
Tworzenie wykresu w Excelu przypomina trochę rysowanie go na papierze – decydujemy o doborze kolorów, grubości linii, opisach osi, położeniu legendy i tak dalej. Po mniejszej lub większej liczbie kliknięć mamy gotowy wykres.
Filozofia języka R (a dokładniej: biblioteki ggplot2 z pakietu Tidyverse) jest nieco inna i przypomina przekazywanie poleceń rysownikowi. Nie musimy opisywać każdego drobiazgu. Rysownik wie, jak się rysuje wykresy, więc będzie potrzebował jedynie zwięzłych instrukcji opisujących nasze oczekiwania.
Jak się już domyślacie, dziś poczytamy o wykresach.
Zastrzeżenie dotyczące przykładów
Od kilku osób usłyszałem uwagę, że składnia języka R jest trudna a w przykładach skaczę od razu na głęboką wodę, bez wprowadzenia podstaw. To prawda, ale w przyjętej formule nie da się przeprowadzić pełnego kursu języka programowania. Z tego właśnie powodu nie zaczynałem od omówienia typów, operatorów, podstawowych konstrukcji składniowych itp.
Mój pomysł na „Poradnik dla sponiewieranych Excelem” jest nieco inny. Pokazuję alternatywne metody pracy z danymi i demonstruję, że mogą one przynieść realne korzyści, oszczędzić czas i wysiłek. Przykład: w tym odcinku znajdziecie sposób na wygenerowanie kilkudziesięciu plików graficznych z wykresami przy użyciu kilku poleceń. Najważniejsza jest wiedza, że to możliwe. Zwięzłe fragmenty kodu pokazują, jak niewiele potrzeba do osiągnięcia rezultatu. Nie jest to jednak kompletny kurs języka programowania.
Dla wygody, na końcu maila znajdziesz link do dokumentu z wszystkimi przykładami, gotowymi do kopiowania i wklejania do RStudio.
Dane do wykresów
Nasze dzisiejsze dane to nadal Otomoto, ale tym razem ograniczymy się do samochodów wyprodukowanych w latach 2016-2021, kosztujących do 400 tys. zł.
otomoto <-
read.csv("otorandomized.csv") %>%
filter(price<=400000 & year>=2016 & year<2022) %>%
mutate(year_factor=as_factor(year))
Nowo utworzona zmienna „year_factor” ma typ kategoryczny, każdy rok jest tu odrębną wartością. Wprowadzamy ją, bo istniejąca zmienna liczbowa „year” byłaby w wielu sytuacjach traktowana jak wartość ciągła, liczba z określonego przedziału.
Przykłady prostych wykresów
Oto przykładowa sekwencja poleceń dla rysownika:
- weź dane z ramki danych otomoto
- na osi X umieść cenę auta
- wykreśl rozkład ofert sprzedaży przy podziale na 40 równych przedziałów cenowych
Takie polecenia, przełożone na język R i bibliotekę ggplot, będą wyglądały następująco:
otomoto %>%
ggplot(aes(x=price)) +
stat_bin(bins = 40)
Efekt:

Uwaga: funkcja ggplot, odpowiadająca za wizualizację danych, przyjmuje do wykonania serię komend oddzielonych znakiem „+” (plus). Należy więc pamiętać, że operator „%>%” będzie pojawiał się jedynie przed wywołaniem ggplot.
