
Oto drugi odcinek Poradnika dla sponiewieranych Excelem, w którym poznajemy alternatywne metody pracy z danymi. Dziś spojrzymy na podstawową strukturę języka R czyli ramkę danych. Aby lepiej zrozumieć, o czym mowa, wróćmy na chwilę do Excela.
Gdy włączymy program Microsoft Excel i utworzymy nowy arkusz, zobaczymy rzędy i kolumny komórek, które można wypełniać wartościami i formułami. Wiersze są oznaczone cyframi, kolumny są oznaczone literami. Każda komórka ma swój adres, np A1 albo B23.
Jednym z pierwszych stopni wtajemniczenia jest użycie znaków dolara przy indeksach wierszy i kolumn – możemy w ten sposób „zablokować” odniesienia w formułach przenoszonych w inne miejsca. Zakładam, że bez wahania opiszesz różnice między adresami C4, C$4 oraz $C$4. To Excelowa podstawówka.
Nazwane zakresy w Excelu
Nieco rzadziej, niż z adresów, korzystamy z nazwanych zakresów – prostokątnych fragmentów arkusza, którym nadajemy własne nazwy. Potem możemy odwoływać się do tych nazw m.in. w formułach:

(kliknij aby powiększyć)
Nazwane zakresy są przydatne, gdy chcemy szybko zmieniać zakres danych, na których przeprowadzamy obliczenia. Na obrazku poniżej widzimy, jak w Menedżerze nazw (zakładka Formuły) rozszerzyć zakres komórek istniejącego nazwanego zakresu

(kliknij aby powiększyć)
Spójrzmy na konkretny przykład. Będzie nim wspomniany tydzień temu plik CSV z listą 117 tysięcy ogłoszeń sprzedaży aut z serwisu OtoMoto. Zakładam, że umiesz zaimportować ten plik do Excela:
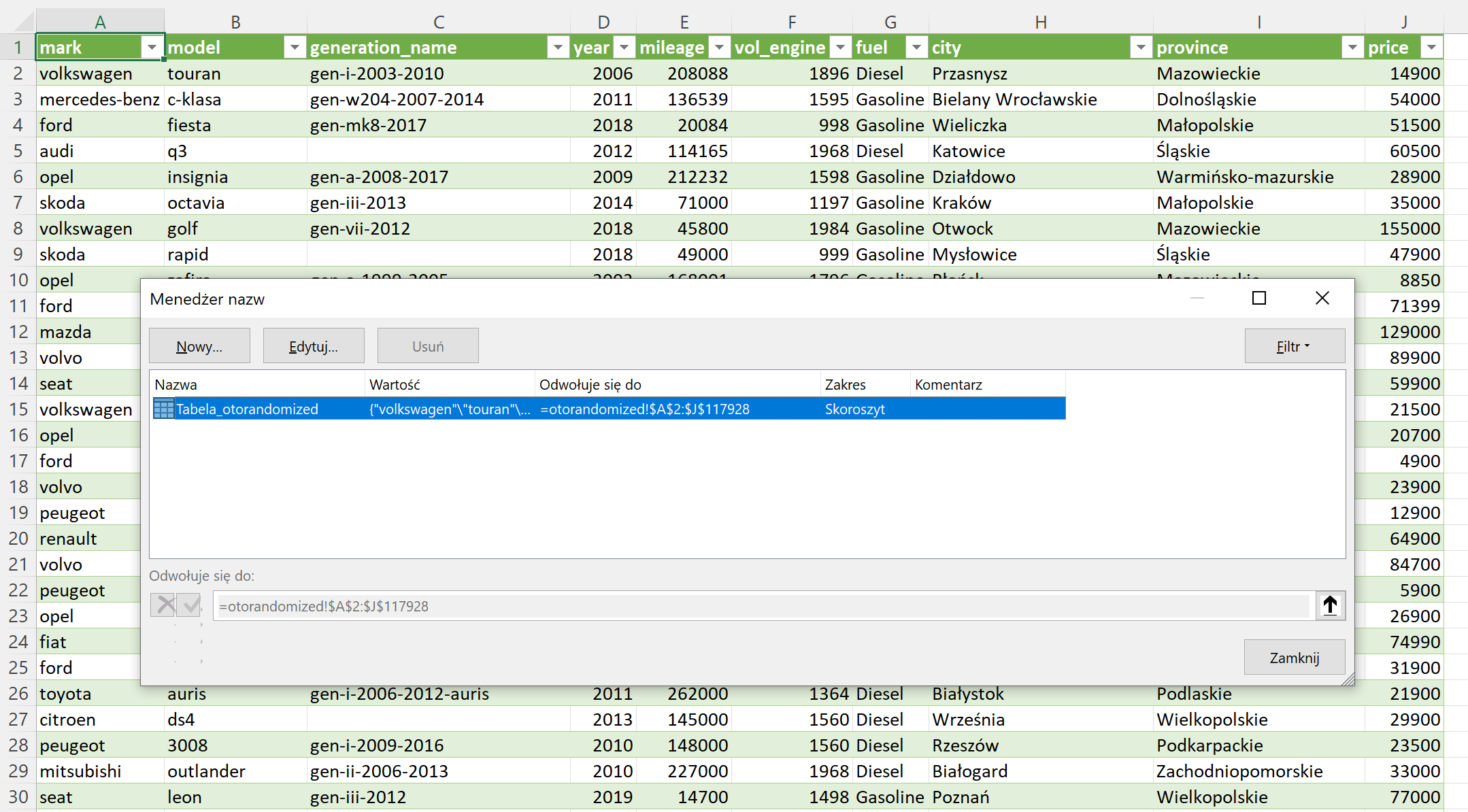
W mojej wersji Excela ten zakres (składający się z 10 kolumn i 117928 wierszy) otrzymał automatycznie nazwę „Tabela_otorandomized”. Każdy wiersz tego zakresu to osobna oferta sprzedaży. Każda kolumna to atrybut, jakim opisane są oferty, np. marka samochodu, jego przebieg i cena.
Nie wszyscy wiedzą, że nagłówki Tabel w Excelu pełnią szczególną rolę i pozwalają na użycie tzw. odwołań strukturalnych. Przykład: nowa kolumna zawierająca podwojoną cenę samochodu może być wyliczona formułą = 2 * Tabela_otorandomized[@price]
Ramka danych w R
Taką strukturę, jak excelowa Tabela – z obserwacjami w wierszach i atrybutami w kolumnach – będziemy w języku R nazywać ramką danych. Ramki danych noszą nazwy, podobnie jak nazwane zakresy Excela.
Zobaczmy, jak utworzyć ramkę danych z pliku CSV:
setwd("c:/users/tomek/dane")
otomoto <- read.csv("otorandomized.csv")
„otomoto” jest tu nazwą zmiennej przechowującej ramkę danych. Operator „<-” dokonuje przypisania nazwie po lewej stronie wartości zwracanej przez wyrażenie po prawej stronie. Funkcja read.csv odczytuje plik CSV i przekształca go do postaci ramki danych.
Jak podejrzeć strukturę i zawartość ramki danych? Najprościej – w okienku RStudio. Klikamy trójkącik przy nazwie w zakładce „Environment”, by obejrzeć strukturę ramki danych. Widzimy listę kolumn wraz z typami oraz podglądem kilku pierwszych wartości.

