
Każdy czytelnik Informatyka Zakładowego musiał słyszeć o Niebezpieczniku, Zaufanej Trzeciej Stronie i Sekuraku, wielkiej trójce polskich serwisów IT security. Mało kto orientuje się jednak, jaki ogrom wiedzy otrzymaliśmy stamtąd całkowicie za darmo. Wiedzę zmierzyć trudno, objętość opublikowanych tekstów łatwiej.
W niniejszym tekście opisuję, jakich narzędzi użyłem do oszacowania aktywności i dynamiki publikacji w wymienionych serwisach, omawiam też uzyskane wyniki. Zadanie takie dałoby się zrealizować w jedno popołudnie, gdyby nie pewna nieoczekiwana przeszkoda…
Jakim narzędziem scrapować dane
Jednym z podstawowych narzędzi do zrzucania zawartości statycznych serwisów internetowych na dysk jest curl. Choć używam go z powodzeniem od lat, tym razem postanowiłem skorzystać z czegoś bardziej zaawansowanego, co pozwoliłoby na szybszą i prostszą realizację wybranego zadania.
Przez chwilę rozważałem użycie narzędzi sterujących „bezgłową” (pozbawioną własnego okna) przeglądarką Chrome lub Firefox. Do najbardziej znanych aplikacji tego typu należą Selenium i Puppeteer. Nie byłby to jednak dobry wybór – choć za pomocą tych narzędzi można zrobić z przeglądarką i apką webową praktycznie wszystko, byłoby to jak strzelanie z armaty do muchy. Ja potrzebowałem przecież jedynie odwiedzić wszystkie podstrony trzech WordPressów.
Moim ulubionym językiem programowania jest C#, jednak już pobieżny research wykazał, że w obszarze scrapowania świat preferuje Pythona (np. Scrapy, BeautifulSoup / MechanicalSoup) albo Node (np. Crawlee). Node prawie nie znam a Pythona zwyczajnie nie lubię, ale byłem gotów przemóc wewnętrzne „fuj” i napisać parę linijek kodu w tym języku.
Scrapowanie przy użyciu Scrapy
Niebezpiecznik, Z3S czy Sekurak to witryny działające w oparciu o oprogramowanie WordPress. Zadanie jest więc proste – automat ma przejść po wszystkich podstronach spisu treści i zebrać odnośniki do każdego opublikowanego artykułu. Następnie powinien odwiedzić każdy taki artykuł i zapisać liczbę znaków, jaka składa się na jego treść.
Do realizacji zadania wybrałem Scrapy. Chciałem poznać nowe narzędzie, skorzystałem z niego po raz pierwszy. Tu wielkie ukłony w stronę autorów – w ramach tutoriala generujemy projekt stanowiący kompletny, działający scraper strony przykładowej. Po przejściu krótkiego wprowadzenia potrafimy nie tylko pobrać spis treści i podstrony, ale także zapisać dane wyjściowe do pliku JSON.
Jak dobrać się do danych? Każdy szablon WordPressa wygląda inaczej, najprościej skorzystać z narzędzi developerskich w przeglądarce i zbadać strukturę strony:
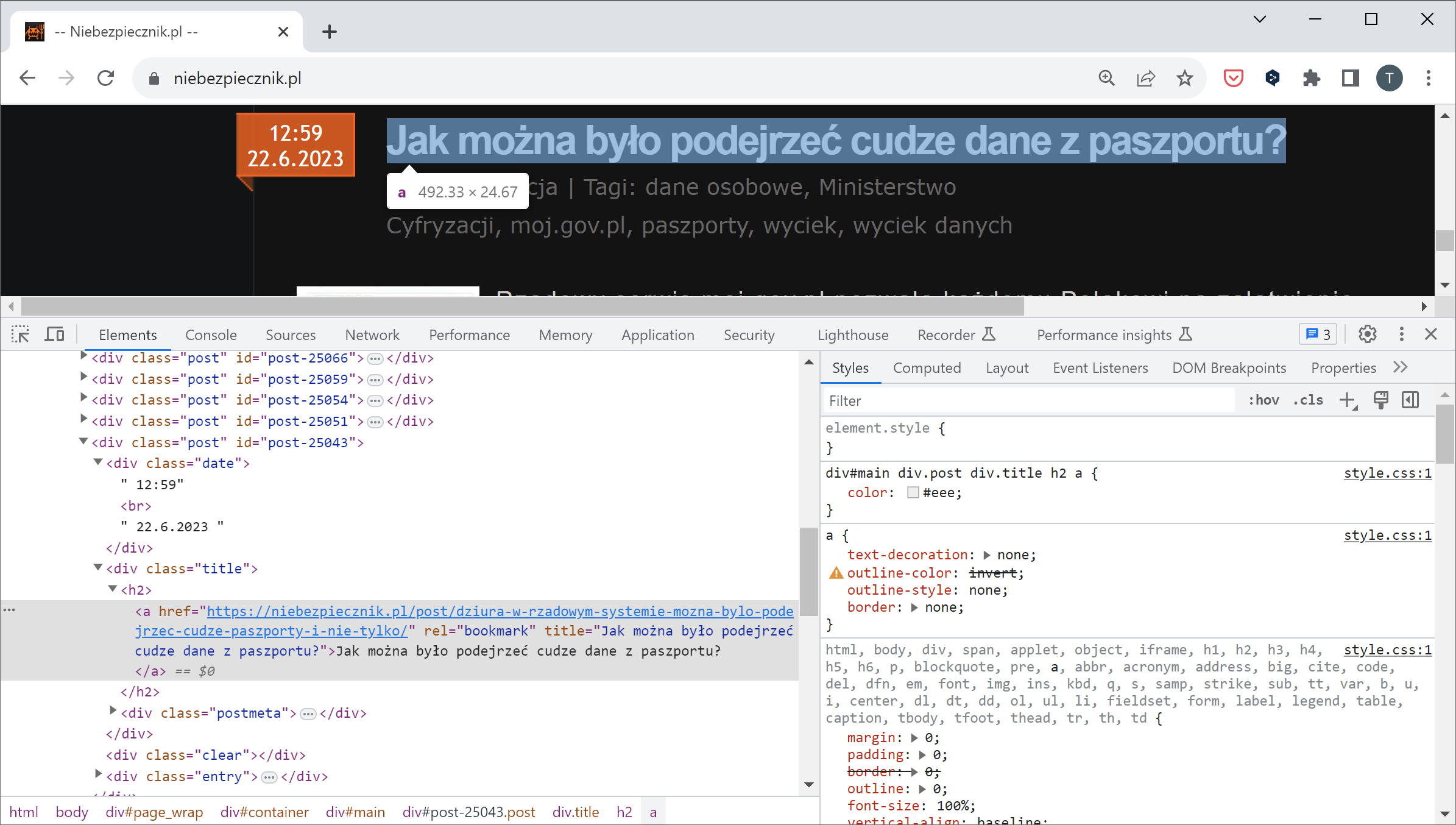
Do elementów strony Scrapy odwołuje się za pomocą selektorów XPath albo przypisanych obiektom klas CSS.