Dodajmy kolory ilustrujące rok produkcji auta i wartości liczbowe osi X czytelne dla zwykłego człowieka (domyślna dla R notacja naukowa wywodzi się ze świata akademickiego)
otomoto %>%
ggplot(aes(x=price, fill=year_factor)) +
stat_bin(bins = 40) +
scale_x_continuous(labels = scales::comma)
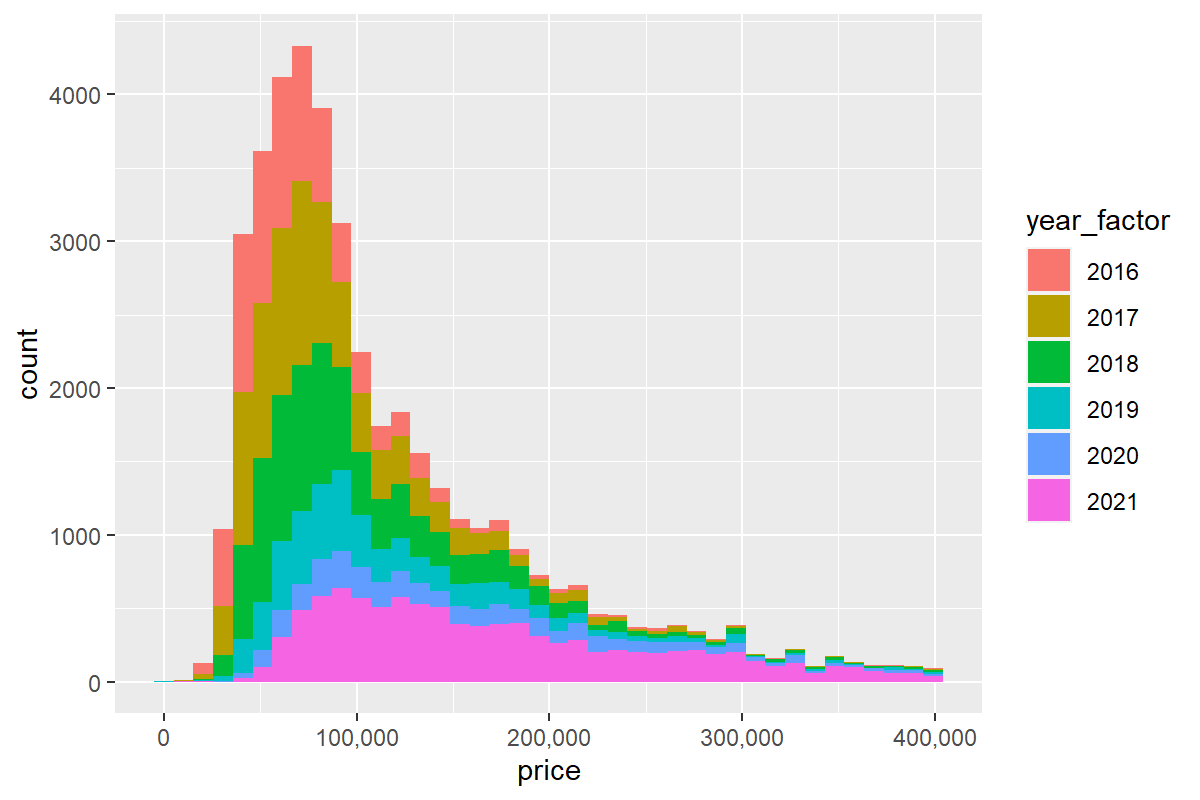
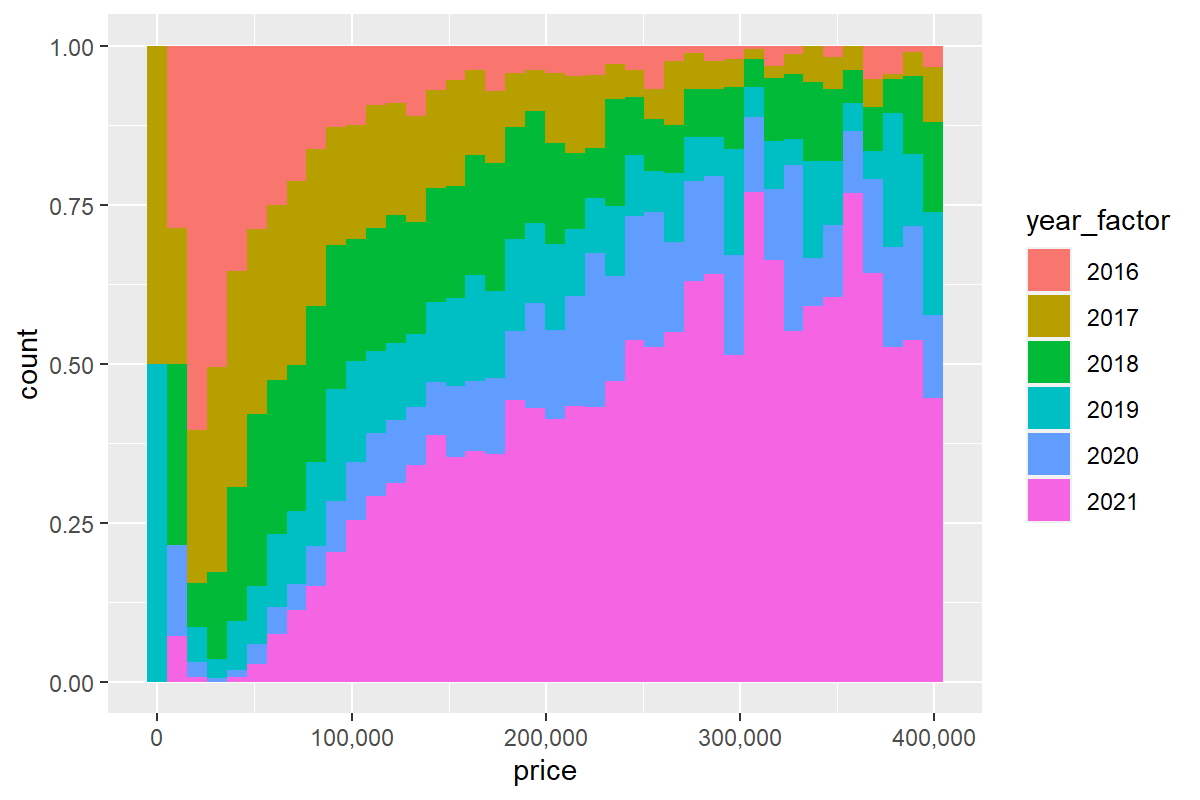
Chcemy poznać udział samochodów danego rocznika w każdym z przedziałów cenowych? Nic prostszego:
otomoto %>%
ggplot(aes(x=price, fill=year_factor)) +
stat_bin(bins = 40, position = "fill") +
scale_x_continuous(labels = scales::comma)
Wykresy nie są dość ładne? Podobnie, jak w Excelu, możemy użyć predefiniowanych styli. Sięgniemy do biblioteki ggthemes by wyprodukować wykresy w stylu dziennika Wall Street Journal…
otomoto %>%
