
To jest archiwalna wersja strony informacyjnej szkolenia. Przejdź na stronę scrapowanie.pl
Znajomość komend wget i curl to za mało, gdy w grę wchodzą miliony żądań i miliony plików
Poznaj sekrety efektywnego scrapowania i obróbki danych! Szkolenie prowadzi Tomasz Zieliński, autor bloga Informatyk Zakładowy

Nauczysz się:
- pisać niezawodne skrypty i automaty
- monitorować ich działanie
- wykrywać anomalie w pobieranych danych
- zarządzać zbiorami danych o zróżnicowanym wolumenie, od tysięcy po miliardy rekordów
Poznasz:
- sposoby na efektywne scrapowanie i omijanie mechanizmów wykrywających roboty
- najczęstsze problemy podczas parsowania formatów TXT, CSV, TSV, JSON, XLS, PDF
- typowe błędy parsowania i sposoby na ich uniknięcie
- metody wykrywania wąskich gardeł spowalniających przetwarzanie danych
- sztuczki pozwalające na efektywniejszą realizację zadań
Szkolenie jest dostępne w formule online, nagrania wideo i materiały dodatkowe są opublikowane na platformie szkoleniowej dostępnej przez przeglądarkę internetową.
Do kogo kierowane jest szkolenie?
Jeśli jesteś
- programistą odpowiedzialnym za automatyzację procesu przetwarzania danych
- analitykiem znużonym regularnym pobieraniem i ręcznym przetwarzaniem plików
- pracownikiem wywiadowni gospodarczej szukającym ukrytych informacji
- ekonomistą agregującym raporty z różnych źródeł