Przykład z powyższego obrazka – wszystkie zajawki artykułów Niebezpiecznika zbierzemy wyrażeniem response.css("div.post")
Następnie adres URL z każdej zajawki wyciągniemy za pomocą wyrażeniapost.css("div.title").css("h2").css("a::attr(href)").get()
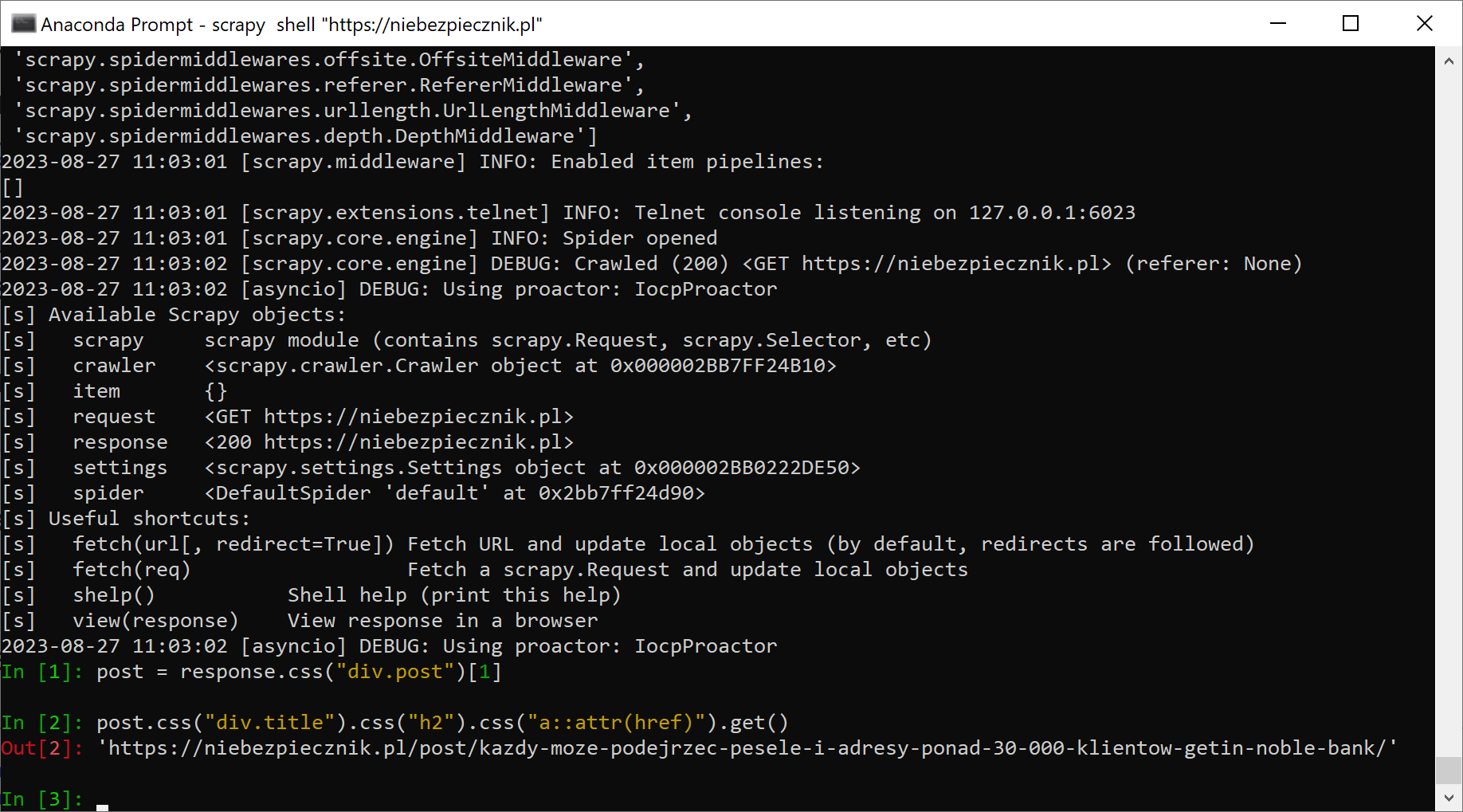
Skąd będziemy wiedzieć, jakich selektorów użyć? Scrapy ma tryb interaktywny (scrapy shell "https://niebezpiecznik.pl"), w którym możemy eksperymentować do woli:
Kompletny kod scrapera serwisu Niebezpiecznik wygląda następująco:

Zielony blok to kod przechodzący po spisie treści, ciemnozielony fragment jest odpowiedzialny za odnalezienie linka do kolejnej strony. Blok oznaczony kolorem niebieskim odczytuje stronę z artykułem, wyznacza liczbę znaków artykułu (bez komentarzy czytelników ani odsyłacza do innych artykułów) oraz zapisuje dane wynikowe do strumienia wyjściowego.
Po uruchomieniu automatu poleceniem scrapy crawl nbzp -O nbzp.json i odczekaniu kilku minut, otrzymujemy dane w oczekiwanym formacie.
Uwaga – opisywane serwisy nie publikują wszystkich artykułów na stronie głównej. Aby zebrać komplet materiałów, pobrałem dodatkowo publikacje niebezpiecznikowego linkbloga, sekurakowego W biegu oraz Drobiazgi Z3S.
Problemy z Sekurakiem
Scrapowanie Niebezpiecznika poszło szybko, Zaufanej Trzeciej Strony jeszcze szybciej (wystarczyło podmienić selektory w gotowym robocie), Sekurak wyglądał równie łatwo. Załadowałem stronę sekurak.pl do interaktywnego shella, wstawiłem działające wyrażenia do nowego robota, odpaliłem i… nic. Timeout.
Co gorsza – Sekurak przestał mi działać także w przeglądarce, choć nadal był dostępny przez sieć komórkową na telefonie. Czyżbym odpalił jakiś mechanizm chroniący przed scrapowaniem? Istnieje wiele ich rodzajów, działających w różny sposób, ale większość można było z miejsca wyeliminować.
W stronę Sekuraka wysłałem raptem kilka żądań, więc nie było mowy o ochronie przed atakiem DOS. Sekurak działa w przeglądarce z wyłączonym Javascriptem, co eliminuje większość niejawnych captchy. Jedyne obecne w przeglądarce cookies pochodziły z Google Analytics. To zaś oznacza, że głównym podejrzanym staje się pasywne wykrywanie klientów HTTP nie będących prawdziwymi przeglądarkami.