ggplot(aes(x=price, fill=year_factor)) +
stat_bin(bins = 40) +
scale_x_continuous(labels = scales::comma) +
theme_wsj() + scale_fill_wsj()

… albo The Economist
otomoto %>%
ggplot(aes(x=price, fill=year_factor)) +
stat_bin(bins = 40) +
scale_x_continuous(labels = scales::comma) +
theme_economist() + scale_fill_economist()
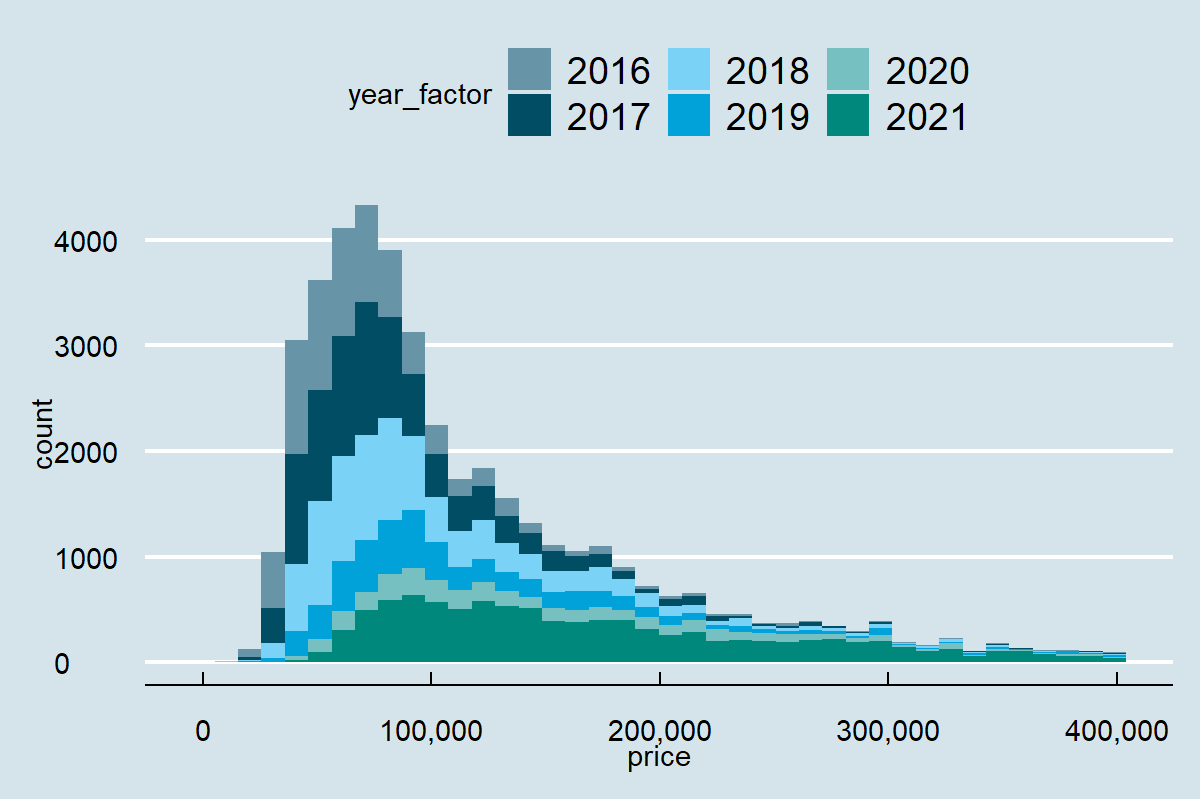
Zaletą takiego podejścia do tworzenia wykresów jest powtarzalność wyników i spójność graficzna. Wadą – trudność w dokonywaniu małych zmian formatowania ad hoc. Dostrojenie wyglądu wybranych elementów jest możliwe, ale wymaga zagłębienia się w meandry definicji stylów graficznych ggplot.
Wiele wykresów naraz
Siłą języka R jest rozszerzalność i łatwość automatyzowania różnych czynności. Chcemy obejrzeć serię wykresów z rozbiciem ofert na lata produkcji aut?
