
Kopciuszek nie podał Dobrej Wróżce specyfikacji karety, zaprzęgu, sukni ani pantofelków, wystarczyło Marzenie. Dobra Wróżka nie potrzebowała algorytmu opisującego kolejność transformacji flory i fauny w dwuślad z rzędem i fiakrem, miała Zaklęcie. Odległe echo takiego podejścia odnajdujemy w Regulaminie urzędowania sądów powszechnych, gdzie zamiast algorytmów działania SLPS mamy jedynie zarysy kształtu i okruchy specyfikacji. Niestety, życie to nie bajka, kobiety żyjące z uprawiania magii nie zniżają się do realizacji projektów IT – zamiast karety mamy więc furmankę z dyszlem z tyłu. Niby da się jechać, ale nie uciekniemy od pytania „gdzie był opis wymagań tego czegoś”.
Niniejszy artykuł inspirowany jest wieloletnim sporem sądowym Fundacji Moje Państwo o dostęp do kodu źródłowego i algorytmu działania Systemu Losowego Przydziału Spraw (o którym pisałem tutaj i tutaj). Zastanowimy się, czy rzeczywiście algorytm zawsze oderwany jest od kodu źródłowego oprogramowania, czy zawsze algorytm zostanie prawidłowo przełożony na kod, i wreszcie – w jaki sposób spełnić takie żądanie, gdy… spójna specyfikacja algorytmu nigdy nie powstała, zaś wyprodukowane oprogramowanie zawiera fundamentalne błędy. Mam nadzieję, że informacje zawarte w tekście przydadzą się prawnikom – wraz z cyfryzacją usług publicznych podobnych tematów będzie raczej przybywać niż ubywać.
Część pierwsza, w której mamy specyfikację i dowiadujemy się, czym algorytm różni się od kodu źródłowego a kod źródłowy od programu komputerowego
Czym jest algorytm? Słownik Języka Polskiego: „ściśle określony ciąg czynności, których wykonanie prowadzi do rozwiązania jakiegoś zadania”. Encyklopedia PWN: „przepis postępowania prowadzący do rozwiązania ustalonego problemu, określający ciąg czynności elementarnych, które należy w tym celu wykonać”. Wikipedia: „skończony ciąg jasno zdefiniowanych czynności koniecznych do wykonania pewnego rodzaju zadań, sposób postępowania prowadzący do rozwiązania problemu”.

Jak opisać algorytm?
Wiemy już, czym jest algorytm, przyjmijmy jednak, że nigdy żadnego nie widzieliśmy. Na warsztat weźmiemy jeden z bardzo prostych algorytmów sortowania. Opisuje on sposób postępowania ze zbiorem losowo ustawionych elementów, które możemy ze sobą porównywać według jakiegoś kryterium. Przykład: ustawione w rzędzie dzieci, które chcemy uszeregować rosnąco według wzrostu.
Wspomniane w definicji „czynności elementarne” to porównanie wzrostu dwójki dzieci oraz zamiana miejscami dwójki dzieci. Gdy przejdziemy przez wszystkie kroki algorytmu wykorzystującego te czynności, rezultatem będzie szereg dzieci, z których każde następne będzie wyższe od poprzedniego.
Nieważne, kto i w jaki sposób realizuje algorytm. Może to być nauczyciel, który szacuje wzrost dzieci i wydaje komendy zamiany miejsc. Może to być robot, który skanuje wzrost laserem i przesuwa platformy, na których stoją dzieci. W opisie algorytmu skupiamy się jedynie na sekwencji czynności.
Algorytm uszeregowania dzieci według wzrostu (nieefektywny, za to prosty): spójrz na pierwsze dziecko. Jeśli jest niższe od kolejnego – czyli pożądana kolejność jest spełniona – przenieś wzrok na kolejne dziecko i sprawdź, czy jest niższe od następującego po nim. Powtarzaj tę czynność. Za każdym razem, spoglądasz na dziecko wyższe od następnego, zamień rozpatrywaną parę dzieci miejscami i zacznij od początku. Gdy dotrzesz do ostatniego dziecka, wszystkie dzieci są uszeregowane według wzrostu.
Ten prosty algorytm opisaliśmy nie tak znowu prostymi słowami. Określenia „powtarzaj tę czynność” albo „rozpatrywana para” da się zinterpretować błędnie. Bez problemu moglibyśmy skomplikować lub udziwnić opis tak, aby stał się jeszcze mniej czytelny, trudniejsze jest przedstawienie go w sposób bardziej przejrzysty, bez kłopotliwych wieloznaczności.
Dygresja – istnieją szybsze algorytmy, w których średnia liczba dokonanych porównań i zamian będzie mniejsza. Ignorujemy je. Ważne, że nasz algorytm działa poprawnie, bo przy każdym nawrocie w zbiorze dzieci panuje coraz większy porządek a liczba nawrotów jest skończona. Ignorujemy też sytuację, gdy para dzieci jest tego samego wzrostu.
Inne sposoby zapisu algorytmu
Pamiętacie, że nasz algorytm mógłby posłużyć do zaprogramowania robota? Cóż, robot nie zrozumie języka polskiego, więc algorytm z poprzedniego rozdziału trzeba jakoś przekształcić. W pierwszym kroku niejednoznaczny opis zamienimy na schemat blokowy. Dzięki temu nie tylko eliminujemy kłopotliwe zaimki, ale łatwiej zorientujemy się, jaki krok ma miejsce w danym momencie i co może stać się za chwilę.
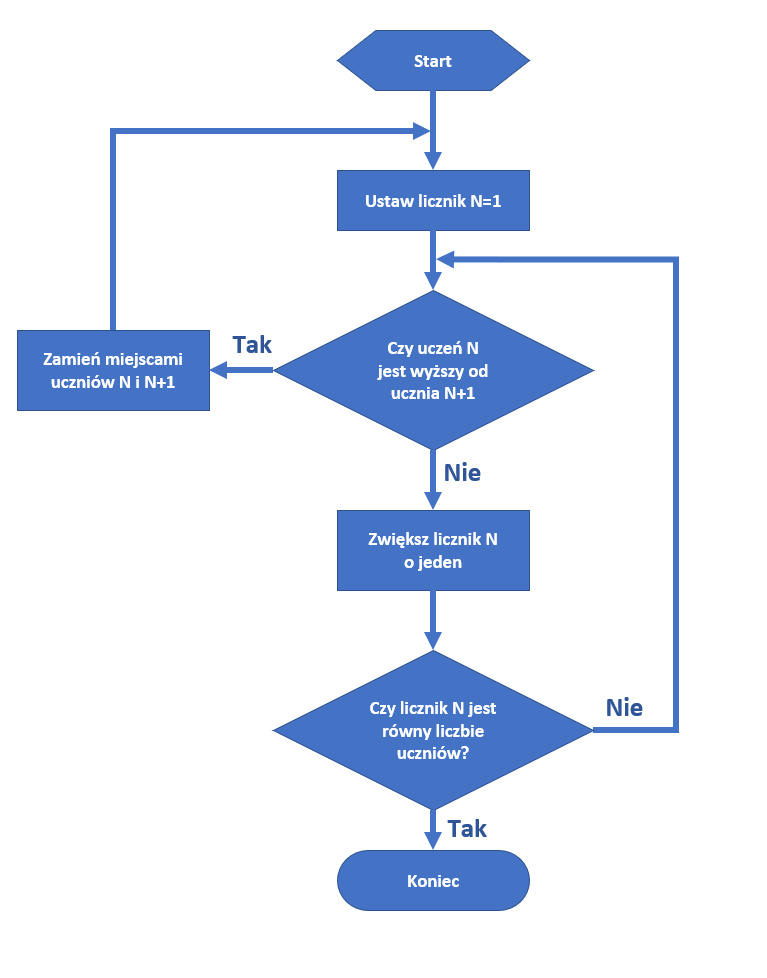
Dygresja numer 2: gdy patrzymy na schemat blokowy, łatwiej zauważyć potencjalne problemy – na przykład to, że powyższy algorytm nie radzi sobie prawidłowo z grupą dzieci złożoną z zera dzieci lub jednego dziecka. Program próbujący sprawdzić cechy nieistniejących elementów zbioru może się zawiesić lub – co gorsza – działać dalej w sposób zaburzony. My w niniejszym tekście podobne przypadki brzegowe ignorujemy, bo to nie one stanowią istotę problemu.