… to szkolenie może być właśnie dla ciebie! Zerknij do spisu treści poniżej!
Co można zrobić mając wiedzę ze szkolenia?
Umiejętne scrapowanie danych może prowadzić do wielu interesujących odkryć. Oto trzy moje publikacje oparte o dane pobierane z internetu:
1. Analiza aktywności wypożyczalni samochodów elektrycznych Vozilla (252 tysiące plików, 30 milionów obserwacji)
Przez pół roku co minutę pobierałem informacje o dostępności samochodów w nieistniejącej już wrocławskiej wypożyczalni Vozilla. Mając do dyspozycji jedynie te dane byłem w stanie wyznaczyć rzeczywisty zasięg Nissanów Leaf w jeździe miejskiej, określić zależność zasięgu od temperatury, wyznaczyć godziny szczytu a nawet oszacować dzienne przychody wypożyczalni.
Zapraszam do lektury raportu (format PDF)
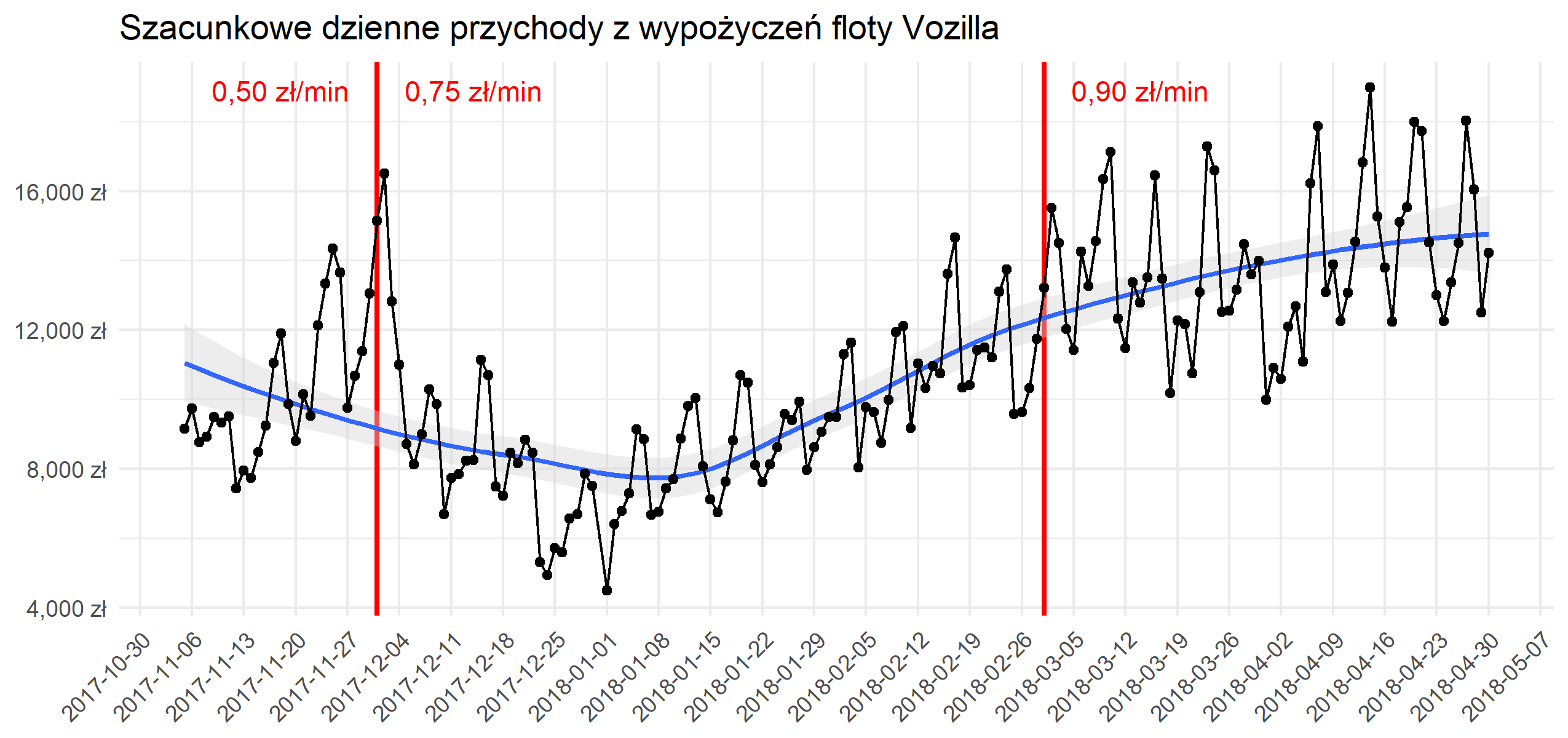
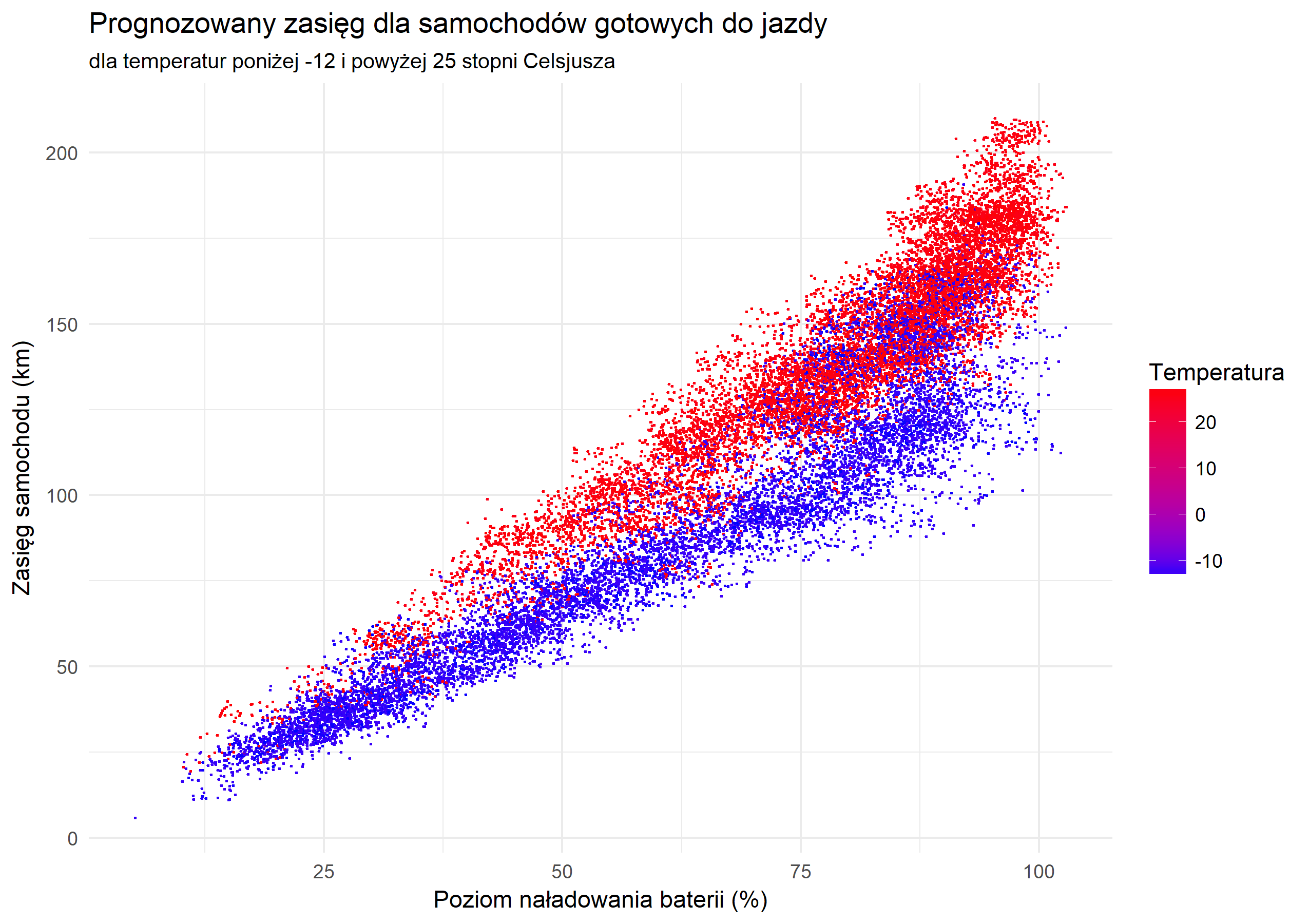
2. Wykorzystanie danych o wypożyczeniach aut Traficara do budowy modelu predykcyjnego (milion plików, 100 milionów obserwacji, miliard punktów danych)
W oparciu o dane scrapowane przez 22 miesiące przygotowałem predykcyjny model Machine Learningowy przewidujący utylizację floty Traficara w zależności od pory dnia, dnia tygodnia i sezonowości rocznej. Średni błąd predykcji nie przekraczał 2.5 punktu procentowego, co było niezłym wynikiem. Tutaj blogonotka (po angielsku) opisująca procesu modelu ML, poniżej wizualizacja predykcji na tle rzeczywistej aktywności floty podczas jednej doby.