Kliknijmy nazwę „otomoto” obok trójkącika, a w panelu po lewej stronie otworzy się nowa zakładka prezentująca dane w znajomym układzie wierszy i kolumn. Zwróćmy jednak uwagę – kolumny są opisane nazwami, nie – jak w Excelu – literami. Drugie spostrzeżenie – w ramce danych cała kolumna ma zawsze jednakowy typ
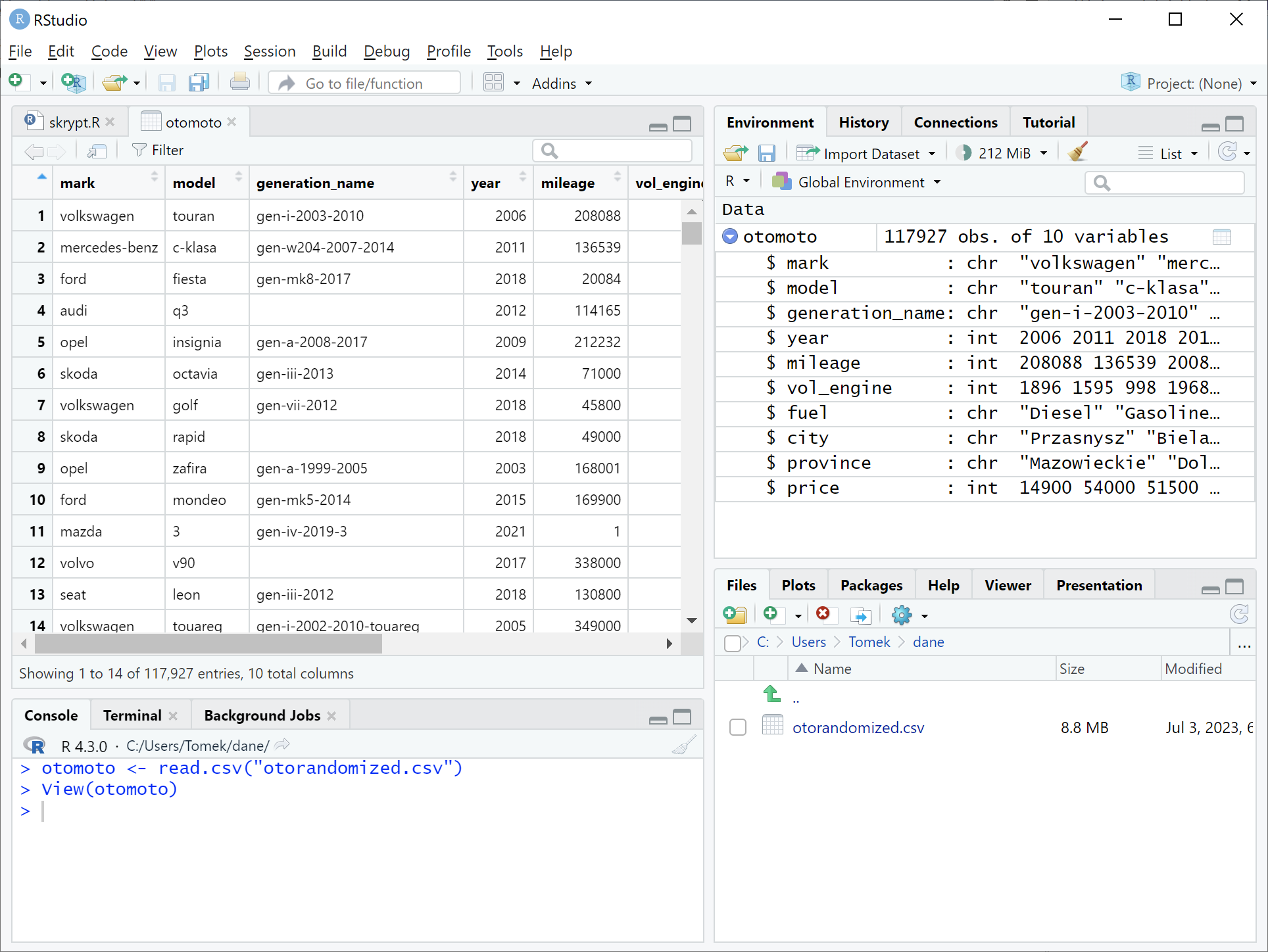
W Excelu dane w całym arkuszu dzielą wspólną przestrzeń, wspólny obszar wierszy i kolumn. Jeśli z jednego zestawu danych tworzymy drugi, to umieszczamy go zazwyczaj pod pierwszym albo na prawo od niego (albo na osobnej karcie).