otomoto %>%
ggplot(aes(x=price, fill=year_factor)) +
stat_bin(bins = 40)+
scale_x_continuous(labels = scales::comma) +
facet_wrap( ~year_factor )
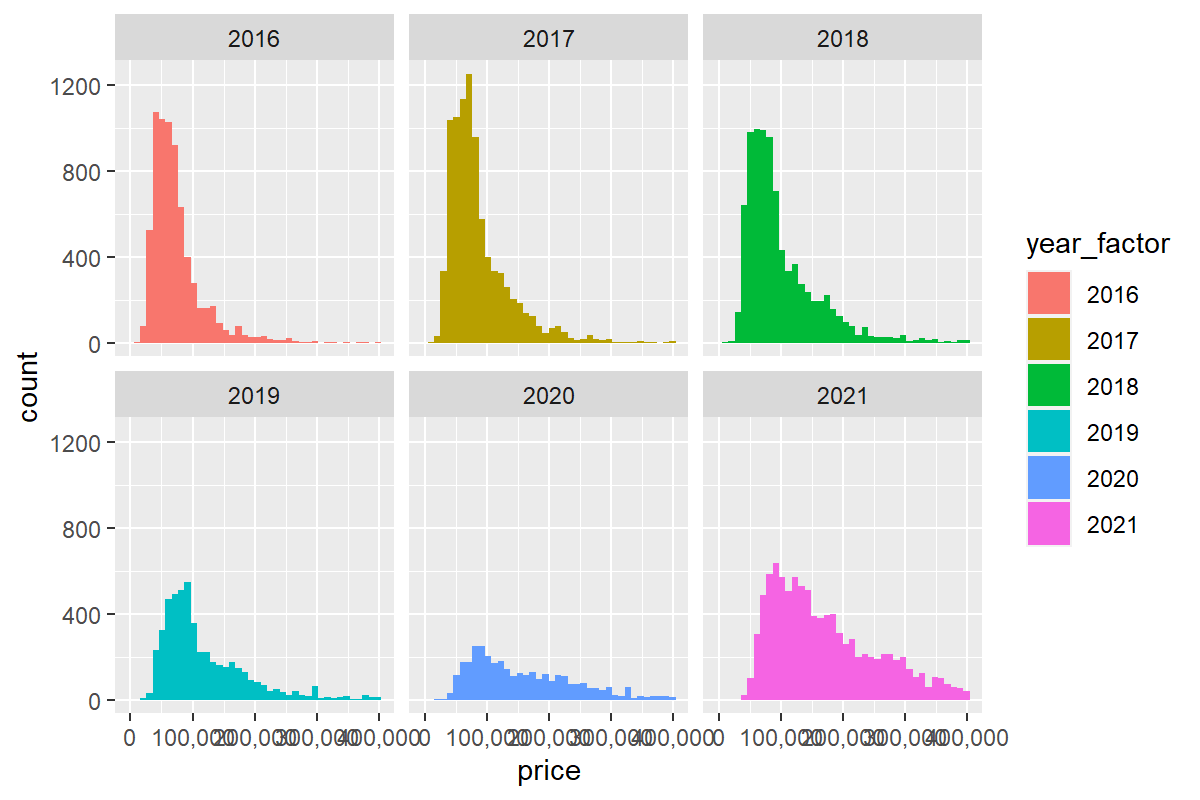
Chcemy zobaczyć wykresy z podziałem na rok produkcji oraz rodzaj napędu?
otomoto %>%
ggplot(aes(x=price, fill=year_factor)) +
stat_bin(bins = 40) +
scale_x_continuous(labels = scales::comma) +
facet_grid( vars(year_factor), vars(fuel) )
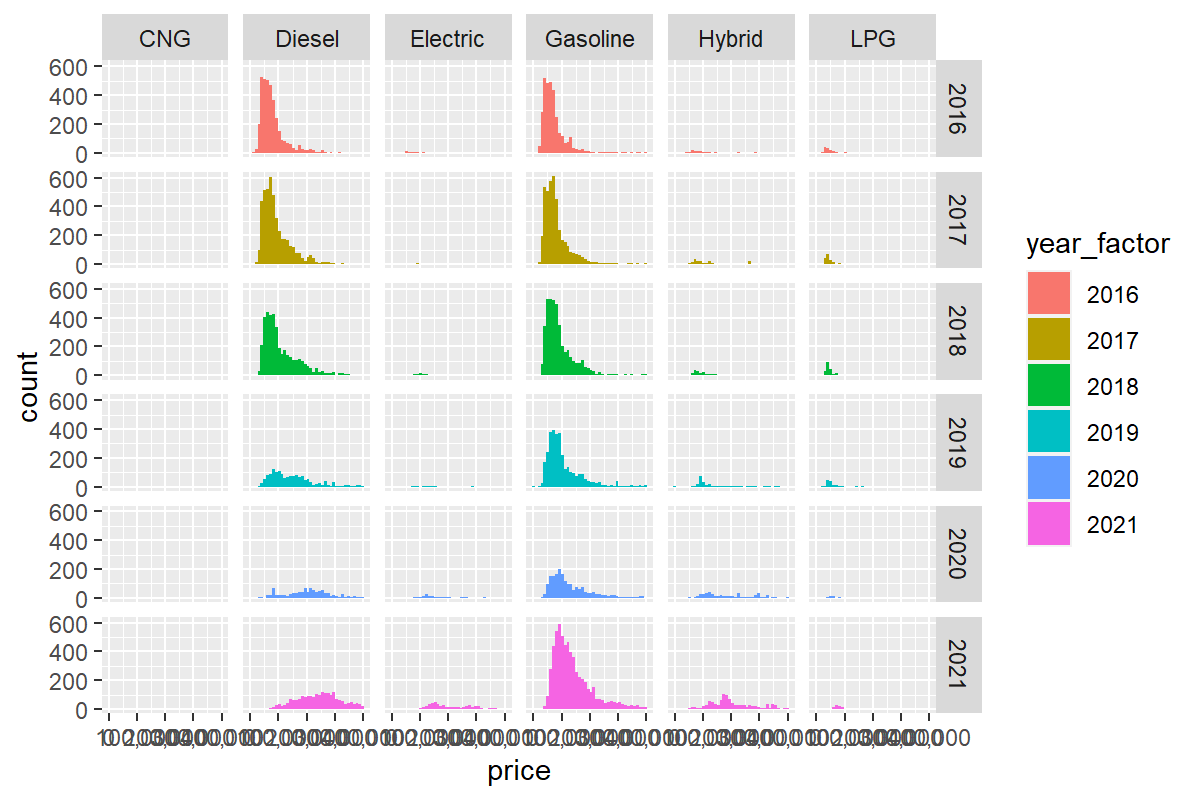
Automatyzacja tworzenia wykresów
Co zrobić, jeśli potrzebujemy każdego wykresu w osobnym pliku? W poniższym skrypcie dla wszystkich kombinacji lat i rodzaju napędu generujemy samodzielny wykres, który następnie zapisujemy do pliku PNG. Polecenie „ggsave” operuje zawsze na najnowszym wykresie wygenerowanym przez „ggplot”, nie