica jest bardzo duża – 4628 kontra 8014 odsłon (Analytics pokazał 58% wizyt odnotowanych przez Apache). Czyżby Analytics zaniżał dane aż w takiej proporcji?
Spójrzmy na wykres odwiedzin znacznie starszego artykułu o emotiokonkach i Unicode, z tych samych dziewięciu dni:
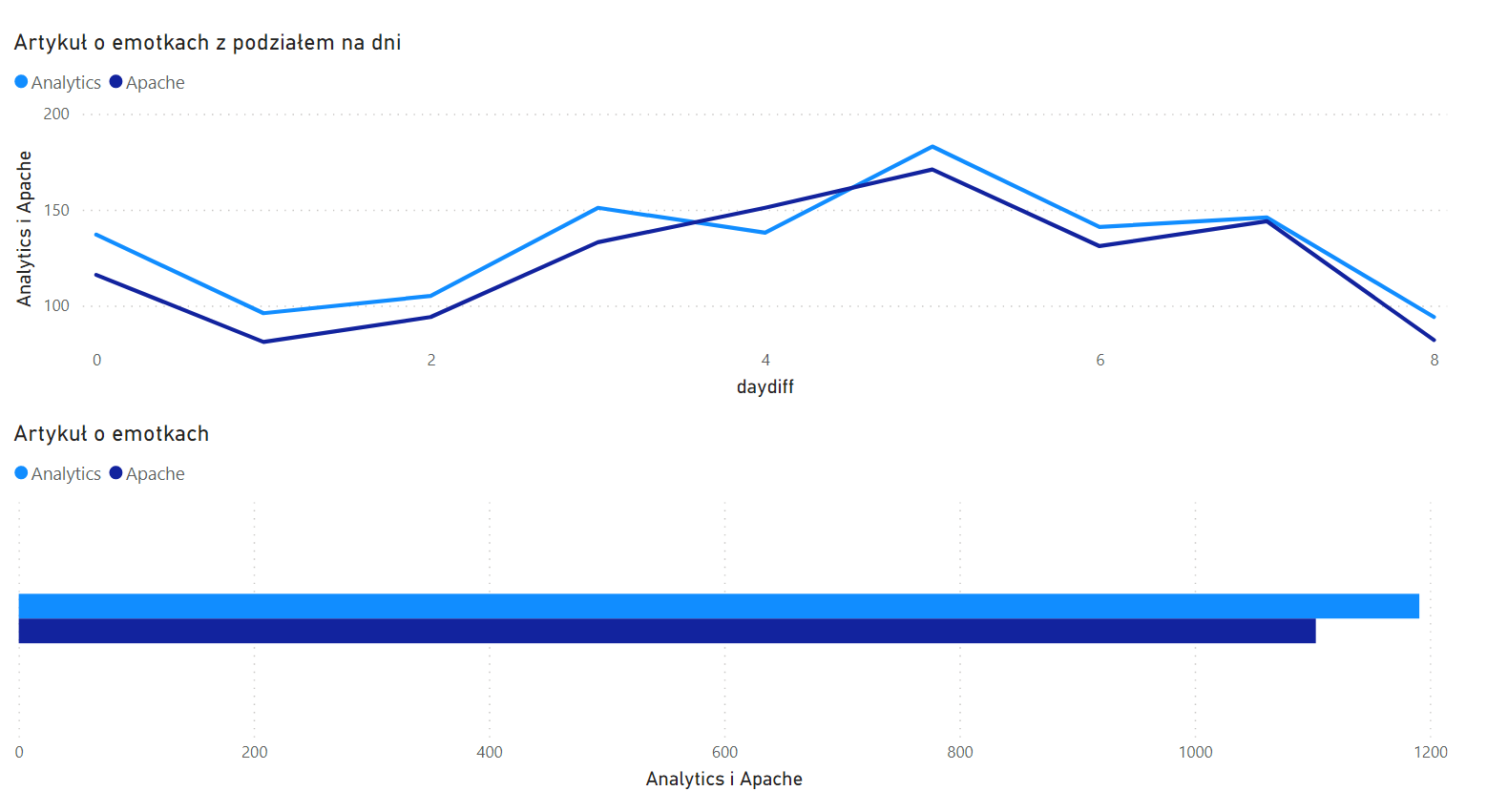
Przewagę ma… Analytics? Jak to możliwe, aby zliczył więcej odsłon, niż rzeczywiście zostało wykonanych? Jedyne, co przychodzi mi do głowy, to użycie przycisku „wstecz” w przeglądarce, co miałoby skutkować ponownym pyknięciem do Analytics, ale ze stroną załadowaną z cache przeglądarki (a więc bez wpisu w logach Apache).
