
W drugiej połowie 2023 roku rozpocząłem dystrybucję „Poradnika dla sponiewieranych Excelem”. Był to rozsyłany e-mailem cykl edukacyjny przeznaczony dla osób zainteresowanych automatyzowaniem analizy i wizualizacji danych. Jego zwieńczeniem miało być szkolenie, które nie doszło jednak do skutku.
Wiedza zawarta w „Poradniku” będzie aktualna przez długi czas, więc postanowiłem cały kilkunastuodcinkowy cykl opublikować na blogu. Jeśli znasz Excela w stopniu zaawansowanym, koniecznie sprawdź, jak usprawnić i przyspieszyć pracę przy użyciu języka R i środowiska RStudio!
To jest pierwszy odcinek Poradnika dla sponiewieranych Excelem. Zacznijmy od objaśnienia, co dokładnie znajdziesz w tym i kolejnych odcinkach wchodzących w skład cyklu.
Microsoft Excel to potężne narzędzie za pomocą którego można dokonać rzeczy zdumiewających. Niestety, niektóre z tych rzeczy wymagają gimnastyki albo pracy żmudnej i powtarzalnej. Jeśli te żmudne kawałki wchodzą w zakres naszych obowiązków służbowych, Excel będzie nas poniewierał co miesiąc.
Tu następuje pierwszy punkt zwrotny: niektóre zadania, które w Excelu zrealizować trudno, możemy ogarnąć innymi narzędziami w dwie chwile. Te narzędzia dostępne są za darmo a licencja pozwala na ich dowolne wykorzystanie – także do celów komercyjnych na komputerze służbowym.
Drugi punkt zwrotny: te narzędzia umieją odczytywać i zapisywać pliki Excela, więc nie musimy porzucać zgromadzonej wiedzy i doświadczenia. Możemy po prostu ułatwić i przyspieszyć pracę na tych odcinkach, gdzie Excel radzi sobie słabiej.
Do czego ludzie używają Excela?
Możemy wyróżnić trzy najpopularniejsze przypadki użycia arkusza kalkulacyjnego
- Arkusz jako narzędzie do tworzenia list, ramek lub formularzy – wypełnianych w samym programie lub przeznaczonych do wydrukowania. Formularz wypełniany w Excelu może zawierać formuły wyliczające np. kwotę diet za delegację – uczestnik podaje liczbę noclegów i posiłków a odpowiednia formuła wylicza kwotę do przelewu.
- Arkusz jako narzędzie do importu, gromadzenia i agregacji danych – np. sumowania miesięcznych regionalnych danych sprzedażowych w globalne raporty kwartalne.
- Arkusz jako narzędzie analityczne – pozwalające na eksperymentowanie z danymi w celu dotarcia do informacji ukrytych – np. wpływu temperatury i opadów na obroty firmy albo kwoty nakładów na reklamę przynoszących optymalny zwrot z inwestycji.
Jeśli twoje zastosowania Excela ograniczają się do punktu pierwszego – Poradnik nie jest dla ciebie. To moja wina, nie twoja. Excel jest świetnym narzędziem do ramek i formularzy, ale my zajmiemy się obróbką danych. Owszem, po drodze pojawią się wykresy, ale nie ramki.
Co musisz umieć, aby pójść dalej? Jeśli jesteś autorką/autorem makr – głośne hura! Spodoba ci się to, co zobaczysz w kolejnych odcinkach. Jeśli wiesz, do czego służą funkcje WYSZUKAJ.PIONOWO albo LICZ.JEŻELI – jesteś idealnym adresatem niniejszego poradnika! Jeśli masz na koncie arkusze z tabelami przestawnymi – też znajdziesz dużo dobra.
Jeśli jednak dopiero oswajasz się ze wstawianiem znaków „$” w odpowiednie fragmenty formuł Excela a na koncie masz pierwsze użycia funkcji SUMA albo ŚREDNIA – hmmm, to nie czas na zgłębianie Poradnika. Excel cię jeszcze nie sponiewierał.
O czym będzie Poradnik?
Czas zdradzić ciąg dalszy – w kolejnych odcinkach przedstawię podstawy języka R oraz środowiska RStudio. Programy te są darmowe a licencja pozwala na ich dowolne użycie – także do celów komercyjnych na komputerach służbowych! Aby poznać siłę języka R, spójrzmy na prosty przykład.