W oparciu o schemat blokowy możemy przygotować nieco bardziej uporządkowany opis algorytmu z ponumerowanymi komendami:
krok 0. START
krok 1. ustaw licznik N na 1
krok 2. jeśli uczeń N jest wyższy od ucznia N+1, to:
krok 2a. zamień tych uczniów miejscami
krok 2b. skocz do kroku 1
krok 3. (w przeciwnym razie) zwiększ N o 1
krok 4. jeśli N jest mniejsze od liczby uczniów, to:
krok 4a. skocz do kroku 2
krok 5. KONIEC
Czy to jeszcze opis algorytmu? Z całą pewnością, w dodatku łatwiejszy do interpretacji, niż skomplikowany opis słowny z poprzedniego rozdziału.
Czy to już program? Prawie! Jeśli skorzystamy z języka programowania Scratch (dzieci uczą się go w podstawówce), w ciągu kilku minut możemy przygotować program realizujący sortowanie tablicy liczb za pomocą naszego algorytmu.
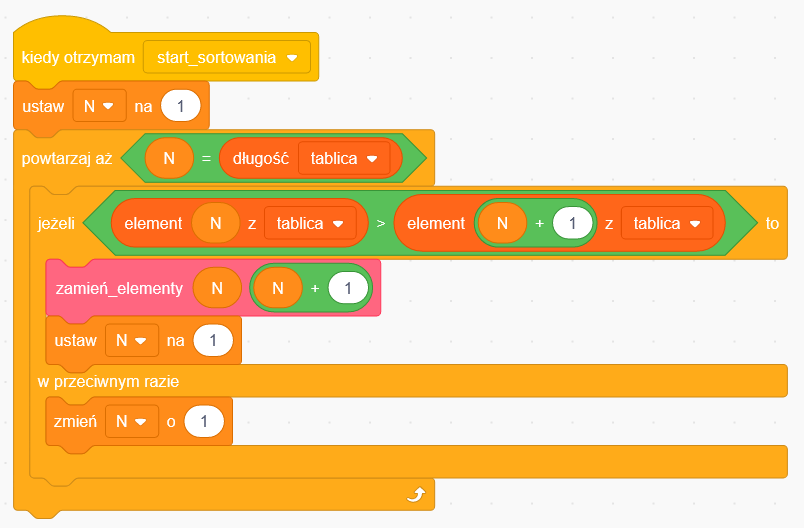
Tu na chwilę odejdziemy od głównego wątku by pokazać, że to naprawdę działający program. Aby ułatwić demonstrację, przygotujemy funkcję wypełniającą tablicę losowymi wartościami.
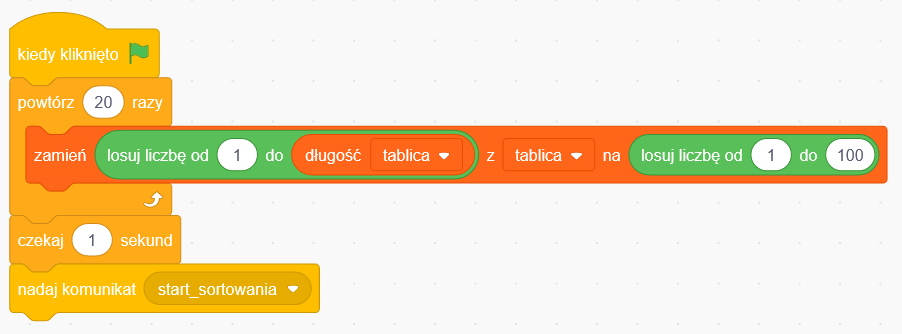
W głównym bloku korzystamy z funkcji zamiany miejscami elementów tablicy, została ona dla czytelności wydzielona do osobnego bloku o nazwie „zamień_elementy”. Program możesz zobaczyć w działaniu tutaj. Kliknięcie zielonej flagi wypełnia tablicę losowymi wartościami, potem następuje sekundowa pauza, następnie tablica zostaje posortowana przez fragment programu realizujący nasz algorytm. Spoiler alert: działa za każdym razem.
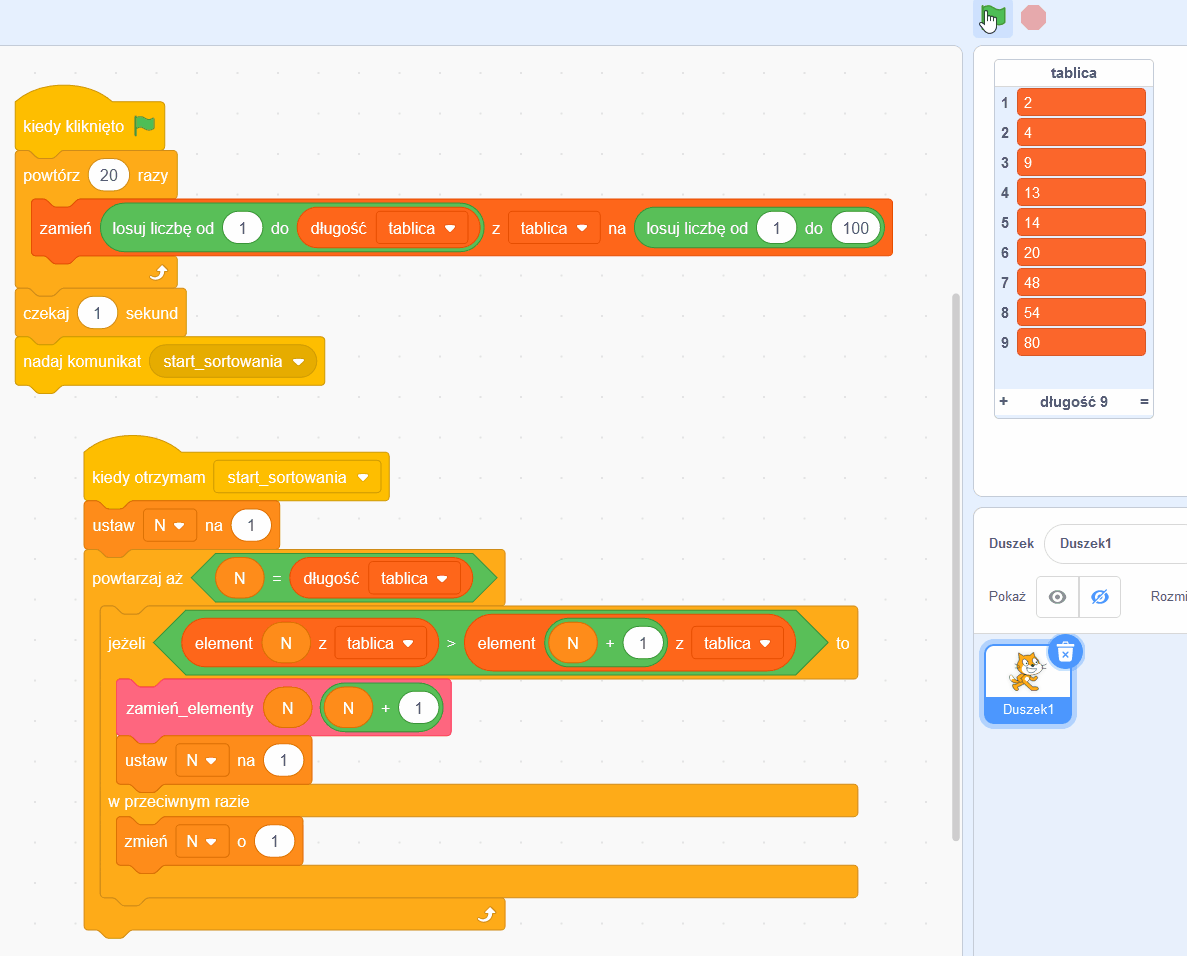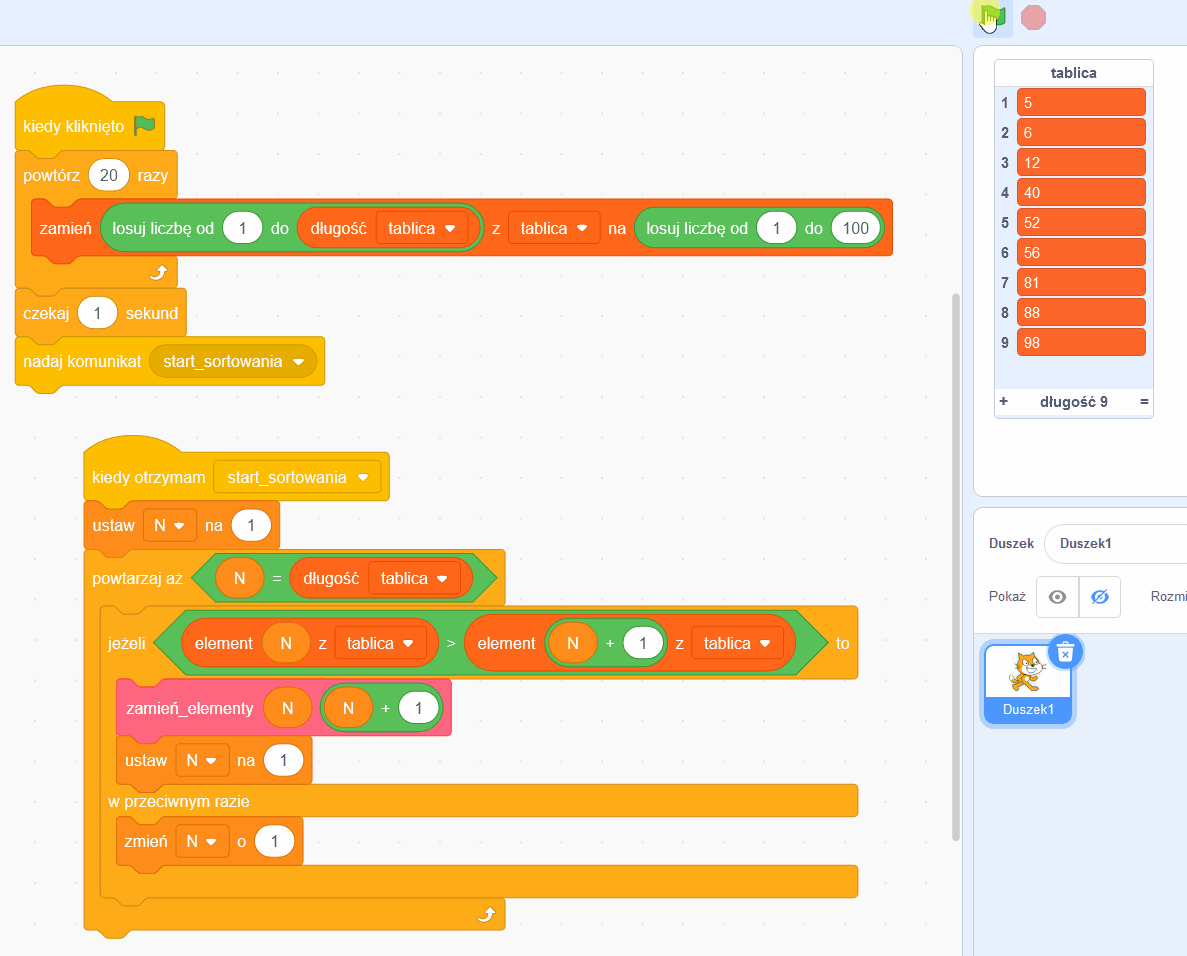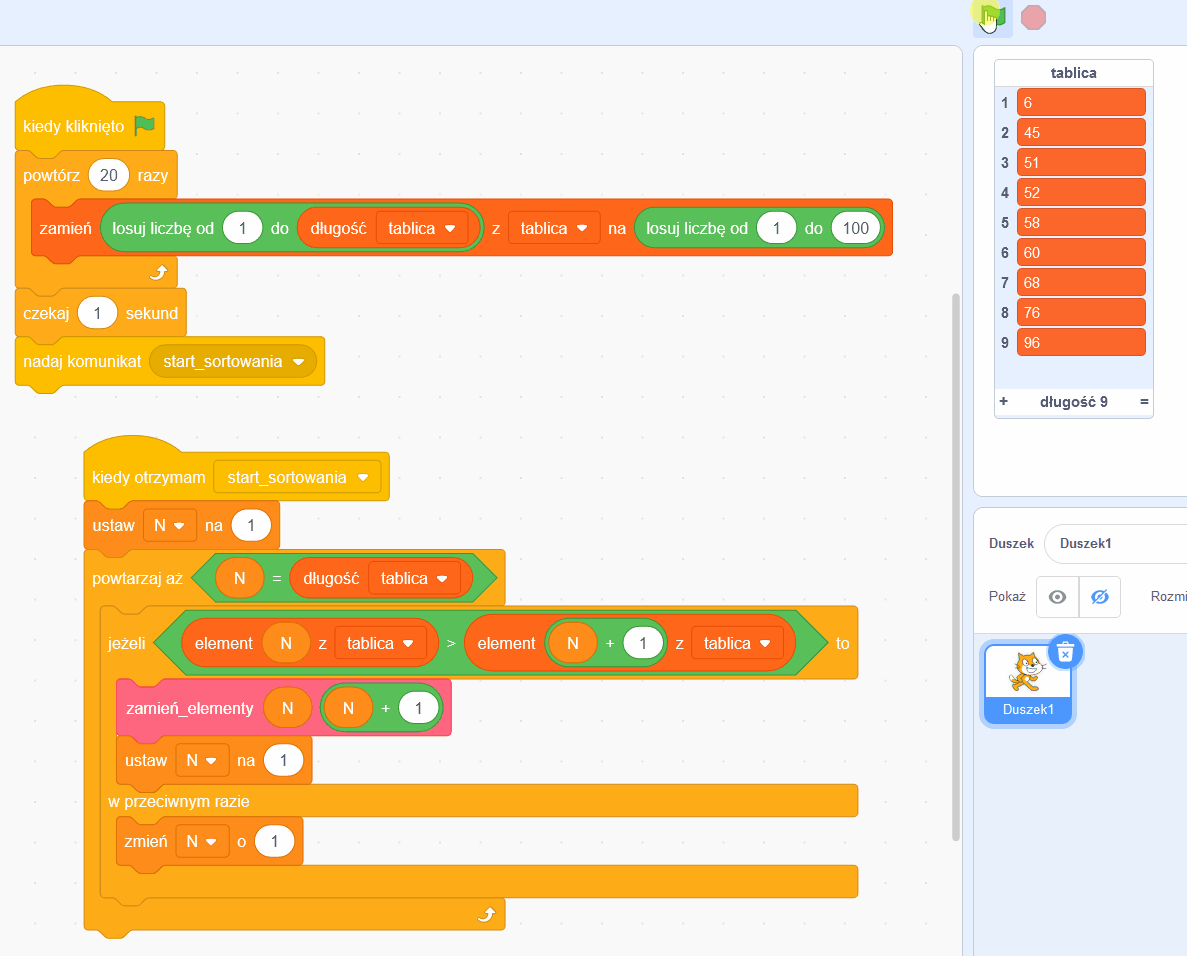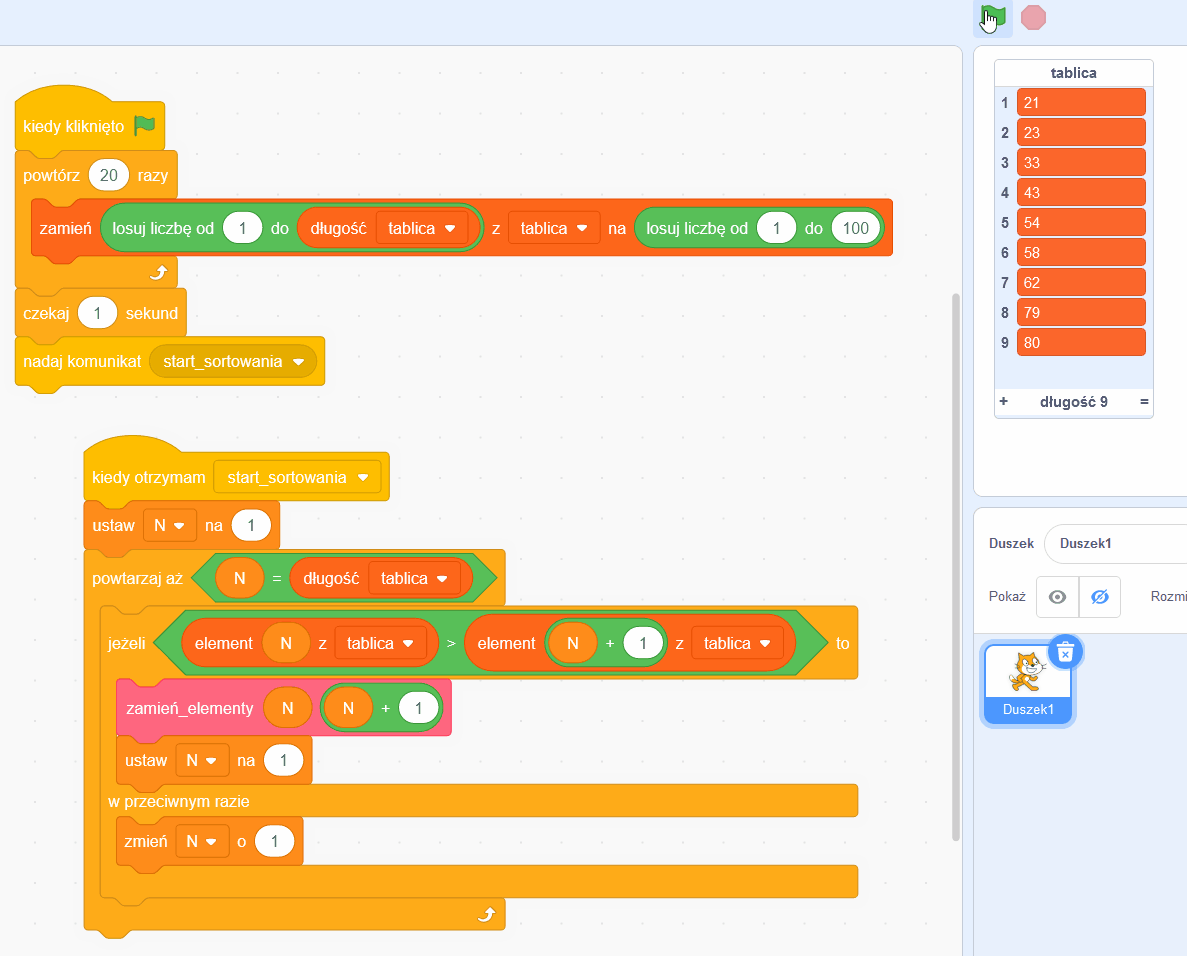
Co właśnie zobaczyliśmy?
Na początku artykułu mieliśmy do czynienia z następującym tekstowym opisem algorytmu: Spójrz na pierwsze dziecko. Jeśli jest niższe od kolejnego – czyli pożądana kolejność jest spełniona – przenieś wzrok na kolejne dziecko i sprawdź, czy jest niższe od następującego po nim. Powtarzaj tę czynność. Za każdym razem, spoglądasz na dziecko wyższe od następnego, zamień rozpatrywaną parę dzieci miejscami i zacznij od początku. Gdy dotrzesz do ostatniego dziecka, wszystkie dzieci są uszeregowane według wzrostu.