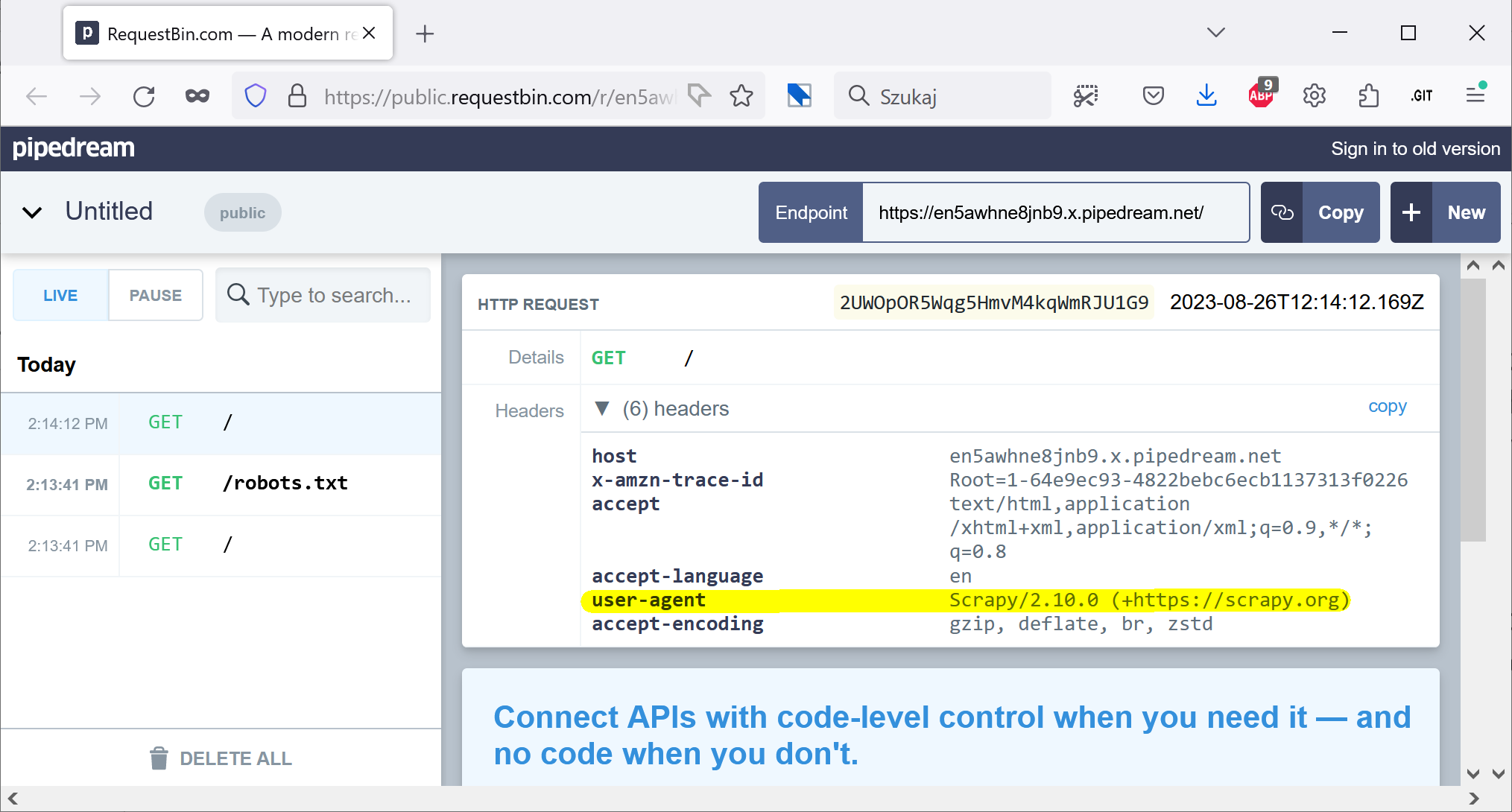
Wycelowałem interaktywnego Scrapy w RequestBin by sprawdzić, jakie nagłówki wysyła do serwera domyślna konfiguracja. Bingo! Scrapy przedstawia się jako Scrapy.
W jaki sposób sprawić, aby Scrapy udawał mojego Firefoxa? Najpierw otwieramy narzędzia deweloperskie na zakładce ruchu sieciowego i ładujemy stronę. Potem klikamy prawym klawiszem na pierwszym żądaniu i kopiujemy jego równoważnik w formie polecenia curl.
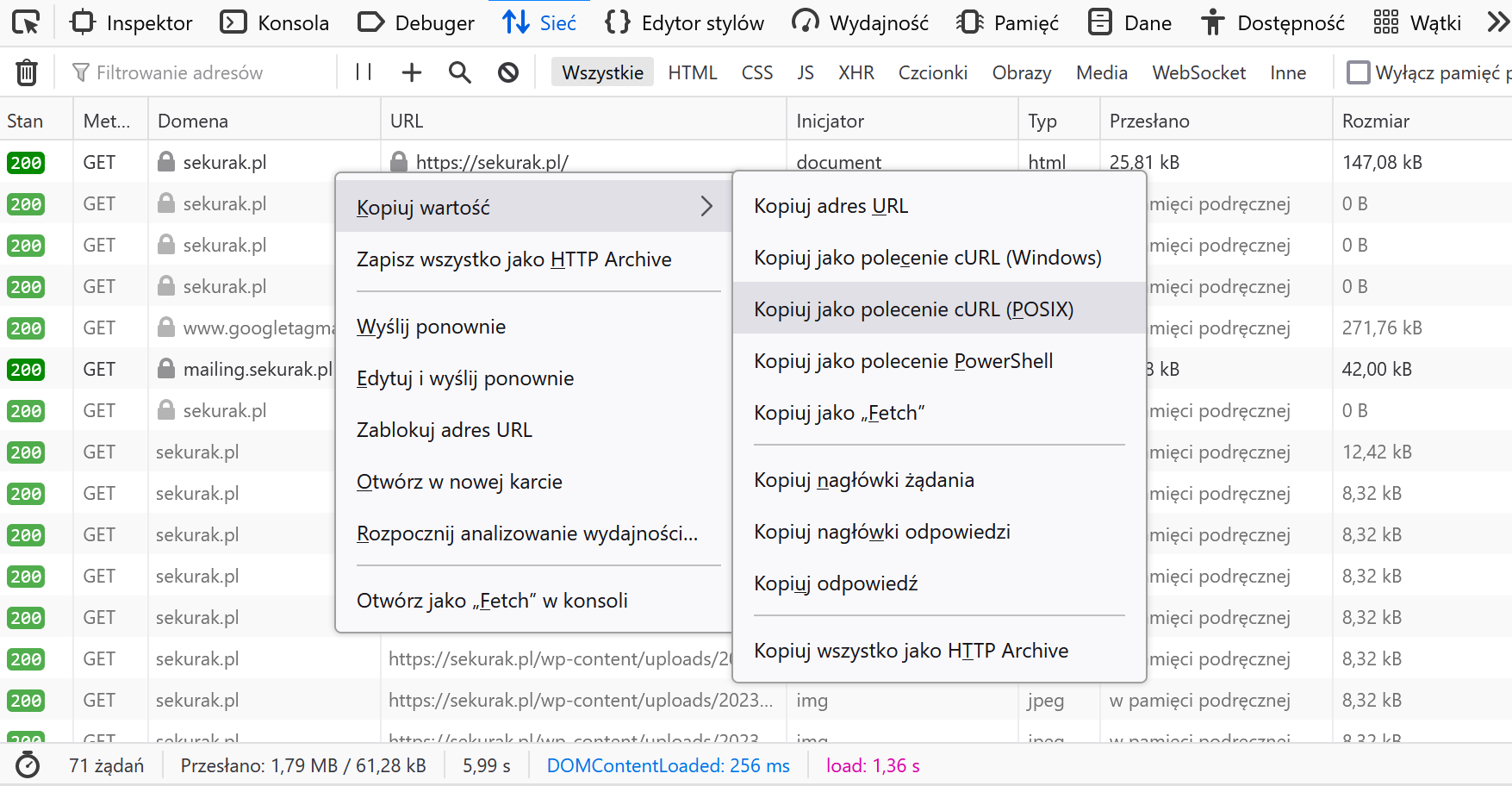
Następnie otwieramy stronę z poręcznym translatorem poleceń curla do poleceń konfiguracyjnych Scrapy: michael-shub.github.io/curl2scrapy/. Wklejamy do lewego panelu żądanie z przeglądarki. Widzimy, że tym razem automat będzie przedstawiać się jako desktopowy Firefox dla Windows.
Teraz wystarczy skopiować te wartości do pliku settings.py naszego projektu i gotowe.