3. Analiza popularności serwisu Albicla
Kilka sztuczek wystarczyło, by pobrać wszystkie publiczne posty oraz utworzyć listę wszystkich aktywnych użytkowników sieci społecznościowej Albicla. Na tej bazie przeprowadziłem analizę w której ujawniłem m.in. systematyczny spadek liczby zakładanych kont oraz malejącą liczbę aktywnych użytkowników (przy – ciekawostka – w miarę stabilnej liczbie wpisów i komentarzy).

Jednym z cenniejszych elementów szkolenia jest lista moich wpadek, napotkanych problemów i nieprzewidzianych trudności – wiele z nich cofało mnie o długie godziny i dni pracy. Gdybym usłyszał to, co wiem teraz, przed rozpoczęciem pracy nad Vozillą, raport powstałby dobre dwa tygodnie wcześniej…
Co trzeba umieć?
Większość narzędzi prezentowanych podczas szkolenia będzie uruchamiana z wiersza poleceń, konieczne będzie choćby minimalne doświadczenie w jego użyciu. Wykorzystamy też skrypty powłoki – pliki BAT uruchamiane z linii komend Windows albo skrypty bash pod Linuksem (wystarczy znać jeden z tych systemów). Musisz wiedzieć, czym są pliki i foldery.
Mile widziana – choć niekonieczna – jest umiejętność programowania w dowolnym języku. Warto mieć ogólne pojęcie, co to jest HTML, HTTP, CSV czy XML, ale w programie szkolenia znajdzie się lekcja dla mniej zaawansowanych, wprowadzająca wszystkie wymagane pojęcia.