Potem opracowaliśmy schemat blokowy:
Tekst ani schemat nie były jeszcze programami. Potem przygotowaliśmy zwięzły opis w punktach i tu było już naprawdę blisko:
krok 1. ustaw licznik N na 1
krok 2. jeśli uczeń N jest wyższy od ucznia N+1, to:
krok 2a. zamień tych uczniów miejscami
krok 2b. skocz do kroku 1
krok 3. w przeciwnym razie: zwiększ N o 1
krok 4. jeśli N jest mniejsze od liczby uczniów, to:
krok 4a. skocz do kroku 2
Stąd już tylko krok do „ubrania” tych punktów w prawdziwy, działający program w Scratchu, który operując na elementach tablicy przeprowadza operację sortowania (poniżej demo z samym rezultatem pracy algorytmu, klikaj w małą zieloną flagę, pełny program tutaj).
Poniżej mamy działającą implementację tego algorytmu w języku BASIC na niemal czterdziestoletni komputer Commodore 64.

We współczesnym języku programowania C# przykładowa implementacja może wyglądać tak (w zależności od języka, numeracja elementów tablicy zaczyna się od zera lub jedynki):
W tym miejscu możemy mieć kilka spostrzeżeń.
Spostrzeżenie pierwsze:
Słowny opis algorytmu bywa nieprecyzyjny i trudny do zrozumienia. Im dokładniejszą i bardziej sformalizowaną specyfikację przygotujemy, tym bardziej zbliża się ona do postaci mającej bezpośrednie przełożenie na kod źródłowy.
Spostrzeżenie drugie:
Przy dużej złożoności systemów już samo tylko zweryfikowanie spójności i kompletności specyfikacji jest trudne. Bez przeglądu kodu źródłowego i drobiazgowych testów nie sposób upewnić się, że algorytm opisany w specyfikacji jest realizowany przez dany program komputerowy
Tu ogarnia nas niepokój. Chcemy poznać algorytm SLPS, ale właśnie zorientowaliśmy się, że nie powie nam on, jak rzeczywiście działa program mający realizować ten algorytm. Powrócimy do tego tematu, na razie zajmijmy się jeszcze kwestią poboczną:
Czym kod źródłowy różni się od programu komputerowego