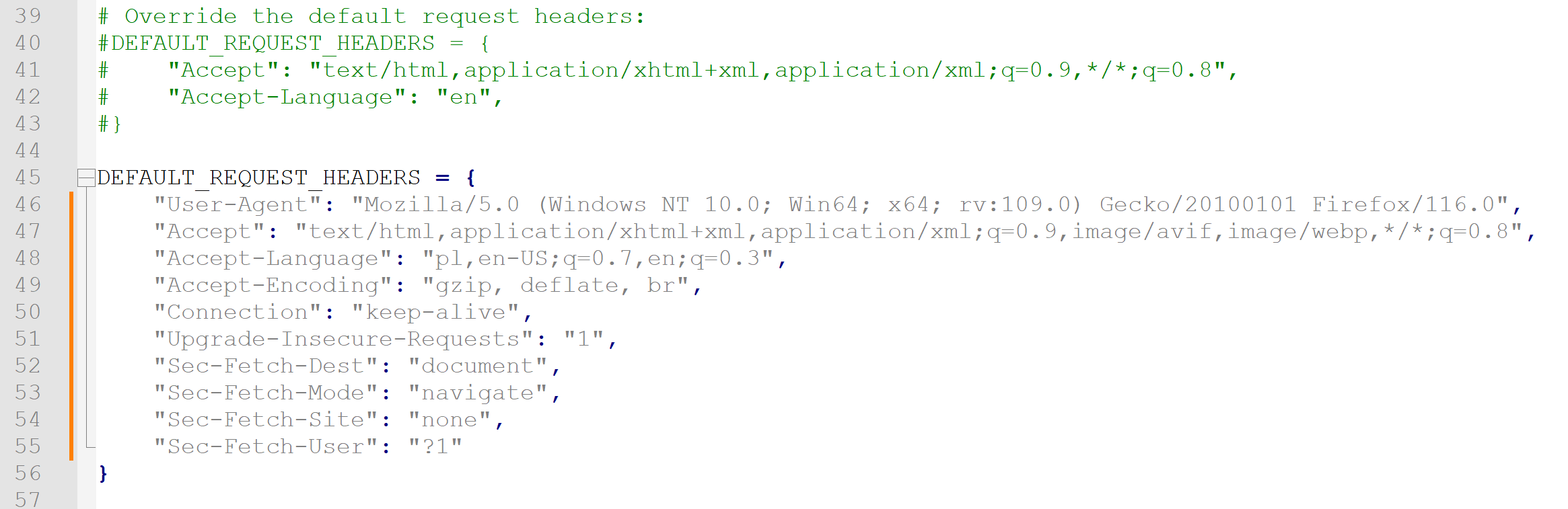
Ban Sekuraka przestał działać dopiero następnego dnia. Za pomocą RequestBin upewniłem się, że nagłówki są zgodne z oczekiwaniami, po czym ponowiłem próbę scrapowania. Kilkadziesiąt ekranów głównego spisu treści wjechało bez problemów, jednak po dwustu ekranach sekcji „W biegu”… znowu zostałem zablokowany! Tym razem poległem na zbyt dużej liczbie żądań, choć przecież Scrapy gotów był dostosować się do wymogów pliku robots.txt (gdyby Sekurak coś tam miał).
Pobieranie danych z Sekuraka dokończyłem dopiero trzeciego dnia, kiedy – dzięki pauzom w scrapowaniu – ostatecznie udało mi się pozyskać komplet artykułów.
Czy zawsze damy radę zescrapować dane?
Po pierwsze – jeśli nadal czytasz ten tekst, może zainteresować cię „Szkolenie z automatyzacji pobierania danych z internetu” – moje bestsellerowe szkolenie, które przyniosło do tej pory ćwierć miliona złotych przychodu. Kliknij i sprawdź spis treści, to ponad 9 godzin nagrań wideo pełnych wiedzy! Jedyne w tym roku okienko sprzedażowe otworzy się we wrześniu i potrwa dziesięć dni. Zapisz się na newsletter, aby nie przegapić tego terminu!
Po drugie – im szybciej chcesz pobierać dane oraz im większy ich zakres zechcesz pozyskać, tym łatwiej będzie cię powstrzymać.
Aby było jasne – trudno jest samodzielnie przygotować taką ochronę przed scrapowaniem, która oprze się „bezgłowym” przeglądarkom działającym z rozsądnymi opóźnieniami. Autorzy serwisów internetowych nie są jednak osamotnieni, z pomocą przychodzą m.in. tacy giganci, jak Cloudflare. Zainteresowanym polecam niedawny artykuł Troya Hunta pt. „Fighting API Bots with Cloudflare’s Invisible Turnstile” opisujący, jak ochronić przed botami wyszukiwarkę na stronie WWW dostępnej bez uwierzytelniania.
Jak analizować dane?
Scrapowanie dostarczyło nam tysiące par [data publikacji, objętość publikacji] dla każdego z trzech wspomnianych serwisów. Do analizy użyłem języka R i środowiska RStudio. Jeśli nie interesują cię szczegóły, przeskocz do rozdziału z wynikami.
Oto sekwencja przeprowadzonych operacji.
Najpierw przygotowałem ramkę danych z osobnym wierszem dla każdego dnia z opisywanego zakresu.
datestart = min(nbzp$date, z3s$date, sekurak$date)
dateend = max(nbzp$date, z3s$date, sekurak$date)
dane <- data.frame(date = seq(datestart, dateend, by='1 day'))Następnie połączyłem tę ramkę ze zbiorami informacji o publikacjach. Był to odpowiednik trzykrotnego SQL-owego lewego złączenia (w ramce danych nadal są wiersze reprezentujące dni bez żadnej publikacji).
dane <- merge(dane, nbzp, all.x = T)
dane <- merge(dane, z3s, all.x = T)
dane <- merge(dane, sekurak, all.x = T)Potem obliczyłem sumy kroczące oraz sumy kumulacyjne dla każdej z prezentowanych kategorii danych:
dane$nbzp_n_roll100 <- rollsum(dane$nbzp_n, k = 100, fill = NA, align = 'right')
dane$nbzp_n_cumsum <- cumsum(dane$nbzp_n)Teraz wystarczyło już tylko utworzyć i zapisać do pliku wykresy, oto kod odpowiedzialny za pierwszy wykres z następnego rozdziału
dane %>%
ggplot(aes(x=date)) +
geom_line(aes(y=nbzp_n_roll100, colour="Niebezpiecznik"), size = 1.5, ) +
geom_line(aes(y=z3s_n_roll100, color="Zaufana trzecia strona"), size = 1.5) +
geom_line(aes(y=sekurak_n_roll100, color="Sekurak"), size = 1.5) +
scale_color_manual(name = "Serwis", values = c("Niebezpiecznik" = "red", "Zaufana trzecia strona" = "blue", "Sekurak"="darkgreen")) +
labs(title = "Średnia liczba publikacji podczas 100 poprzednich dni", y="Blogonotki", x=NULL) +
scale_x_date(breaks = "2 years", minor_breaks = "years", date_labels = "%Y", limits = c(dmy("01-09-2009"), NA)) +
theme_light()
ggsave("wykres1.png", width = 2000, height = 1200, units = "px", dpi=200)Jeśli spodobał ci się taki sposób pracy z danymi, dołącz do darmowego programu edukacyjnego „Poradnik dla sponiewieranych Excelem”. Nauczysz się, jak w sposób szybki i powtarzalny analizować i wizualizować dane przy użyciu języka R.