Ramki danych w R nie mogą „zachodzić na siebie”, bo wiersze i kolumny różnych ramek są od siebie całkowicie niezależne. W języku R nie będziemy więc stosować „globalnych” adresów w rodzaju C4, lecz – podobnie jak w excelowych odwołaniach strukturalnych – użyjemy nazw kolumn.
Pamiętacie jeszcze zadanie z pierwszego maila? Chodziło o wskazanie trzech najpopularniejszych modeli samochodów każdego producenta aut z literą „d” w nazwie, ale tylko wtedy, gdy OtoMoto ma w ofercie co najmniej pięć tysięcy aut tego producenta. Rozwiązanie było następujące
otomoto %>%
mutate(oferty_marka = n(), .by=c(mark)) %>%
summarise(oferty_markamodel=n(), .by = c(mark, model, oferty_marka) ) %>%
arrange(desc(oferty_markamodel)) %>%
slice_head(n=3, by=mark) %>%
filter( oferty_marka>5000 & grepl("d", mark) )
Teraz najfajniejsze – wynik tego przekształcenia również jest ramką danych! Możemy nadać jej nazwę:
wybraneoferty <- otomoto %>%
mutate(oferty_marka = n(), .by=c(mark)) %>%
summarise(oferty_markamodel=n(), .by = c(mark, model, oferty_marka) ) %>%
arrange(desc(oferty_markamodel)) %>%
slice_head(n=3, by=mark) %>%
filter( oferty_marka>5000 & grepl("d", mark) )
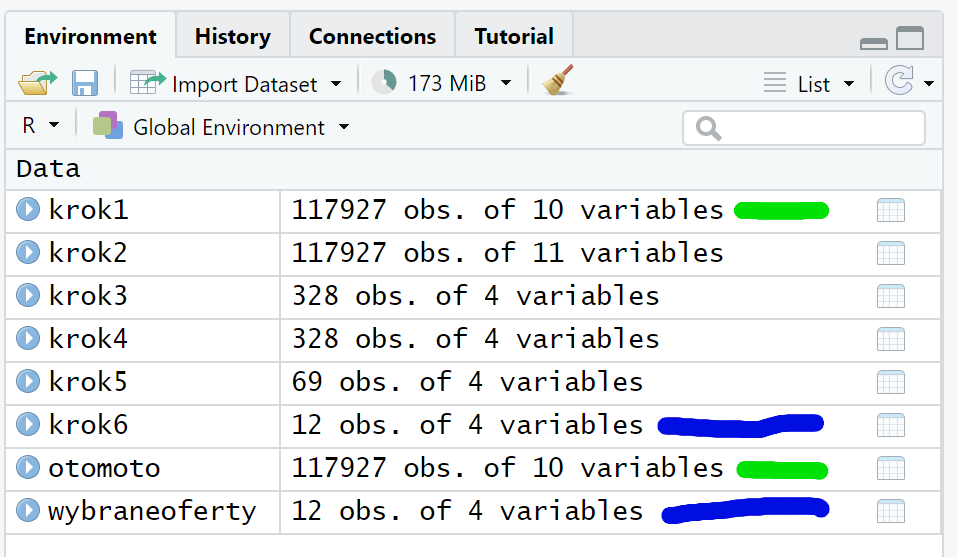
Zauważ, że w zakładce „Environment” pojawiła się druga zmienna, mająca cztery kolumny (zmienne) i dwanaście wierszy (obserwacji). Okienko poglądu pokaże tę ramkę danych w całości:

Tak naprawdę każdy kolejny wiersz naszego krótkiego skryptu produkuje nową ramkę danych, ale ramki te nie otrzymują własnych nazw. Operator %>% bierze taką wynikową ramkę danych i przekazuje jako dane wejściowe do polecenia w kolejnym wierszu. Zmiennej „wybraneoferty” przypisaliśmy wynik całego złożonego wyrażenia.