Powyższe pytanie to pułapka. Teoretycznie nie powinniśmy mieć problemu z oddzieleniem kodu źródłowego od programu gotowego do wykonania. Na poniższych obrazkach mamy podgląd plików z kodem źródłowym w języku C oraz binarnym kodem wykonywalnym dla Windows (Portable Executable), proces zamiany jednego w drugie nazywamy kompilacją.
W praktyce – czyha na nas mnóstwo pokus, by stracić z oczu główny wątek i zagłębić się w dygresjach.
Po pierwsze – moglibyśmy pochylić się nad prehistorią informatyki próbować zidentyfikować chwilę, gdy ów problem zaistniał. W pradziejach informatyki nie było języków programowania zaś na teksturowych kartach pracowicie wycinano kombinacje dziurek przekładane wprost na kolejne instrukcje procesora. Napisano o tym setki książek.

źródło: @NanoRaptor
Po drugie – moglibyśmy zanurkować w ostatnie dwudziestolecie technik cyfrowych i próbować objaśniać pojęcia bajtkodu, translacji, parsowania, tokenizacji, kompilacji, linkowania… Wszystko po to, by na końcu otrzymać śmiertelny cios w plecy – to mikrokod procesora określi kolejność wykonania instrukcji które mu przekażemy, więc de facto nigdy nie mamy do czynienia z „finalną” wersją programu wykonywaną przez komputer. Napisano o tym tysiące książek.
Po trzecie – wraz ze wzrostem wydajności komputerów popularność zyskały interpretowane języki programowania, jak Python czy PHP. W ich przypadku wykonanie programu rozpoczyna się od wczytania plików z kodem źródłowym i przełożenia ich „na żywo” do postaci kodu maszynowego, wykonywanego przez procesor. W praktyce więc kod źródłowy staje się równoważny programowi wykonywalnemu. Nawet nie próbujmy szacować ogromu literatury obejmującej te zagadnienia.
Dzielnie powstrzymujemy szarpiącą się dygresję i wracamy do głównego wątku – w kontekście dostępu do kodu źródłowego i algorytmu działania SLPS różnica między kodem źródłowym a programem wykonywalnym jest nieistotna. Oczywiście – źródła są łatwiejsze w analizie, jednak techniki inżynierii odwrotnej (reverse engineering) pozwalają badać zachowanie również gotowego do odpalenia kodu binarnego. Wymaga to większych umiejętności i trwa dłużej, ale jest możliwe.