Idealny uczestnik scrapował już dane i napotykał problemy – teraz chciałby dostać sprawdzone receptury.
Historia szkolenia
Pierwsza edycja w roku 2021 była nadawana na żywo. Edycja druga z roku 2022 została zarejestrowane i opublikowana w platformie edukacyjnej dostępnej przez przeglądarkę. Dzięki tej zmianie w szkoleniu obecne są bardziej złożone przykłady i demonstracje. Podział na osobne lekcje ułatwia dostęp do wybranych nagrań, dostępne są linki do prezentowanych narzędzi i przykładowe pliki do samodzielnych ćwiczeń.
Treść szkolenia została wzbogacona o nowe narzędzia i dodatkowe przykłady. Demonstruję, jak unikać powtarzania już zrealizowanych zadań i jak wznawiać przetwarzanie od wybranego kroku. Inną nowością jest prosty scraper w modelu serverless, zrealizowany w chmurze AWS.
W pierwszej edycji duże zainteresowanie wzbudził fragment o ustawach i przepisach prawa, dostałem kilka pytań dotyczących legalności scrapowania różnego rodzaju danych. Jedyne, co mogłem odpowiedzieć, to „idź do prawnika”. W edycji drugiej prawnik przyszedł do nas, o wypowiedź ekspercką poprosiłem radcę prawnego Mirelę Perczak. Dowiadujemy się, dlaczego przeczytanie kilku ustaw nie wystarczy programiście do zrozumienia systemu prawnego i dlaczego warto odwiedzić zawodowego prawnika zanim zrobimy coś głupiego.
W roku 2023 sprzedawana była druga edycja szkolenia. Kolejne okienko sprzedażowe zostanie otworzone w roku 2025. Zapisz się na newsletter, aby go nie przegapić!
Jak wygląda typowy rozdział szkolenia?
Oto darmowy rozdział pt. „Scrapowanie długoterminowe” z obecnej edycji szkolenia (czas trwania: 50 minut). Sprawdź, czy styl i tempo przekazywania wiedzy są dla ciebie odpowiednie.
Spis treści szkolenia
- Wstęp (27 minut)
- Omówienie zakresu szkolenia
- Zagadnienia prawne (46 minut)
- Ustawy, które warto poznać przed scrapowaniem
- Ustawa o dostępie do informacji publicznej
- Ustawa o otwartych danych i ponownym wykorzystywaniu informacji sektora publicznego
- Ustawa o prawie autorskim i prawach pokrewnych
- Ustawa o ochronie baz danych
- Rozdział XXXIII Kodeksu Karnego
- Informacja publiczna do ponownego wykorzystania
- Rozmowa z radcą prawnym – dlaczego o interpretację przepisów warto zapytać prawnika i dlaczego lepiej zapobiegać problemom (prawnym) niż je potem odkręcać
- Ustawy, które warto poznać przed scrapowaniem
- Podstawy protokołu HTTP (58 minut)
- komendy HTTP
- żądanie
- odpowiedź
- nagłówki
- ciasteczka
- F12 w przeglądarce
- Fiddler / Charles
- timeouty
- Rekonesans i dobre wychowanie (31 minut)
- Jak się rozglądać i czego szukać
- Jak być dobrym robotem
- Jak być dobrym obywatelem
- Podstawy scrapowania (41 minut)
- Wady i zalety różnych formatów: TXT/CSV/TSV/JSON/YAML/XML/XLS/PDF
- W pierwszej edycji PDF był wymieniony dla jaj, ale… czasem PDF-y dają się sensownie parsować, w drugiej edycji demonstruję kilka stosownych narzędzi
- Zastosowania różnych formatów, ramka danych kontra struktura drzewiasta
- Locale i dlaczego ich nie znosimy
- REST kontra GraphQL kontra surówka
- Enumeracja zasobów
- Efektywne scrapowanie (58 minut)
- linia komend – curl czy wget
- kilka przydatnych sztuczek curla
- klonowanie zapytań z przeglądarki / proxy
- NAJWAŻNIEJSZY trik dotyczący curla
- HTTP2 i HTTP3 – co nam dają
- co trudno zrobić w skryptach
- metody zaawansowane – headless Chrome, puppeteer
- Scrapowanie długoterminowe (50 minut)
- jak scrapować API co minutę przez 20 miesięcy
- alarmy, gdy coś nie działa (z przykładami „zrób to sam” i SaaS)
- mój skrypt, którym scrapowałem Vozillę i Traficara
- krótko o cronie
- skąd wziąć serwer z shellem
- zużycie dysku i dlaczego nasz dostawca shella może nas nie polubić
- przykład scrapowania serverless w chmurze AWS
- Uwierzytelnianie (33 minuty)
- jak zrobić, żeby skrypt udawał człowieka
- basic auth, cookie, tokeny, refresh tokeny i reszta
- MAC/HMAC/JWT
- mutual authentication
- Sposoby na omijanie limitów ruchu (34 minuty)
- typy blokad i dławików
- skąd wziąć wiele IP
- co jest gorsze od blokady
- jeszcze raz o udawaniu przeglądarki
- wykrywaczki robotów, captcha
- wyciąganie tokena z apki mobilnej
- Organizacja pobranych plików (48 minut)
- ile plików to za dużo plików?