Analizujemy produktywność Wielkiej Trójki
Pisanie bloga jest łatwe. Systematyczne pisanie bloga jest trudne. Systematyczne pisanie bloga przez wiele lat jest cholernie trudne.
Uwaga – nie wszystkie blogonotki są sobie równe. Kilka słów opisujących ciekawy odnośnik na linkblogu to nie to samo, co sążnisty tekst zajmujący kilkanaście ekranów. Na potrzeby niniejszej analizy obrałem więc całkowicie arbitralne kryterium istotności tekstu – do statystyk włączyłem tylko publikacje mające długość nie mniejszą niż 512 znaków. Mając to na uwadze, spójrzmy na produktywność opisywanych serwisów od początku ich istnienia.
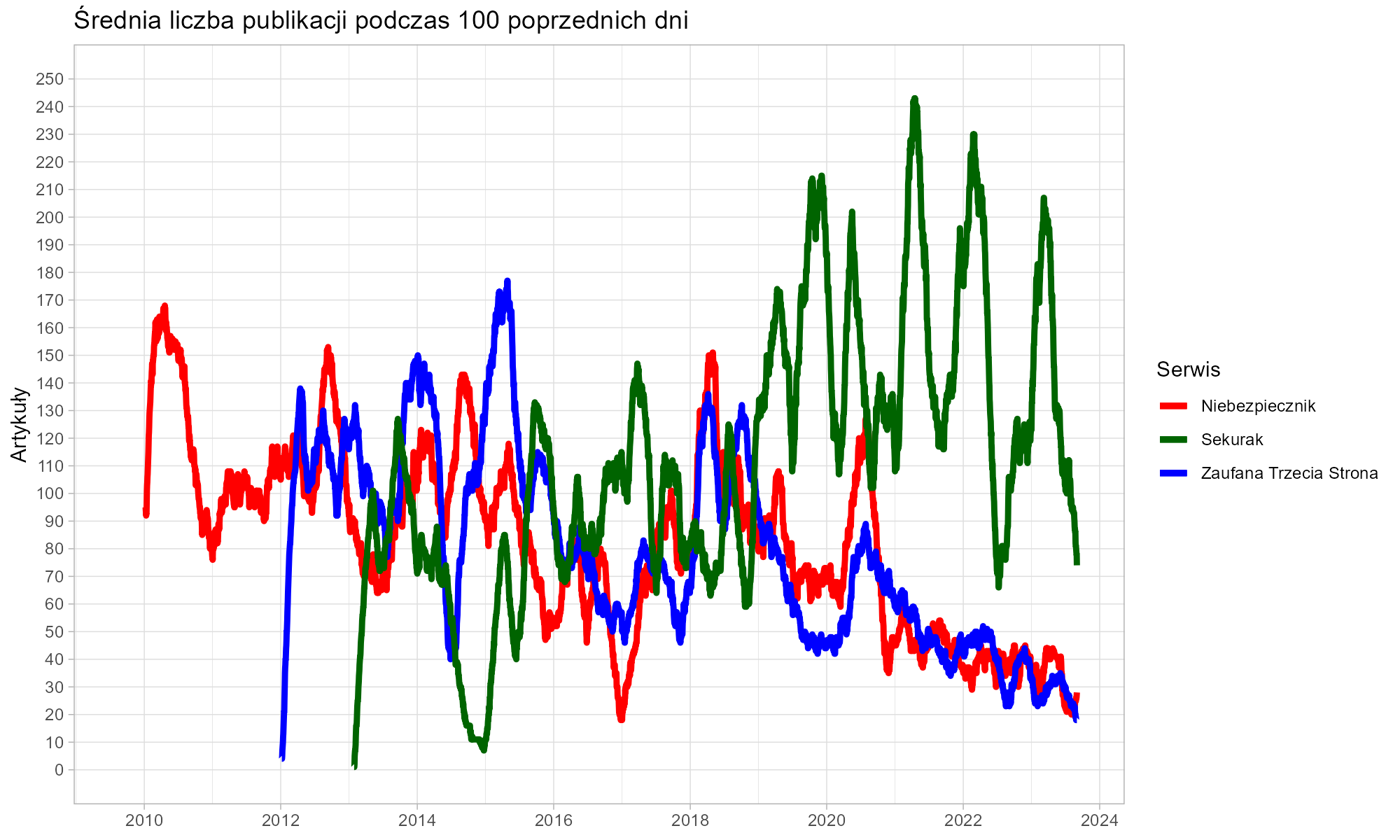
Niebezpiecznik, który wystartował w roku 2009, przez pierwsze trzy lata istnienia utrzymywał wydajność przekraczającą jedną notkę dziennie, co samo w sobie jest dużym osiągnięciem. Potem palma pierwszeństwa wielokrotnie przechodziła z rąk do rąk, jednak od 2019 roku bezdyskusyjnym liderem pozostaje Sekurak, który wielokrotnie przebijał granicę 200 publikacji w ciągu 100 dni.
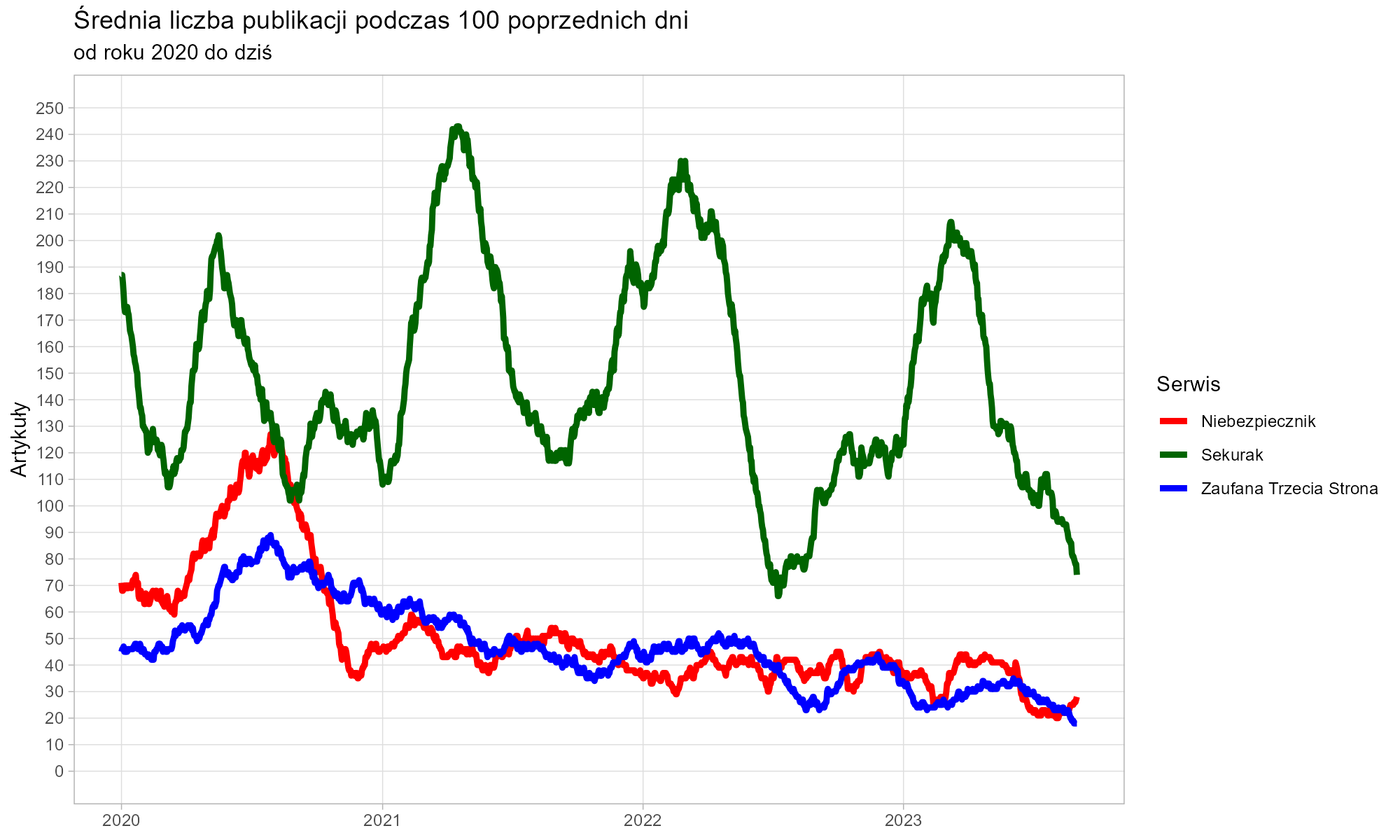
Czy jednak liczba publikacji przekłada się na ich objętość? Wszechobecna portaloza uczy nas, że nawet dwa zdania z jednym stockowym zdjęciem mogą być traktowane jak osobny „artykuł”. Spójrzmy więc na liczbę znaków składających się na wszystkie publikacje.