Co jest trudniejsze – ułożenie algorytmu czy napisanie programu realizującego ów algorytm?
Odpowiedź mało odkrywcza – to zależy. W olimpiadach programistycznych oba aspekty bywają jednakowo wyżyłowane. Przykładowe zadanie [PDF] z przedostatniej edycji zawodów Wielka Przesmycka wygląda jak poniżej (ono akurat nie jest szczególnie trudne, jest za to krótkie, więc wygodne do zacytowania):
Jak wszyscy dobrze wiemy, Ziemia jest nieskończoną płaszczyzną w trójwymiarowej przestrzeni, a Słońce — małą kulką świecącą równomiernie we wszystkich kierunkach, dla uproszczenia reprezentowaną przez punkt. Pewnego dnia w okolicy pojawiła się Gwiazda Śmierci w kształcie kuli o promieniu R, wskutek czego w niektórych miejscach na Ziemi można było zaobserwować zaćmienie. Dla danego położenia Ziemi, Słońca i Gwiazdy Śmierci oblicz pole powierzchni cienia rzucanego przez Gwiazdę na Ziemię.

Zadania konkursowe wymagają talentu, by wymyślić algorytm rozwiązujący problem i mieszczący się w limitach czasu wykonania i zużycia pamięci, oraz biegłości w rzemiośle, by przełożyć pomysł na kod programu. Co istotne jednak, zawierają pełne informacje o formacie danych wraz z przykładami.
Takiego komfortu nie doświadczyli twórcy SLPS, którego opis zawarty we wspomnianym Regulaminie sądów nie ma zgoła nic wspólnego ze specyfikacją algorytmu. W ten sposób przechodzimy płynnie do części drugiej…
Część druga, w której funkcjonowanie sądów reguluje program działający według nieujawnionego algorytmu
Spójrzmy na historię postępowania, w którym orzeczenie Naczelnego Sądu Administracyjnego z 19 kwietnia 2021 zawiera następujące ustępy:
- „należy przyjąć, że algorytm Systemu Losowego Przydziału Spraw spełnia kryteria informacji publicznej”
- „w tworzeniu programu komputerowego zaprojektowanie algorytmu jest pierwszym etapem prac określającym kolejne czynności jakie powinien on wykonywać”
- „Opracowanie algorytmu można porównać do opisu (słownego, bądź graficznego) sposobu działania, sekwencji, czy też zestawu ściśle określonych czynności (komend, rozkazów, poleceń) prowadzących do określonego rezultatu (w tym przypadku wylosowania składu dla konkretnej sprawy wprowadzonej do SLPS). Ciąg tych czynności to właśnie algorytm przy czym może on mieć różny stopień szczegółowości począwszy od ogólnych założeń zawartych w przepisach na szczegółowych technicznych rozwiązaniach kończąc.”
Kluczowy cytat:
Algorytm przedstawiający sposób działania aplikacji sieciowej SLPS za pomocą której wyznaczany jest skład rozpoznający sprawę sądową mieści się w pojęciu informacji publicznej z tego względu, że informuje o sposobie funkcjonowania sądów, o sposobie przyjmowania i załatwiania spraw (art. 6 ust. 1 pkt 3 lit. d ustawy o dostępie do informacji publicznej). Należy podkreślić, że co do zasady wszystko, co wiąże się bezpośrednio z funkcjonowaniem i trybem działania podmiotów, o których mowa w art. 4 ust. 1 ustawy stanowi informację publiczną. Sposób działania SLPS przewidziany w jego algorytmie (zestawie poszczególnych poleceń jakie ten System realizuje) jest informacją o ciągu czynności prowadzących do wyznaczenia konkretnego sędziego do załatwienia sprawy.
To, że ten ciąg czynności realizuje program komputerowy i z tego względu ma on charakter techniczny nie może pozbawiać tej informacji (o sposobie wyznaczenia sędziego) charakteru informacji publicznej. Rację ma skarżąca organizacja, że algorytm SLPS w okolicznościach niniejszej sprawy nie stanowi jedynie informacji technicznej, ale jest wyrazem procedury ściśle związanej z bezpośrednią sytuacją obywateli, których sprawy są rozpoznawane. Techniczny charakter tej informacji wynika wyłącznie z postępu technologicznego.
Dodajmy, że wraz z postępującą cyfryzacją administracji przybywać będzie dziedzin życia, w których rozstrzygnięcia i czynności wpływające na życie obywateli będą całkowicie zautomatyzowane. Nie możemy godzić się na to, aby systemy realizujące te zadania miały formę „czarnej skrzynki”, której reguły działania pozostają tajemnicą.
Argumentacja, jakoby kod źródłowy był jedynie „technicznym elementem przetwarzania danych” (cytat z pisma Ministerstwa), może ewentualnie dotyczyć tych modułów oprogramowania, które odtwarzają „analogową” pracę urzędów. Przykład takiego elementu technicznego: panel zarządzania uprawnieniami użytkowników, gdzie konfiguracja odzwierciedla strukturę organizacyjną (definiowaną poza systemem komputerowym i istniejącą niezależnie od niego).
Nie sposób jednak zgodzić się, że „samodzielnie algorytm [SLPS] nie zawiera jakiegokolwiek komunikatu o sprawach publicznych” (cyt. tamże), skoro ów algorytm nie jest nigdzie wyspecyfikowany, istnieje tylko jedna implementacja zaś rezultaty działania wpływają na życie publiczne i prawa obywateli. W takich sytuacjach jawność kodu źródłowego powinna być automatyczna i obowiązkowa.
Wyniki kontroli NIK
Spójrzmy teraz na raport Najwyższej Izby Kontroli opisujący m.in. problemy z realizacją i wdrożeniem SLPS (cytowałem go obszernie w tym tekście):
Jak wskazał Dyrektor DKO, analitycy DIRS nie znali zasad funkcjonowania sądów i nie potrafili przedstawiać pytań w tym zakresie w sposób zrozumiały dla sędziów. Z kolei sędziowie nie potrafili pytać analityków DIRS o projektowane zasady funkcjonowania systemu w sposób zrozumiały dla analityków. W związku z powyższym występowały zaburzenia w komunikacji między pionem merytorycznym (użytkownikami), a wytwórcami oprogramowania
w przypadku SLPS, przez okres dwóch lat od rozpoczęcia realizacji projektu nie określono jego szczegółowych założeń, ani wymagań merytorycznych tworzonej aplikacji. Stosowna dokumentacja, a także struktury organizacyjne odpowiadające za jej wdrażanie zostały przygotowane dopiero pod koniec realizacji projektu, w związku z czym, w dniu uruchomienia systemu (1 stycznia 2018 r.) użytkownicy otrzymali wadliwie działające oraz pozbawione kluczowych funkcjonalności narzędzie informatyczne. Wpłynęło to negatywnie na równomierność przydziału spraw referentom oraz spowodowało wyłączenie mechanizmów zabezpieczających przed ewentualnymi, intencjonalnymi działaniami ograniczającymi losowość przydziału
Kontrolerzy NIK stwierdzają wprost, że oprogramowanie powstawało bez wymagań ani szczegółowych założeń a dokumentację przygotowano z dużym opóźnieniem. Można zaryzykować stwierdzenie, że przy takich brakach programiści tworzyli wiele funkcji „na czuja”, uzupełniając luki założeniami tworzonymi ad hoc w trakcie programowania.

źródło: @monkeyUser
Brak dotrzymania dobrych praktyk projektowych staje się oczywisty przy lekturze tych fragmentów:
w okresie 1 października 2018 r. – 20 listopada 2018 r. przydzielenie sprawy sędziemu zastępcy (poprzez opcję „osoba zastępująca”) skutkowało błędnym zaliczaniem takiej sprawy za kilkadziesiąt lub nawet ponad sto spraw. W konsekwencji taki sędzia był pomijany w losowaniach, aż inni sędziowie wylosowali równie dużą liczbę spraw
stosowana do listopada 2018 r. procedura testowa nie spełniała powszechnie przyjętych standardów w zakresie realizowania projektów IT. W szczególności brak było standaryzowanych scenariuszy testowych, przypadków testowych oraz raportów z testów poprzedzających produkcyjne wdrożenie kolejnej wersji systemu
Co było rezultatem sytuacji, w której brakowało wymagań, stworzone oprogramowanie jest pełne błędów zaś osoby wdrażające i korzystające z systemu nie dysponują dokumentacją?