Sprawdźmy jeszcze tekst o Familu Linku:
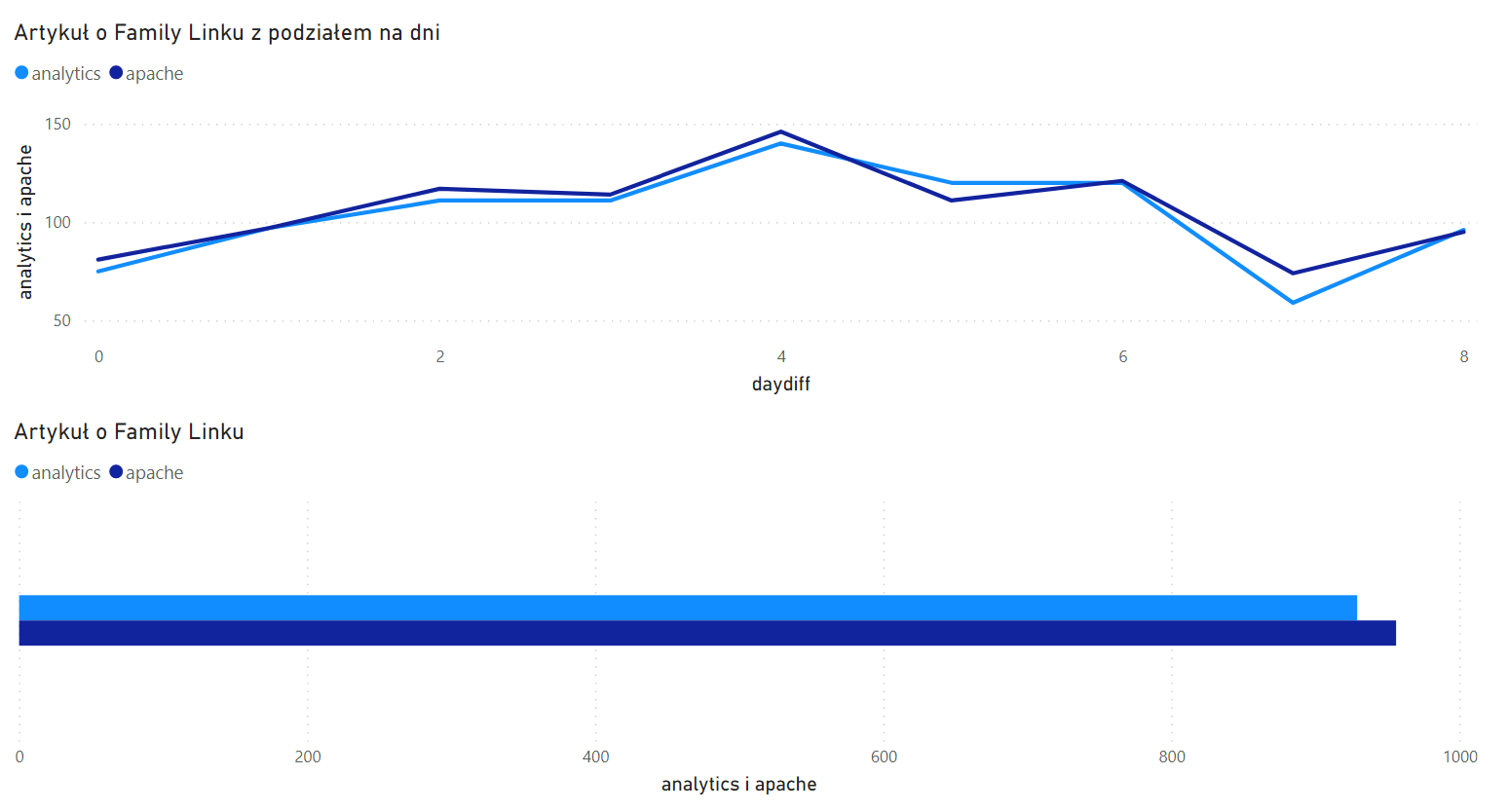
Tutaj statystyki Google Analytics i logów Apache idą łeb w łeb. Spojrzałem jeszcze na liczbę odsłon innego tekstu, który po kilku miesiącach od premiery wrócił na kilka dni na pierwsze miejsce oglądalności. W kilka dni wygenerował kilka tysięcy odsłon: 6 tys. według Apache i 5.1 tys. według Analytics (85% odsłon odnotowanych przez serwer). Nie każdy wzmożony ruch wygląda więc jednakowo.