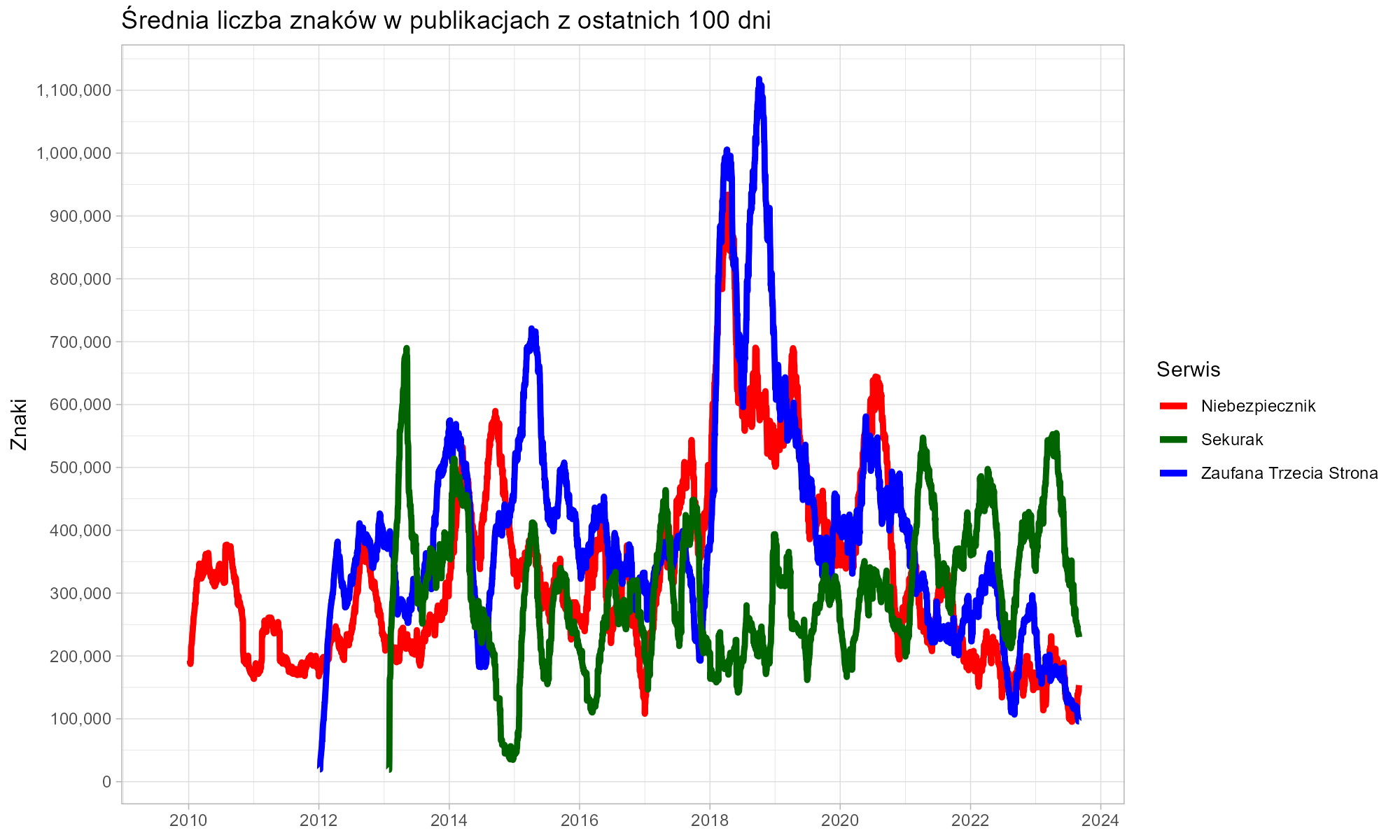
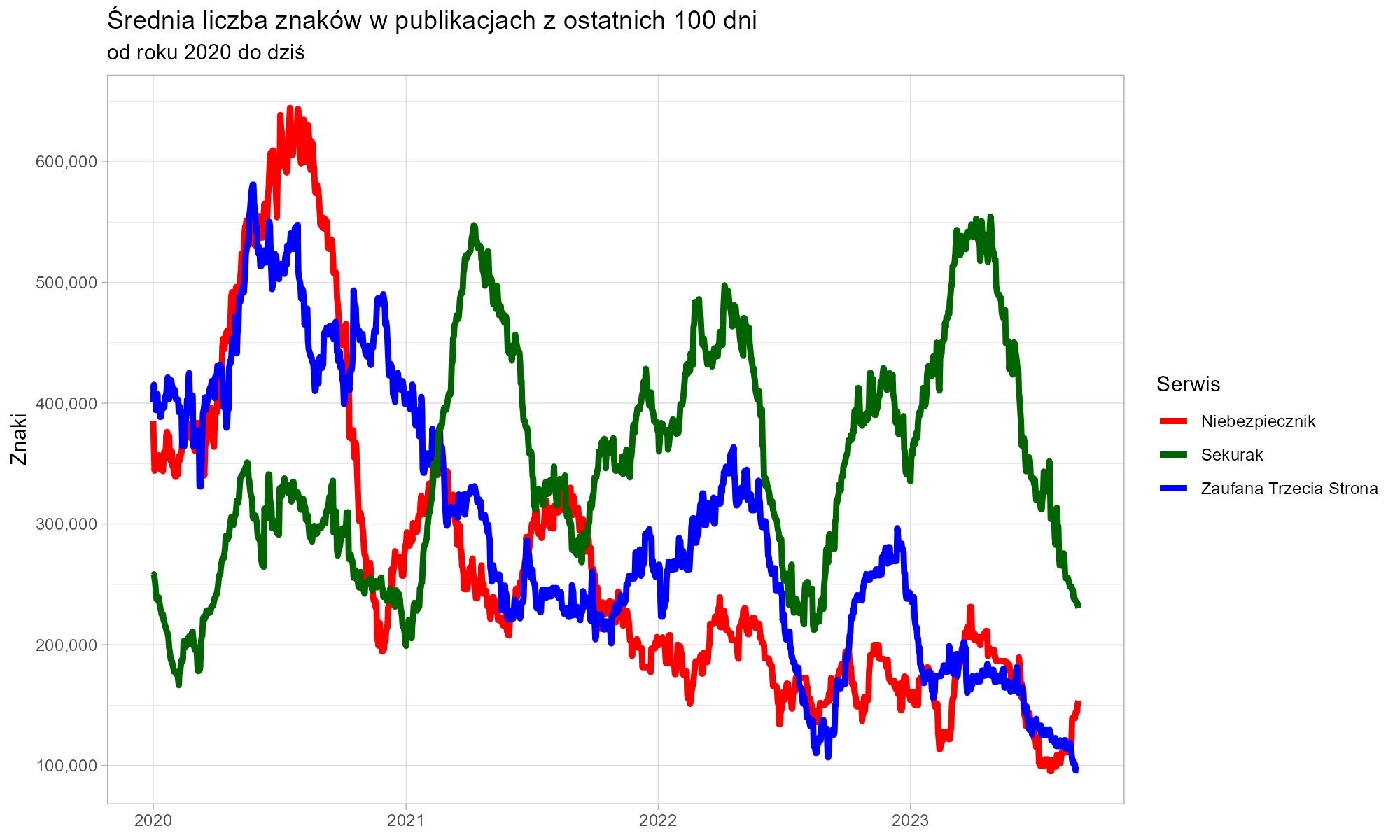
Szczególną uwagę przyciąga produktywność redaktora Zaufanej Trzeciej Strony około roku 2018. Ponad trzy miliony znaków opublikowane w tym okresie to wydajność godna Remigiusza Mroza. Nawet biorąc pod uwagę, że pewną część stanowiły redagowane, cudze teksty, obserwowaliśmy pracę iście tytaniczną.