W grudniu 2018 r. Dyrektor DKO opracował koncepcję naprawy danych w bazie SLPS. Generalne przeliczenie wartości zgodne z tą koncepcją odbyło się 15 lutego 2019 r. Operacja ta okazała się skuteczna tylko częściowo i jednocześnie sama była przyczyną kolejnych nieprawidłowości w bazie danych. Dlatego w marcu 2019 r. wprowadzono do SLPS możliwość zerowania obciążeń, a w lipcu udostępniono użytkownikom arkusz Excel służący do ręcznego przeliczenia danych i rozpoczęcia przydziału od nowa. Pomimo wprowadzenia ww. rozwiązania, do końca kontroli w niektórych wydziałach utrzymywały się skutki wcześniejszego, nieprawidłowego funkcjonowania SLPS. Skala nieprawidłowych obciążeń nie została rozpoznana do czasu zakończenia kontroli.
Wiele spostrzeżeń dotyczących realnych błędów SLPS można znaleźć także w sprawozdaniu z lustracji II Wydziału Karnego Sądu Okręgowego w Toruniu. Opisano tam m.in. skalę nierówności w obciążeniu sędziów w losowaniach w pierwszym kwartale 2018, błędy w kalkulacjach funkcji kosztu, niedostosowanie systemu do specyfiki wydziału karnego i tak dalej.
Faktyczny algorytm przydziału spraw w systemie SLPS
Jeśli weźmiemy pod uwagę wszystko powyższe, algorytm przydziału nowej sprawy w systemie SLPS wyglądał jakoś tak:
- Nowa sprawa wpływa do sekretariatu
- Pracownik sekretariatu korzystający z nieaktualnej i niekompletnej instrukcji rejestruje nową sprawę w systemie
- Jeśli w danym wydziale w danym dniu pracownik czuje, że generowane obciążenia sprawami są zaburzone na czyjąś niekorzyść, korzysta z awaryjnej funkcji „jednorazowe obciążenie/odciążenie” sędziego/składu
- Jeśli w danym wydziale w danym dniu pracownik czuje, że generowane obciążenia sprawami są zaburzone na czyjąś korzyść, korzysta z funkcji zerowania obciążeń sędziego/składu
- […]
Dostrzegacie problem? Już w trzecim kroku nie jest to „skończony ciąg jasno zdefiniowanych czynności”, lecz walka rozumu i godności człowieka z systemem informatycznym obarczonym wielowarstwowymi błędami.
Jak udostępnić informację o algorytmie działania SLPS?
Zastanówmy się, w jaki sposób Ministerstwo Sprawiedliwości może udostępnić informację publiczną na którą składa się algorytm działania SLPS, czyli – zacytujmy Sąd Najwyższy – „opis (słowny, bądź graficzny) sposobu działania, sekwencji, czy też zestawu ściśle określonych czynności (komend, rozkazów, poleceń) prowadzących do określonego rezultatu (w tym przypadku wylosowania składu dla konkretnej sprawy wprowadzonej do SLPS)”
Opis algorytmu powinien być wystarczająco dokładny, aby – mając wiedzę o bieżących obciążeniach i wygenerowanej wartości losowej – możliwe było samodzielne przeprowadzenie obliczeń i odtworzenie identycznego wyniku. Cóż więc może lub powinno wejść w skład odpowiedzi na wniosek o udostępnienie rzeczonej informacji?
Pierwsza możliwość – zestaw wymagań lub dokumentacja architektoniczna SLPS, jeśli w ich skład wchodzi opis sposobu sortowania sędziów w oparciu o bieżące obciążenie, przekładania wartości losowej na wybór składu z puli itp. Tylko czy dokumentacja SLPS o dostatecznej szczegółowości kiedykolwiek powstała? A jeśli powstała, to czy dbano o jej aktualność? To problem wielu długoterminowych projektów – w miarę upływu czasu rozjazd między dokumentacją a rzeczywistością jest coraz większy, stosunkowo szybko dokumentacja taka staje się nieprzydatna a kilka lat później wręcz szkodliwa.
Druga możliwość – dokumentacja wykonawcza SLPS – w przypadku, gdyby projekt architektoniczny operował na wyższym poziomie abstrakcji. Wątpliwość taka sama: czy taki dokument istnieje?
Trzecia możliwość – instrukcja użytkownika końcowego. Jeśli jest wystarczająco dokładna i oprócz opisu okienek zawiera opis działania systemu, mogłoby to zadziałać. Przez długi czas problemem SLPS był jednak całkowity brak dokumentacji a nie jej niedostateczna szczegółowość, więc i ta ścieżka nie jest zbyt obiecująca.
Czwarta możliwość – specyfikacja API i zestaw testów jednostkowych. Hahahaha, pisząc te słowa nie mogłem przestać się śmiać.
Jest jeszcze oczywiście możliwość piąta – w której Ministerstwo przekaże opis algorytmu wydzielony z dokumentów projektowych. Czy rzeczywiście bylibyśmy usatysfakcjonowani?
Jedyną reprezentacją rzeczywiście wdrożonego algorytmu jest kod źródłowy
Wiemy, że SLPS miał błędy, np. wspomniane w raporcie NIK zaliczanie jednokrotnego zastępstwa jako setki „własnych” spraw danego sędziego. Usterka taka w oczywisty sposób odbiega od zamierzonego sposobu działania SLPS, co odróżnia zamierzenia twórców systemu od zrealizowanego produktu.
Rodzi się więc pytanie – czy wnioskując o informację publiczną dotyczącą „zestawu ściśle określonych czynności prowadzących do wylosowania składu dla konkretnej sprawy” chcemy dowiedzieć się, jak SLPS miał działać planowo, czy też jak działa wdrożone w rzeczywistości oprogramowanie?
Moim zdaniem jedynie druga opcja ma sens. Gdy pytamy jednostkę budżetową o zeszłoroczne wydatki, to chcemy dostać rzeczywiste faktury lub wyciągi bankowe a nie ułożony rok wcześniej budżet czy plan wydatków. Mówiąc ogólniej – informacja publiczna dotycząca zasad funkcjonowania organów władzy publicznej ma przedstawiać rzeczywisty sposób załatwiania spraw, a nie procedury które w praktyce uległy zmianom.
W takiej sytuacji jedyną metodą udostępnienia algorytmu SLPS jest udostępnienie odpowiedniego fragmentu kodu źródłowego. Kilka spostrzeżeń:
- nie oznacza to konieczności udostępniania kompletu źródeł, bo tylko jego część realizuje zadania związane ze sposobem wyznaczenia sędziego; nie potrzebujemy np. modułu zarządzania użytkownikami albo modułu integracji SLPS z usługami katalogowymi
- nie oznacza to automatycznie konieczności udostępniania kodu źródłowego na otwartej licencji, jeśli natomiast umowa z wykonawcami oprogramowania zamawianego przez instytucje państwowe nie przenosi praw majątkowych do źródeł na zamawiającego, to powinna co najmniej zezwalać na dysponowanie kodem źródłowym zgodnie z przepisami o dostępie do informacji publicznej
- nie oznacza to konieczności udostępnienia jakichkolwiek sekretów, haseł, kluczy API – to zawsze powinny być składniki parametryzacji, oddzielone od kodu źródłowego wdrażanego oprogramowania
- nie oznacza to wglądu w dane przetwarzanie przez SLPS (o tym za chwilę)
- nie oznacza to obniżenia bezpieczeństwa danych ani infrastruktury.
Skąd wiemy, że pozyskany algorytm działania SLPS rzeczywiście odpowiada systemowi uruchomionemu na serwerach Ministerstwa?