Przetwarzanie oddzielone od danych
W poprzednim odcinku wspominaliśmy już o tym, że w języku R dane są oddzielone od operacji na danych. Teraz widzimy, na czym to dokładnie polega – nasze dane źródłowe ładujemy do ramki danych, którą potem przekształcamy zestawem tekstowych instrukcji zapisanych w skrypcie.
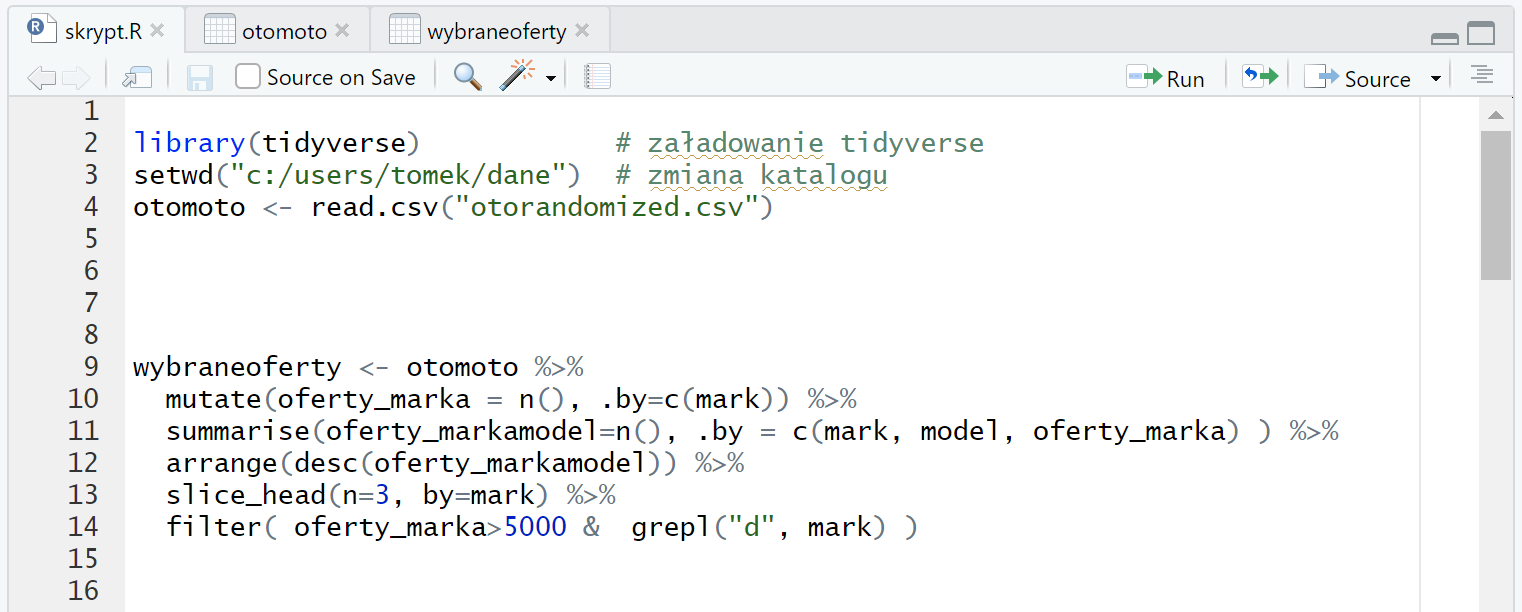
Ktoś może słusznie zauważyć, że dzięki połączeniom Excelowych tabel z plikami źródłowymi jesteśmy w stanie osiągnąć zbliżony poziom wygody – np. możemy podłączać ten sam arkusz do kolejnych plików CSV.
Język R wykaże jednak przewagę, gdy spojrzymy na tempo eksperymentowania i porównywania wyników różnych eksperymentów. Gdy w Excelu wycofamy się z jakiegoś pomysłu, znika on z arkusza na zawsze. W języku R możemy pozostawić sobie w zanadrzu stosowny fragment skryptu, by szybko wrócić do odrzuconego rozwiązania. Co więcej – wyniki każdego eksperymentu możemy przechowywać w osobnej ramce danych i w każdej chwili porównać je sobą.