Czego się dowiedzieliśmy o wiarygodności Google Analytics?
Cóż, liczby nie opowiedziały nam tym razem spójnej, logicznej historii. Nie chcę zarzucać czytelników zbyt dużą liczbą podobnych wykresów, ale dodatkowe kwerendy uzasadniają następującą hipotezę: osoby trafiające na bloga tuż po premierze nowego artykułu, przez linki od znajomych lub z social mediów, stanowią grupę o innej charakterystyce, niż typowi czytelnicy przekierowani przez Google.
Statystyki Cloudflare mogę określić jako niewiarygodne – w danych opisanych we linkowanym już artykule wyraźnie widzimy, że liczba odwiedzin robotów i czytników RSS idzie w tysiące dziennie a Cloudflare najwyraźniej traktuje takie odsłony na równi z aktywnością żywych czytelników.
Robocze wnioski do stosowania w najbliższej przyszłości: Google Analytics pokazuje mniej-więcej rzeczywisty ruch, gdy na blogu niewiele się dzieje; w dniach wzmożonej aktywności może zaniżać wyniki dwukrotnie. W dłuższej perspektywie zmiany tych proporcji są nie do przewidzenia – choćby dlatego, że wkrótce rynek reklamowo-analityczny czekają poważne zmiany.
Tu prośba do ciebie, czytelniczko lub czytelniku – jeśli masz wgląd w statystyki innych serwisów WWW sporządzane różnymi metodami, napisz w komentarzach, jak u ciebie wygląda wiarygodność statystyk Google Analytics. Może w ten sposób wspólnie wychwycimy jakieś trendy. Z góry dziękuję!
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

11 odpowiedzi na “Google Analytics a prawdziwa oglądalność bloga”
Blokuję skrypty w przeglądarce i na routerze (wycięta komunikacja np. z częścią serwerów Google). Jak widzę wzmiankę o jakimś artykule, to ręcznie wpisuję adres w przeglądarce (nie ujawnia się referer).
Polecam AWstats, analizuje logi i robi ładne statystyki. Można zaciągać logi z hostingu (scp…). Działa w Dockerze.
Przecież referer można blokować, w Firefoksie nawet wtyczki do tego nie potrzeba (w about:config można to ustawić), po co się męczyć z ręcznym przepisywaniem.
Dużo też zależy od „branży” czytelników.
U nas na sekuraku czasem aż 80% ludzi deklaruje, że blokuje rozmaite skrypty trackujące.
Ale to się też zmienia, np. kiedy jest u nas wpis, który jest bardziej interesujący „dla każdego” (nie tylko dla maniaków itsec 😉 – wtedy % blokowania skryptów jest mniejszy = statsy są nieco bardziej zbliżone do realnych.
Mam wrażenie że prawie każdy kto siedzi w branży ma swoją listę blokowanych skryptów.
Jedna wątpliwość po przeglądaniu wykresów. Skoro do GA nie wszystko dociera (bo jest wycięte), a logi z serwera łapią cały ruch to dlaczego na wykresach są momenty, gdzie liczba z GA jest większa niż z logów? Na przykład „daydiff = 5” dla tekstu o Family Linku.