Bardziej typowa wydajność obserwowana w dłuższym okresie to jednak nadal ponad dwie strony znormalizowanego maszynopisu dziennie. I tak przez kilkanaście lat.
Podsumowanie
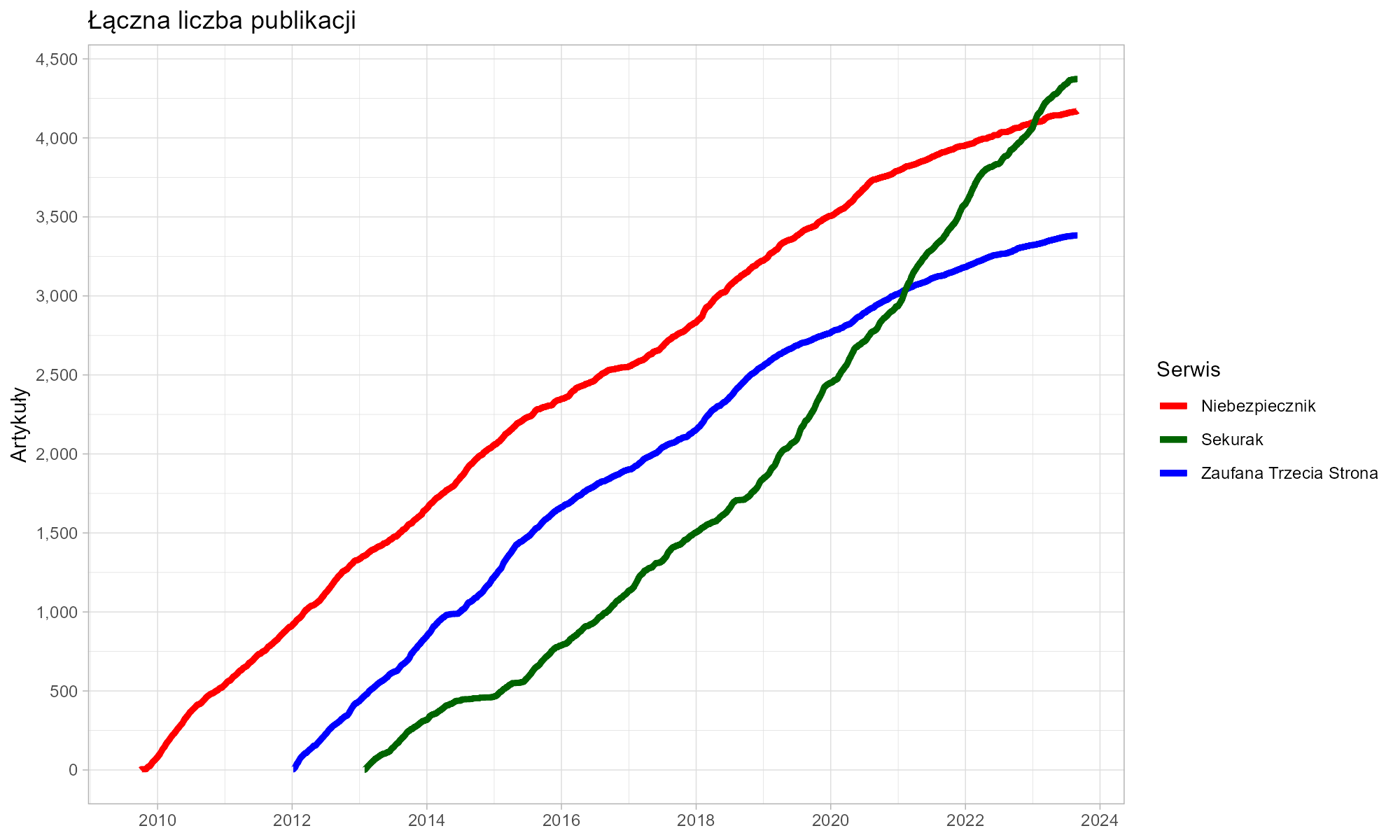
Ile artykułów mogliśmy przeczytać przez minione kilkanaście lat?
- Sekurak – 4373
- Niebezpiecznik – 4171
- Z3S – 3383
Wróćmy teraz do początkowego pytania – jak zmierzyć przekazywaną wiedzę? Może przeliczyć objętość tekstów na tomy encyklopedii? Gdy twórcy Wikipedii postanowili wyrazić rozmiar swych angielskojęzyczych materiałów w liczbie tomów encyklopedii, przyjęli przelicznik wynoszący 8 milionów znaków na jedną 500-stronicową fizyczną księgę.