Wybiegnijmy myślą w taki wariant przyszłości, gdzie w ramach udostępnienia informacji publicznej wnioskującym przekazano odpowiednie fragmenty kodu źródłowego SLPS. Jak możemy przekonać się, że ów kod faktycznie działa na serwerach ministerstwa i dokonuje uczciwych losowań? Jak zapewnić transparentność i rozliczalność procesu oraz niepodważalną randomizację przydziału? Rozłóżmy ten problem na dwie części.
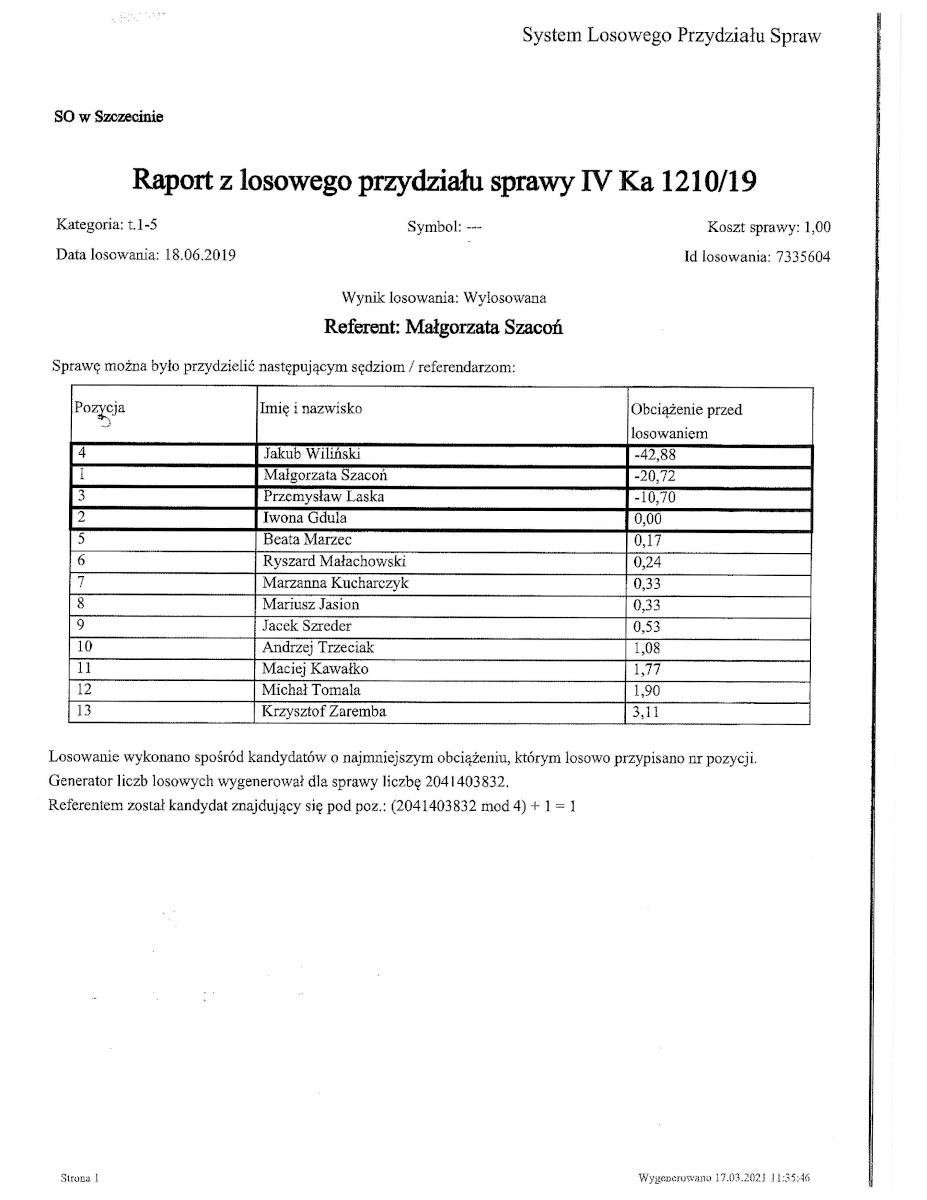
Krok 1 – repozytorium losowań
Pierwszym krokiem powinno być utworzenie repozytorium losowań czyli publicznej bazy danych z następującymi informacjami o wyniku losowania składu sędziowskiego każdej sprawy:
- data i godzina losowania
- identyfikator losowania
- koszt sprawy (uproszczona miara nakładu pracy / złożoności sprawy)
- bieżące obciążenie wszystkich sędziów danego wydziału
- sędziowie brani pod uwagę w bieżącym losowaniu
- wartość losowa oraz wyznaczony przy jej pomocy sędzia
- oraz: lista sędziów wyłączonych z losowania (w dokumencie powyżej brak tej informacji)
Gdy wszystkie raporty z losowań będą publiczne, każdy zainteresowany będzie mógł samodzielnie zweryfikować:
- czy liczby losowe faktycznie są losowe (tutaj znajdziesz więcej informacji na temat metod sprawdzania losowości ciągu liczb)
- czy zmiana obciążenia sędziów między kolejnymi losowaniami nie wykazuje anomalii
- czy sprawy o większym koszcie nie trafiają do zamkniętej grupy sędziów
- wreszcie: czy każdy raport z losowania przedstawia stan i rezultat zgodny z ujawnionym algorytmem działania SLPS
Publiczne repozytorium losowań SLPS pozwoliłoby po pierwsze upewnić się, że nie mają miejsca niektóre systematyczne nadużycia, po drugie zaś szybko wykryć błędne działanie systemu wynikające z usterek, błędnej parametryzacji lub nieprawidłowego użycia funkcji nadzorczych (w ich przypadku przydałby się skądinąd osobny log z uwierzytelnionym audytem). Przykład? Usterkę przy liczeniu wagi zastępstw trudno zauważyć w pojedynczym wydziale niewielkiego sądu, ale przy analizie danych z całego kraju powiązanie zastępstw z zaburzeniami obciążeń byłoby trywialne.
Jakie jest bieżące podejście Ministerstwa Sprawiedliwości do ujawniania wyników losowań? Również ten wątek podjęła Fundacja Moje Państwo zwracając się o tę informację publiczną, Ministerstwo uznało, że to nie jest informacja publiczna, Sąd Administracyjny orzekł, że jednak jest a wniosek ma zostać rozpatrzony. Niespieszny spór trwa już prawie dwa lata, końca nie widać.
Krok 2 – zewnętrzne, weryfikowalne źródło losowości
Repozytorium losowań nie uchroni nas jednak przed fałszerstwami losowań opisanymi w tym artykule. Opisałem tam nie tylko mechanizm ustawiania wyników, ale także scenariusz wiarygodnego wytłumaczenia się z obecności tego mechanizmu w kodzie SLPS. Oto więc druga część warunku koniecznego, by losowanie sędziów cechowało się niepowtarzalną losowością.
Lista losowań do przeprowadzenia musi powstawać przed wygenerowaniem wartości losowej i być wystawiona do publicznej wiadomości. Następnie należy sporządzić wartość losową w oparciu o informacje, które nie były znane podczas tworzenia listy losowań. Przykłady: seria nadzorowanych komisyjnie rzutów kostką na tle telewizora z kilkunastoma stacjami TV. Albo – wartości RGB dominujące w sekundzie losowania na ekranach tych stacji. Albo – obroty i kursy wybranych walorów po zamknięciu notowań giełdowych. Albo – liczba partii rozegranych danego dnia na wybranej platformie szachowej i procentowy stosunek zwycięstw do remisów.
Ważne, by każdy zainteresowany mógł przekonać się, że wartość została wygenerowana w sposób uniemożliwiający jej wcześniejsze odgadnięcie lub spreparowanie. Tak wyznaczona wartość losowa może zainicjować generator liczb pseudolosowych, których użyjemy do rozstrzygnięcia wszystkich przygotowanych uprzednio losowań.