- gdzie i jak trzymać milion plików?
- jak przetwarzać pliki mające 10 MB, 100 MB, 1 GB, 10 GB, 100 GB, 1 TB
- na co trzeba uważać gdy pliki są duże lub za duże
- czym edytować za duże pliki
- kompresja – czym, dlaczego, kiedy
- jak synchronizować i jak pobierać pliki
- Organizacja przetwarzania danych (44 minuty)
- Co zbierać, co kasować, co porzucać
- Weryfikacja tego, co zapisano
- Jak zrozumieć dane
- Wykrywanie usterek i anomalii
- Eksperymentowanie oraz automatyzacja
- Przykład iteracyjnej analizy i pobierania
- Na jak dużej próbce danych pracować
- NAJWAŻNIEJSZA porada dotycząca przetwarzania
- Dane nie mieszczą się w pamięci – co teraz? Trzy rozwiązania!
- Optymalizacja przetwarzania (21 minut)
- HDD kontra SSD w praktyce
- CPU-bound kontra I/O-bound
- Porady dotyczące wielowątkowości
- Narzędzia, które warto znać (39 minut)
- kilkanaście metod wyciągania danych z różnych formatów
- kilkanaście mało znanych narzędzi, które bardzo w tym pomogą
- łączenie metod i narzędzi, od szczegółu do ogółu
- Pułapki i sztuczki (18 minut)
- wszystko, co nie zmieściło się w poprzednich rozdziałach
Łącznie nagrania wideo trwają ponad 9 godzin.
Opinie uczestników
Szkolenie MEGA! Merytorycznie bomba, ekspertem nie jestem i długo nie będę ale szkolenie porządnie poszerzyło horyzonty, usystematyzowało wiedzę, warte swojej ceny na 100%, a do niektórych slajdów i filmu offline wracam co jakiś czas.
Tomek fajnie wplata różne poboczne narzędzia i rozwiązania, które potem rozkminione dokładniej – same w sobie stają się bardzo dużą pomocą w pracy: slido, cronitor.io, wolframalpha, bonjoro, hubspot, selenium, dreamhost itd. Po każdym jego kursie moja baza z listą kolejnych tematów do zgłębienia powiększa się o 25 nowych rekordów 😊
Wskazówka o ustawianiu strefy czasowej zawsze na UTC – bezcenna 👌
Bardzo dobre i wartościowe szkolenie z niecodzienną ceną (przez co było dostępne praktycznie dla każdego). Świetnie przemyślana treść, ułożona w logiczny ciąg. Prowadzący chętnie dzieli się swoimi doświadczeniami i wplata dygresje (cały czas pozostając w tematyce około szkoleniowej). Wykład zawierał również szybki pokaz możliwości niektórych narzędzi lub po prostu sygnalizował istnienie danego rozwiązania, zachęcając do samodzielnej pracy z np. dokumentacją (bardzo ważna umiejętność).