Podsumowanie
Ramka danych będzie naszym podstawowym narzędziem. W kolejnych odcinkach cyklu nauczymy się odwoływać do wierszy i kolumn i przekształcać je na wiele sposobów.
W kolejnym mailingu Poradnika dla sponiewieranych Excelem rzucimy okiem na wykresy. Przygotowanie jednego wykresu trwa w Excelu krótką chwilę. Co jednak zrobić, gdy musimy ich przygotować setkę? Przy użyciu języka R przygotujesz cały zestaw w ciągu minuty!
Zadanie domowe
Ściągnij plik z danymi OtoMoto. Skopiuj do RStudio skrypt z tego odcinka, wykonaj go a potem zmodyfikuj tak, aby każdy krok obliczeń trafił do osobnej zmiennej. Oto początek sekwencji:
krok1 <- otomoto
krok2 <- krok1 %>% mutate(oferty_marka = n(), .by=c(mark))
krok3 <- krok2 %>% summarise(oferty_markamodel=n(), .by = c(mark, model, oferty_marka) )
[...]
Zaobserwujesz, jak zmienia się liczba wierszy i kolumn w ramkach danych będących rezultatem kolejnych kroków obliczeń. Obejrzyj każdą tak utworzoną ramkę danych.
Na końcu sprawdź, czy ramki danych krok6 i wybraneoferty mają identyczną zawartość.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

2 odpowiedzi na “Analiza danych w języku R – odcinek 2”
Napisałem to zapytanie w excelowym Power Query i też dało radę 😉
let
// Ładowanie danych
Source = Csv.Document(File.Contents(„C:\R\otorandomized.csv”),[Delimiter=”,”, Columns=11, Encoding=65001, QuoteStyle=QuoteStyle.None]),
#”Promoted Headers” = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
// Zliczanie liczby aut dla każdego producenta
CountByProducer = Table.Group(#”Promoted Headers”, {„mark”}, {{„liczba_aut_producenta”, each Table.RowCount(_), type number}}),
// Filtrowanie producentów, dla których OtoMoto ma co najmniej 5000 aut w ofercie
FilteredProducers = Table.SelectRows(CountByProducer, each [liczba_aut_producenta] >= 5000),
// Filtrowanie samochodów zawierających literę „d” w nazwie producenta
FilteredData = Table.SelectRows(#”Promoted Headers”, each Text.Contains(Text.Lower([mark]), „d”)),
// Łączenie filtrowanych danych z listą producentów
MergedData = Table.Join(FilteredData, „mark”, FilteredProducers, „mark”),
// Grupowanie danych po producencie i modelu, zliczanie ilości aut każdego modelu
GroupedData = Table.Group(MergedData, {„mark”, „model”}, {{„liczba_aut”, each Table.RowCount(_), type number}}),
// Tworzenie funkcji zwracającej trzy najpopularniejsze modele
Top3ModelsFunction = (group) => let
modelsSorted = Table.Sort(group,{{„liczba_aut”, Order.Descending}}),
top3Models = Table.FirstN(modelsSorted, 3)
in
top3Models,
// Wywołanie funkcji na każdej grupie
Top3Models = Table.Group(GroupedData, {„mark”}, {{„Top3Models”, each Top3ModelsFunction(_), type table}}),
// Rozwijanie tabeli z trzema najpopularniejszymi modelami
ExpandedTop3Models = Table.ExpandTableColumn(Top3Models, „Top3Models”, {„model”, „liczba_aut”}),
// Łączenie filtrowanych danych z listą producentów
MergedData2 = Table.Join(FilteredProducers, „mark”,ExpandedTop3Models , „mark”),
// Usuwanie zbędnych kolumn
FinalResult = Table.SelectColumns(MergedData2, {„mark”, „model”,”liczba_aut_producenta”, „liczba_aut”})
in
FinalResult
Szanuję!