Podsumowanie
W niniejszym artykule starałem się wskazać i zilustrować dwie tezy:
- granica między algorytmem a kodem źródłowym programu realizującego ów algorytm jest niezbyt wyraźna; im opis algorytmu jaśniejszy i bardziej jednoznaczny, tym bardziej przypomina formą kod źródłowy
- jedynie utrwalony program komputerowy wyraża rzeczywiście zrealizowaną ideę; nie sposób stwierdzić, że program realizuje jakiś algorytm, gdy z powodu błędów programisty efekt działania programu odbiega od prawidłowego wyniku
Podsumowując: jedynie po zapoznaniu z odpowiednimi fragmentami kodu źródłowego SLPS poznamy rzeczywisty „sposób działania SLPS przewidziany w jego algorytmie”. Gdy fragmenty te zostaną uznane za informację publiczną i ujawnione, ustawię się pierwszy w kolejce do ich recenzji.
Za komentarz do tekstu oraz pomocne uwagi dziękuję Tomaszowi Zalewskiemu oraz Krzysztofowi Izdebskiemu.
ad *) żarcik, taka dyskietka nigdy nie powstała
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

18 odpowiedzi na “O algorytmach dla prawników”
Nabrałeś mnie z tą dyskietką. Zdążyłem się podzielić tą informacją z kolegami z pracy 🙂
Wiadomo kto wdrażał ten system? Sygnity lub Comarch xD ? Wiadomo czemu zajęło to dwa lata, dlaczego tworzyli tak długo bez dokumentacji i kto w ogóle dopuścił na produkcję kod bez testów? Przecież to poziom niżej niż junior w korpo typu N****.
Nie cały tekst jest dla prawników 😉 niemniej dzięki! 🙂
Z tą dyskietką to pojechałeś. Założę się, że za jakiś czas będzie krążyć w internetach, jako prawdziwa historia. 😉
System jest autorskim dziełem Departamentu Informatyzacji i Rejestrów Sądowych resortu sprawiedliwości. Z — cały czas szczątkowych — informacji można wnioskować, że oni sami nie do końca wiedzą co tam zrobili.
Czesc, przeczytalem, i jak zwykle mam mieszane uczucia. Z punktu widzenia pragmatyka nasuwaja mi sie nastepujace pytania:
– czy w zamowieniu / specyfikacji podany byl rzeczywiscie jakis konkretny algorytm, czy tez bylo to raczej na zasadzie „zrobcie tak, zeby bylo dobrze” ewentualnie „komputer bedzie wiedzial”? Bo od tego nalezy zaczac.
– to, jak poszlo wdrozenie (i implementacja) to troche tak, jak z powiedzeniem „polski lotnik poleci nawet na drzwiach od stodoly”. No i polecieli.
– nie bardzo rozumiem, dlaczego twierdzisz, ze granica pomiedzy algorytmem a implementacja jest niezbyt wyrazna? Niezbyt wyrazna jest w tym konkretnym przypadku, bo mamy do czynienia z przypadkiem, gdzie wdrozono cos, co – jak rozumiem – nie zostalo wyspecyfikowane?
– samo dostarczenie oprogramowania – jak wszyscy wiemy – to wlasciwie nic nie znaczy; powinny byc jakies protokoly akceptacyjne itp – i tego bym szukal (aczkolwiek, biorac pod uwage sprawozdanie NIK, to cudu nie bylo).
– kto wlasciwie opracowywal wytyczne do systemu? Tam lezy przyczyna wszystkich nieszczesc.
– czy tego typu projekty poddawane sa jakims konsultacjom? Miedzyresortowym? Spolecznym (hehe)? Byly jakies? Jak juz nic nie zostalo, to zawsze mozna zrobic 'learning from disaster’, aczkolwiek nie mam zludzen, ze ktos tak do tego podejdzie…
– to nie jest tak, ze bez specyfikacji nie mozna zrobic dobrego wdrozenia. Mozna, ale jest to bardziej skomplikowane i wymaga duzo wysilku od wszystkich zaangazowanych stron. Pozostaje tez kwestia weryfikacji tak powstalego tworu – bo nie ma tutaj punktu wyjscia, z ktorym mozna pozniej zderzyc produkt finalny.
– czy gdziekolwiek w wymaganiach byly podane jakiekolwiek kwestie dotyczace transparentnosci czegokolwiek? Bo jesli nie, to trudno oczekiwac, zeby je zaimplementowano.
To tak na szybko.
Pozdrawiam
Maciej
Autorze, zadziwiasz mnie. Bardzo dobrze przedstawiasz te zawikłane kwestie techniczne i szacunek się należy, że Ci się chce brnąć 🙂 Pozdrawiam!
Moim zdaniem jest to b.dobry materiał szkoleniowy dla iod – jak się włączyć/nie włączyć w projektowanie aplikacji i jak stawiać pytania. Podoba mi się również algorytmiczność wywodu i wskazanie szeregu dziedzin które wpływają na działanie programu.
No i ten nieśmiertelny excel 🙂
Ja ma inny pomysł na losowanie.
1. Zainteresowani losowaniem sędziowie wymyślają/generują dowolne liczby.
2. Wyliczają z nich skrót np md5
3. Upubliczniają skróty.
4. Ogłaszają wymyślone liczby.
5. Każdy może sprawdzić czy liczby są zgodne z md5.
6. Dodajemy do siebie liczby.
7. Sumę dzielimy modulo przez liczbę zainteresowanych sędziów i mamy uczciwy wynik.
PS. md5 (lub jakiś sha) jest wyliczany dla każdej z liczb z osobna. Więc każdy sędzia ogłasza własny skrót.
Nie rozumiem tej części matematycznej, ale warto wspomnieć, że sędziowie będą bardzo zainteresowani, żeby wpłynęło do nich jak najmniej spraw.
Cześć Magdo,
postaram się opisać algorytm na przykładzie.
Mamy 3 sędziów A B C.
1. Każdy z nich wymyśla jakąś liczbę z dużego zakresu i zachowuje ją w tajemnicy. [ np: A = 67, B = 23, C = 12].
2. Następnie każdy sędzia przepuszcza swoją liczbę przez funkcję skrótu np. sha1.
3. Sędziowie upubliczniają swoje wyniki sha1:
A = TYnSlM1MqfLKV9wkpT/7PvUwMSI
B = 1DWmzdeGMA3/IE7nwu+ULT6QNOI
C = e1IAm2T9CipJ5tipOXUwd3krBVQ
4. Gdy wszystkie sha1 są publiczne sędziowie publikują liczby z punktu 1.
5. Każdy sprawdza czy pozostali sędziowie nie oszukują, czy po publikacji skrótów nie zmienili swojej liczby tak by wynik obliczeń był na ich korzyść. Upewniają się czy sha1 z punktu 1 faktycznie powstaje z podanych liczb.
6. Liczby sumujemy [A + B + C = 67 + 23 +12 = 102], a wynik dzielimy modulo przez ilość sędziów [102 % 3 = 0].
7. Wylosowany został sędzia nr zero (czyli sędzia A).
Sędziowie nie mogą przewidzieć wyniku. Po opublikowaniu wartości sha nie mogą skorygować swojej liczby. Więc mają poczucie sprawiedliwości. Oczywiście zakres liczb musi być na tyle duży by nie miało sensu robienia słownika liczba – skrót.
PS. Wiarygodną liczbę losową możemy też pobrać z blockchainu. Np. Bitcoin w nagłówku ma pole Nonce które powinno się do tego świetnie nadać.
Wówczas z powyższego algorytmu można wyrzucić punkty 1-5.
Z jednej strony – najważniejsze jest poznanie jak działa program, można z niego odtworzyć „ostateczny” algorytm użyty.
Ale informacja czego dokładnie chciał zamawiajacy jest też bardzo istotna. Bo może np. dowiemy się, że zamawiający już na starcie zamówił backdoor, umożliwiający wpłynięcie na wynik losowania? To jest bardzo ważna sprawa, pokazująca na ile zgniłe jest środowisko ministerstwa.
Więc moim zdaniem należy domagać się obu tych informacji.
Tak dla zobrazowania wozu z dyszlem z tyłu:
https://www.pinterest.com/pin/460704236872509462/
Bedą jeszcze nowe wpisy?
Będą
Jako prawnik czekam na Twój komentarz do opublikowanego algorytmu.
Większość z nas napisałoby w pojedynkę lepiej działający prototyp w 2 tygodnie (jeśli nie szybciej). Co oni, do jaśnie pana, robili przez dwa lata!?