musimy więc wprost przekazywać między poleceniami zmiennej przechowującej obiekt wykresu. Wykresów generowanych i zapisywanych w pętli „for” nie zobaczymy też w okienku podglądu RStudio.
for(y in unique(otomoto$year_factor)){
for (f in unique(otomoto$fuel)){
otomoto %>%
filter( year == y & fuel == f) %>%
ggplot(aes(x=price)) +
stat_bin(bins = 40) +
scale_x_continuous(labels = scales::comma, limits = c(0,400000))
ggsave(paste0(y,"_",f,".png"), width = 800, height = 600,
units = "px", dpi=200)
}
}
Efekt? W ciągu kilku sekund powstaje kilkadziesiąt plików z wykresami.
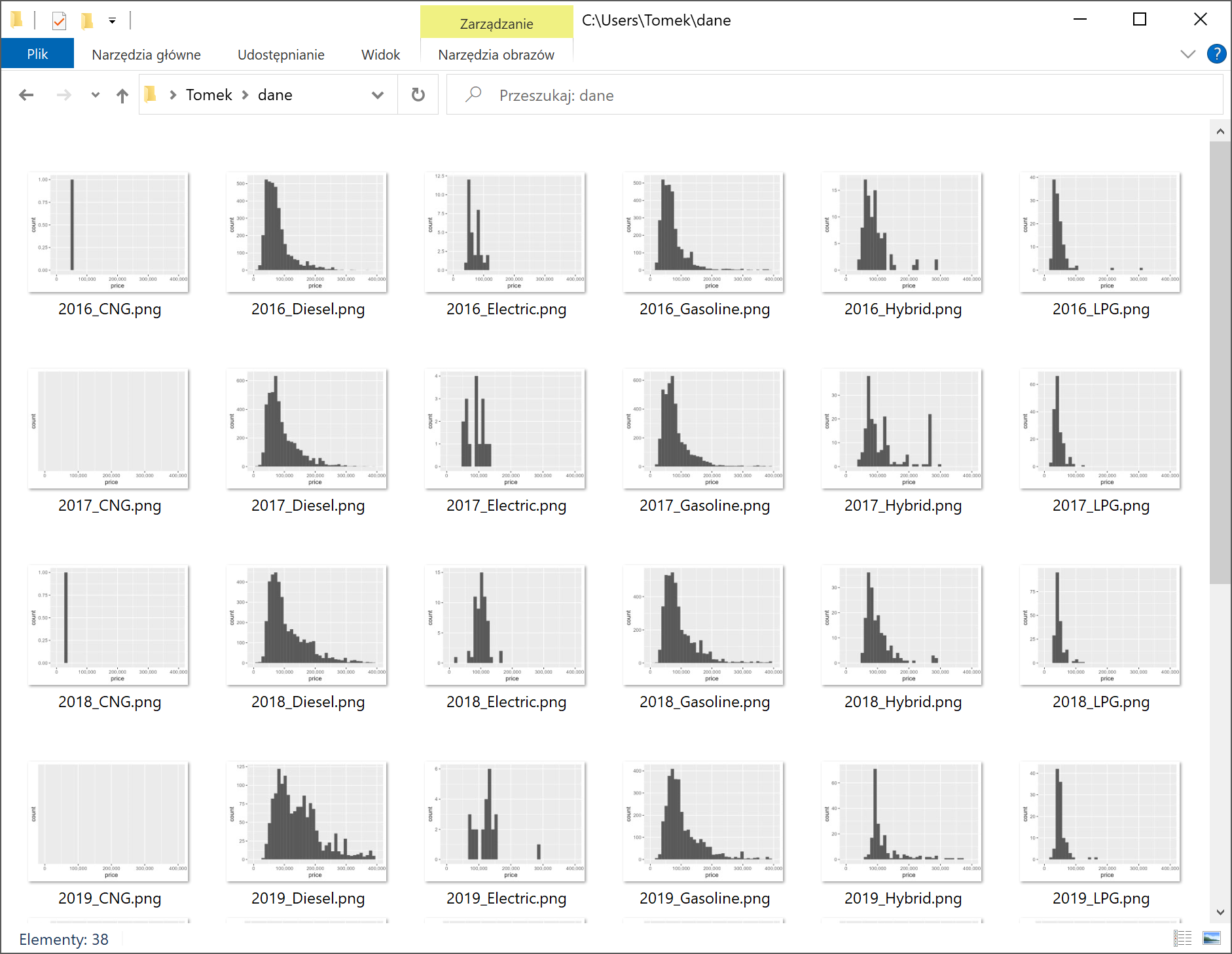
To właśnie w automatyzacji zadań drzemie prawdziwa moc R. Gdybyśmy ręcznie generowali kilkadziesiąt wykresów, pracochłonność takiego zadania praktycznie uniemożliwiłaby późniejsze naniesienie poprawek. Gdy wykresy generuje skrypt, możemy korygować i ulepszać je w dowolnym momencie.