To jest właśnie anomalia, której nie rozumiem – wykres „Czytelnictwo artykułu o emotikonkach” ma prawie wszystkie dni z takim zapisem. Równie dobrze może to byś jakiś glitch GA – np. w panelu realtime czasem wartość „bieżąca” kumuluje kwadrans lub dwa wszystkich wejść.
Tak czy owak najbardziej chciałem poznać skalę rozjazdów i z badań wyszło, że GA gubi co najwyżej połowę odbiorców. Taki poziom szczegółowości wystarczy, zostawiam temat jak jest.
U mnie również różnice między GA a logami z serwera (Nginx) bardzo duże, czasem nawet kilkukrotnie więcej wychodzi z logów. Od czasu do czasu robię testy i spora w tym „wina” blokowania m.in. skryptów GA. Ogólnie jak Sekurak pisze – sporo zależy też od rodzaju ruchu. Artykuły bardziej techniczne to różnice większe, te bardziej masowe mniejsze. Ale też Google nie ukrywa, że (niektóre) dane w GA są „szacowane” a nie liczne 1:1.
No i od dawna patrzenie na statystyki przestało być tym, co ma wg mnie sens. Przynajmniej na co dzień. Jeśli już, to bardziej od UU (szacowanego) interesują mnie trendy, a te nawet w wersji GA są wystarczające. Zwłaszcza od wprowadzenia GA4.
A tak w ogóle, to zdarzają się też różnice, i to czasem nawet spore, między klasycznym GA a GA4, pomimo identycznej implementacji.
Statystyki z Cloudflare zazwyczaj sporo zawyżają i trzeba trochę pobawić się w filtrowanie. A to nawet na koncie Business nie jest obecnie wystarczające. Ale widać, że mają ambicję, bo statystyki odpalili również w wersji zewnętrznej usługi, bez konieczności podpinania domeny do CF (kod JS, jak GA).
Sprawa wygląda jeszcze śmieszniej gdy masz adres onion podpięty do swojej strony. Mam u siebie i Onion i zwykły URL i niestety większa część ruchu jest z Tor’a a tam wszyscy pozabezpieczani po zęby 😉 No i przekłamania w lokalizacji bo masz taką z jakiej exit node.
> dlaczego? bo mogą
Nie „bo mogą” tylko dla prywatności. BTW nawet już nie potrzeba blokerów reklam do tego, Firefox chyba sam z siebie blokuje analyticsy (w ramach wbudowanej blokady skryptów śledzących)
> skrypty Google Analytics są wycinane tak samo, jak hostowanego samodzielnie Matomo
I tu jest problem. Osobiście uważam że to nie fair wobec twórców stron. Mam nadzieję, że ktoś kiedyś zrobi kampanię na rzecz zwhitelistowania skryptów które są privacy-friendly.
Ja używam https://goaccess.io/ . W cronie ustawiony jest skrypt obrabiający logi access oraz errors i robi z nich co godzinę raport w html. Działa świetnie, nie wysyła logów do żadnej zewnętrznej instancji i pokazuje co trzeba. Wystarczy zrobić w Apache vhosta z htpaswd, który będzie pokazywał ten plik. Miłej zabawy.
https://wiki.baszarek.pl/doku.php?id=wiki:goaccess
Przypomnę jeszcze o Matomo (dawniej Piwik) jako alternatywie dla GA. W stosunku do rozwiązania opisywanego w artykule ma parę zalet: jest gotowcem, więc mniej pracy, szczególnie jeśli ktoś chciałby statystyki np. po geoIP. Pozwoli na rozpoznanie botów, których wizyty w logach stanowią nawet kilkadziesiąt procent ruchu.
No i najlepsze jest to, że Matomo nie boi się blokad skryptów. Owszem, może działać w oparciu o JS i/lub obrazek, ale potrafi także korzystać bezpośrednio z logów serwera WWW, niekoniecznie apache: https://www.ronan.bzh/p/nginx-analytics-with-matomo-on-freebsd/