Sama organizacja szkolenia na wysokim poziomie. Dobry kontakt z organizatorem, odpowiednia jakość audio i video. Czytelna prezentacja bez zbędnych wodotrysków (udostępniona po szkoleniu) z zaznaczonymi najważniejszymi rzeczami oraz masą linków. Jednym słowem polecam!
Szkolenie w sposób jasny i ciekawy objaśnia podstawy scrapingu, uczy dobrych praktyk i wskazuje kierunek osobom, które chcą rozwijać swoją wiedzę w tym temacie. Prowadzący to człowiek z potężnym doświadczeniem, którym chętnie się dzieli. Polecam.
Model biznesowy zasugerował wysoką jakość szkolenia, a wiedza prelegenta tylko ją potwierdziła. Bardzo polecam wszystkim tym, którzy w danym temacie mają odrobinę wiedzy, ale z jakichś względów nie mogą przejść dalej – szkolenie na pewno pobudzi chęć do dalszego rozwijania w danym kierunku
Cena szkolenia = twoja dniówka
Szkolenie kosztuje twoją jedną dniówkę. Czemu tak dziwnie? Zdobyta wiedza pozwoli ci zaoszczędzić co najmniej dzień pracy, więc życzę sobie dostać właśnie tyle. Gdybym od początku miał wiedzę, którą teraz się dzielę, sam zaoszczędziłbym całe tygodnie…
To jest archiwalna wersja strony informacyjnej szkolenia. Przejdź na stronę scrapowanie.pl
Oczywiście nie musisz przedstawiać żadnego zaświadczenia o zarobkach – w koszyku sam podasz odpowiednią kwotę. Jeśli pracujesz na etacie, zapłać 1/20 swojej pensji brutto; jeśli B2B, cena wynosi jedną dniówkę lub osiem stawek godzinowych. Gdy nie możesz lub nie chcesz zdradzać zarobków, zaokrąglij tę kwotę w górę.
Gdy przejdziesz do koszyka, cena domyślnie ustawiona będzie na kwotę 725 zł (z VAT) – odpowiada to pensji 14500 zł brutto. Tyle – wg raportu o płacach serwisu JustJoinIT – zarabiał w roku 2022 przeciętny middle developer. A płace od tamtego czasu wzrosły!
Minimalna cena szkolenia w przedsprzedaży to 375 zł (z VAT), co odpowiada pensji 7500 zł brutto. Tyle wynosiła średnia pensja początkującego developera.
Uwaga – NIGDY nie będzie taniej. A w 2025 będzie drożej.
Największa kwota, jaką jeden z uczestników zapłacił za udział w roku 2021, wyniosła 2000 zł (pensja rzędu 40000 zł). W roku 2022 było to 1000 Euro (tak, można dostać fakturę w Euro).
Dostęp do szkolenia
Po zakupie otrzymasz fakturę VAT i dane dostępowe do platformy szkoleniowej. Komplet materiałów jest dostępny do razu, możesz zaczynać naukę natychmiast po dokonaniu transakcji.
To jest archiwalna wersja strony informacyjnej szkolenia. Przejdź na stronę scrapowanie.pl
W roku 2023 miało miejsce jedno okienko sprzedażowe, które potrwało ok. 10 dni. Kolejna możliwość kupienia szkolenia pojawi się dopiero w 2025.
Gwarancja satysfakcji
Jestem pewny wysokiej jakości szkolenia, więc dostajesz gwarancję satysfakcji. Jeśli uznasz, że szkolenie nie było warte zapłaconej ceny, dostaniesz zwrot pieniędzy. Bez zadawania pytań, bez żalu ani wyrzutów. Na taką decyzję będziesz mieć 14 dni od zakupu.
Ty niczym nie ryzykujesz!
Całość ryzyka biorę na siebie. W dwóch pierwszych edycjach szkolenia o zwrot poprosiło dokładnie siedem osób.
Wynik finansowy szkolenia
W latach 2021-2023 szkolenie przyniosło ponad 330 tys. złotych, na zakup zdecydowało się ponad 800 osób. O wszystkich szczegółach przeczytasz w tej blogonotce (edycja 2021) oraz tej blogonotce (edycja 2022). Jeśli chcesz dowiedzieć się, jak zamieniłem blogowanie w źródło niezłych dochodów, przeczytaj teksty opublikowane w kategorii Statystyki.