Podsumowanie
Czy R i ggplot2 mogą całkowicie zastąpić wykresy z Excela? To zależy. Biblioteka ggplot2 niektórych rzeczy nie umie. Przykładem mogą być dwuwymiarowe wykresy z jedną osią poziomą i dwiema niezależnymi osiami pionowymi, prezentujące dwie serie pomiarów różnego typu (np. temperatury i ciśnienia).
Do tematu wizualizacji danych na pewno wrócimy. Dziś zobaczyliśmy jedynie prostą automatyzację, której rezultatem była seria plików graficznych. Na tym możliwości R się nie kończą. W przyszłości dowiemy się, jak wygenerować skryptem gotową prezentację i zapisać ją w formacie PDF albo PPTX (Microsoft Powerpoint).
A już za tydzień wczytamy do R plik XLSX i przekształcimy zawarte w nim dane, by potem zapisać je do innego pliku XLSX.
Zadanie domowe
Skrypt zawierający fragmenty kodu z dzisiejszego odcinka znajdziesz tutaj. Jeśli masz problem, bo przy próbie wykonania przykładowego kodu coś nie działa, zerknij na koniec tej blogonotki. Dodałem tam rozdział z rozwiązaniami problemów zgłoszonych przez uczestników Poradnika. Jeśli nie działa ci coś innego – napisz mi o tym!
Dzisiejsze zadanie – wróć do szóstego wykresu (tego z komendą facet_wrap) i wygeneruj kopię u siebie. Potem zastąp oba wystąpienia „year_factor” wartością „year”. Wygeneruj wykres ponownie. Czy potrafisz wyjaśnić, dlaczego legenda wygląda inaczej, niż poprzednio?
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

2 odpowiedzi na “Analiza danych w języku R – odcinek 3”
Proszę o ciąg dalszy! 🙂
Zaspałem, przepraszam. Będzie dziś lub jutro!