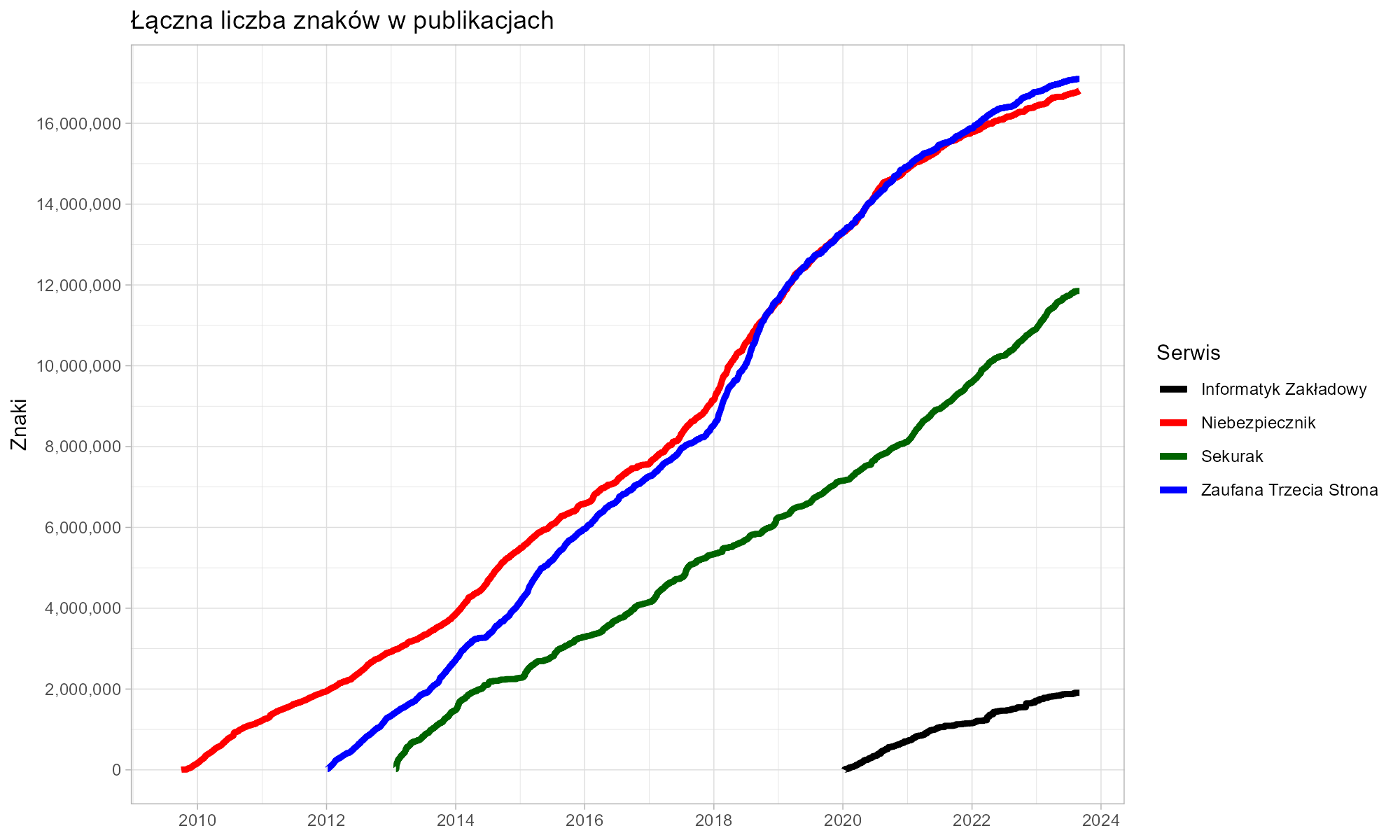
Tym samym dowiadujemy się, że Niebezpiecznik i Zaufana Trzecia Strona podarowały nam wiedzę, której objętość przekracza łącznie cztery tomy encyklopedii. Kolejne półtora tomu to dzieło Sekuraka. Wszystkie teksty złożyły się na łączną objętość ponad 45 milionów znaków.
Czapki z głów!
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

14 odpowiedzi na “Niebezpiecznik, Zaufana Trzecia Strona, Sekurak – analiza dynamiki publikacji”
Jeśli mi to umknęło podczas czytania artykułu, to przepraszam, ale zastanawia mnie czemu akurat scraping, a nie np. skorzystanie z WordPress REST API lub wykorzystanie endpointa dla RSS? Z tego co sprawdziłem, to wszystkie trzy strony wystawiają zarówno końcówkę dla pobierania postów `wp-json/wp/v2/posts` jak i dla RSS `/feed`. Domyślam się, że może to mieć związek z większym nakładem pracy, ale niewykluczone, że pozwoliłoby to np. obejść opisany problem z Sekurakiem. Skorzystanie z powyższych opcji nie wymaga też sprawdzania kodu HTML strony.
Anyway, bardzo ciekawy artykuł i fajnie dowiedzieć się czegoś nowego. Mogę dodać jeszcze ciekawostkę, że X (Twitter) również lubi robić problemy scraperom 😉
Głównym powodem była chęć pokazania dedykowanego scrapera, bo np. curl już się tu wcześniej pojawiał
Ja tam te wszystkie WordPressowe API blokuję, gdzie tylko mogę. Wystarczy kilka linijek w konfiguracji vhota i zwracają 403. Prawie nikt tego nie używa, oprócz skanów oraz indeksowania treści.
Polecam blokować dostęp nie tylko wp-admin, ale też wp-login.php, wp-json oraz xmlrpc.php . Tak na spokojny sen.
Ciekawa wrzutka. Super, że mamy takich specjalistów dzielących się wiedzą w Polsce. Wydaje mi się, że te serwisu uzupełniają się. Każdy o security, a jednak o innej części. Mega robią dobrą robotę. Mateusz Chrobok jeszcze publikuje wiadomości ze świata security, ale on bardziej na youtube.
Cześć. Czy mógłbyś poruszyć kwestie logowania się na cudze konta? Po kilku miesiącach uruchomiłem ponownie aplikację tiktok, wymagała aktualizacji i zalogowania. Po odzyskaniu hasła via @ i sms zostałem zalogowany na cudze konto.
Tomek, dzięki za artykuł!
Przeczytałem do poranne kawy. Brawo dla Top3, ale również dla Ciebie, bo tworzysz content, który jest bardzo dobry jakościowo i zupełnie inny niż artykuły z Z3S, Sekuraka czy Niebezpiecznika.
A myślałem że jestem dziwny że uważam Pythona za brzydki język (z nielicznymi wyjątkami). Długo zajęło mi żeby przełamać obrzydzenie, ale dostęp do całej masy wspaniałych pakietów okazał się wystarczająco silnym argumentem.
Do tego trzeba jeszcze pamiętać, iż branża też nie raz określa jak dużo można publikować. W security ciężko pisać, jak nie będzie wpadek, wykrywanych luk itp.
procz wp api spoko dziala jeszcze… parsowanie sitemapy ;))
Sitemapy też są hierarchiczne, więc tak naprawdę byłoby to bardzo podobne do parsowania stron ze spisem treści
Cała analiza super! Bardzo lubię, jak podejmuje się takie tematy! Czy będziesz jeszcze robił kiedyś takie rzeczy w przyszłości?
Raczej tak, a jeśli Ci się podobało, to rzuć okiem na https://sponiewierani.pl/
Śpieszę z pomocą, tak na przyszłość. W C# też da się napisać web-crawler z użyciem tego nugeta (nugetu?) https://www.nuget.org/packages/Abot, jest on dość rozbudowany nawet jak na darmową wersję 😀
Bardzo ciekawie było przeczytać tę analizę. Szczególnie, że:
*Twoją stronę poznałem dzięki z3s,
*Wiele lat spędziłem czytając z3s do poduszki,
*Fascynowały mnie te fabularyzowane, szpiegowskie historie na z3s, którymi ongiś raczyła nas płeć piękna,
*Z żalem zauważyłem przed laty jak N i z3s upodobniły się do siebie treściami
*z3s stała się li tylko linkownią dla branżowych
*oba portale jakby przeistoczyły się w byt istniejący tylko po to aby sprzedać szkolenia
*i tak, szukając lekkich treści do poduchy, po rocznej lekturze Panoptykonu przeniosłem swoje bezsenności do Ciebie 🙂