Najczęściej zadawane pytania
Czy będą jakieś zniżki dla uczniów, studentów lub bezrobotnych?
Nie. To specjalistyczne szkolenie kierowane głównie do branży IT.
Cena minimalna to więcej, niż moja dniówka. Czy kupię szkolenie taniej?
Nie. Cena jest dopasowana do możliwości grupy docelowej.
Czy można kupić szkolenie na raty?
Nie. Jeśli musisz zadłużyć się aby opłacić szkolenie, to raczej masz pilniejsze wydatki. Odłóż udział w szkoleniu na przyszłość, będą kolejne edycje.
Czy na Black Friday będzie taniej? Albo na Mikołajki albo w przyszłym roku?
Nigdy nie będzie taniej, niż wynosi obecna cena. W 2025 będzie drożej.
Last minute?
Nie. Nic tak nie wkurza, jak informacja, że szkolenie kupione z dużym wyprzedzeniem zostaje przecenione kilka dni przed końcem sprzedaży – to robienie w trąbę najwierniejszych klientów. Serio, nigdy nie będzie taniej.
Czy uczestnicy dostaną dostęp do materiałów, które pojawią się w przyszłości?
Tak, gratisowo. Jeśli szkolenie zostanie wzbogacone, rozszerzone albo wyprodukowane ponownie, wszyscy uczestnicy wcześniejszych edycji dostaną za darmo dostęp do nowych materiałów.
Przez jaki okres będę miał dostęp do nagrania?
Bezterminowo.
Kto dokładnie sprzedaje szkolenie?
FTL Software Tomasz Zieliński
Poleska 47/13
51-354 Wrocław
NIP 899-208-16-48
Skąd wiesz, czy ktoś cię nie oszuka i nie zaniży ceny?
Ludzie są uczciwi a materiał ze szkolenia pozwoli zaoszczędzić więcej, niż jeden dzień pracy. To dobra oferta.
Czy szkolenie może opłacić pracodawca z budżetu szkoleniowego?
Oczywiście. Rozumiem, że decyzja o finansowaniu może potrwać dłużej, niż 10 dni, poczekam na nią. Warunek – musisz skontaktować się e-mailem przed końcem sprzedaży, by zarezerwować sobie możliwość zakupu.
Co mogę pokazać pracodawcy oprócz strony WWW?
Tutaj znajdziesz opis szkolenia w formacie PDF z wszystkimi najważniejszymi informacjami, możesz wydrukować go albo wysłać przełożonemu mailem.
Czy mogę dostać fakturę pro-forma?
Tak, proszę o kontakt e-mailem.
Czy mogę kupić udział w szkoleniu dla kilku osób naraz?
Tak, proszę o kontakt e-mailem.
Czy można zapłacić kartą płatniczą?
Tak. Wybierz opcję płatności „Paypal lub karta płatnicza”, wówczas zobaczysz opcję płatności kartą bez logowania. Nie musisz mieć konta Paypal, aby zapłacić kartą płatniczą.
Czy można zapłacić w Euro?
Tylko, jeśli dysponujesz europejskim NIP-em. Takie faktury wystawiam ręcznie po uprzednim kontakcie e-mailem.
Kto prowadzi szkolenie?
Szkolenie przygotował i prowadzi Tomasz Zieliński, autor bloga Informatyk Zakładowy. Jest on zawodowym programistą od 2003 roku, był wykładowcą akademickim, bywa trenerem na szkoleniach IT i prelegentem na konferencjach.
Wielokrotnie realizował projekty związane z pobieraniem i automatycznym przetwarzaniem znaczących ilości danych. Z naprawdę dużymi zbiorami miał do czynienia podczas pracy dla Microsoftu nad wyszukiwarką internetową BING. Obecnie pracuje w firmie DeepL.
To jest archiwalna wersja strony informacyjnej szkolenia. Przejdź na stronę scrapowanie.pl
Kontakt
W razie jakichkolwiek pytań proszę o kontakt e-mailowy na adres tomek@informatykzakladowy.pl