Strona Kaggle zawiera dane z serwisu OtoMoto ze stycznia 2022 – to 117 tysięcy ofert sprzedaży samochodów. Dane obejmują m.in. markę, model, cenę, przebieg, typ paliwa. Jeśli wczytamy je do Excela, będzie to wyglądało jakoś tak:
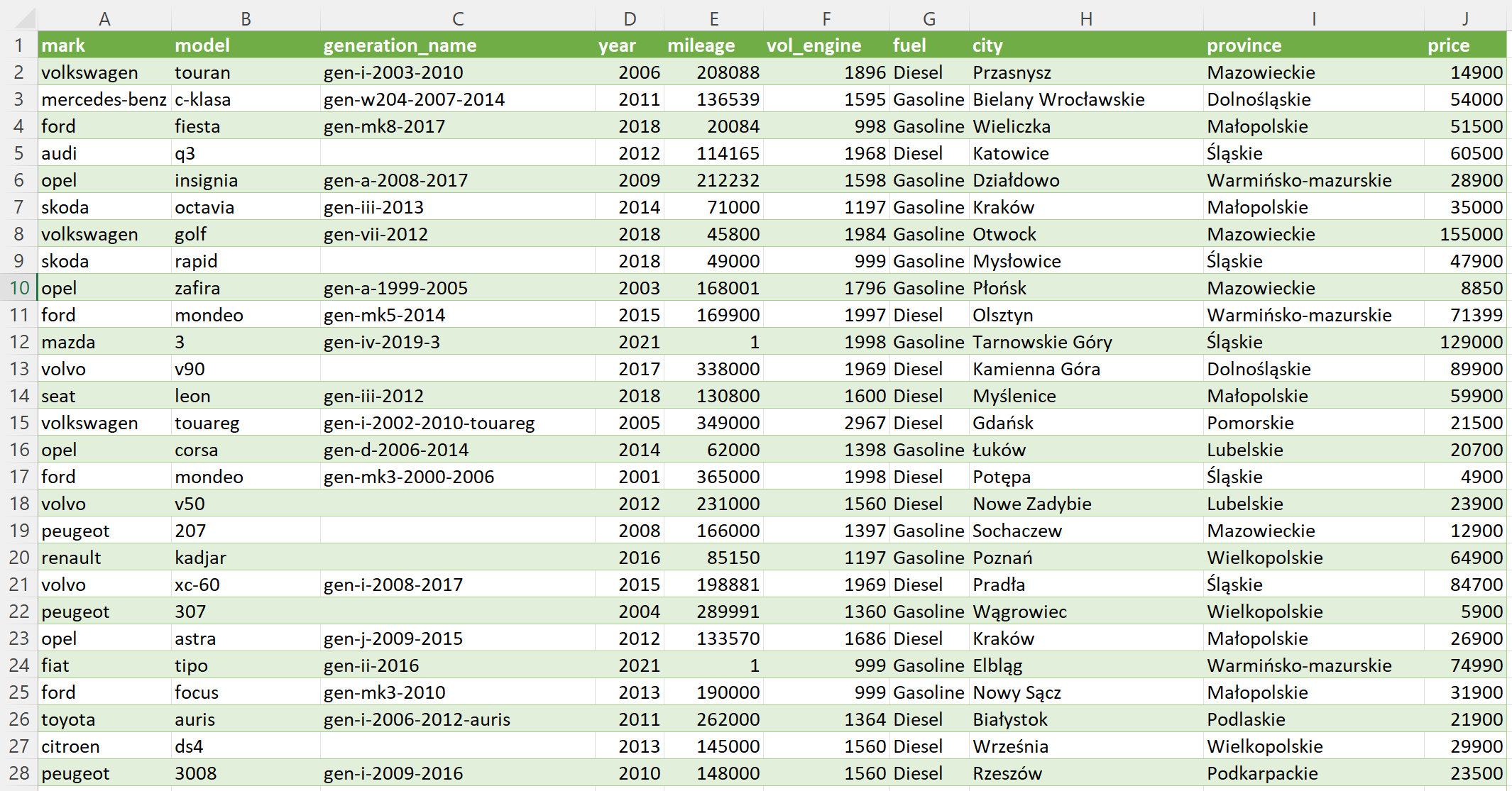
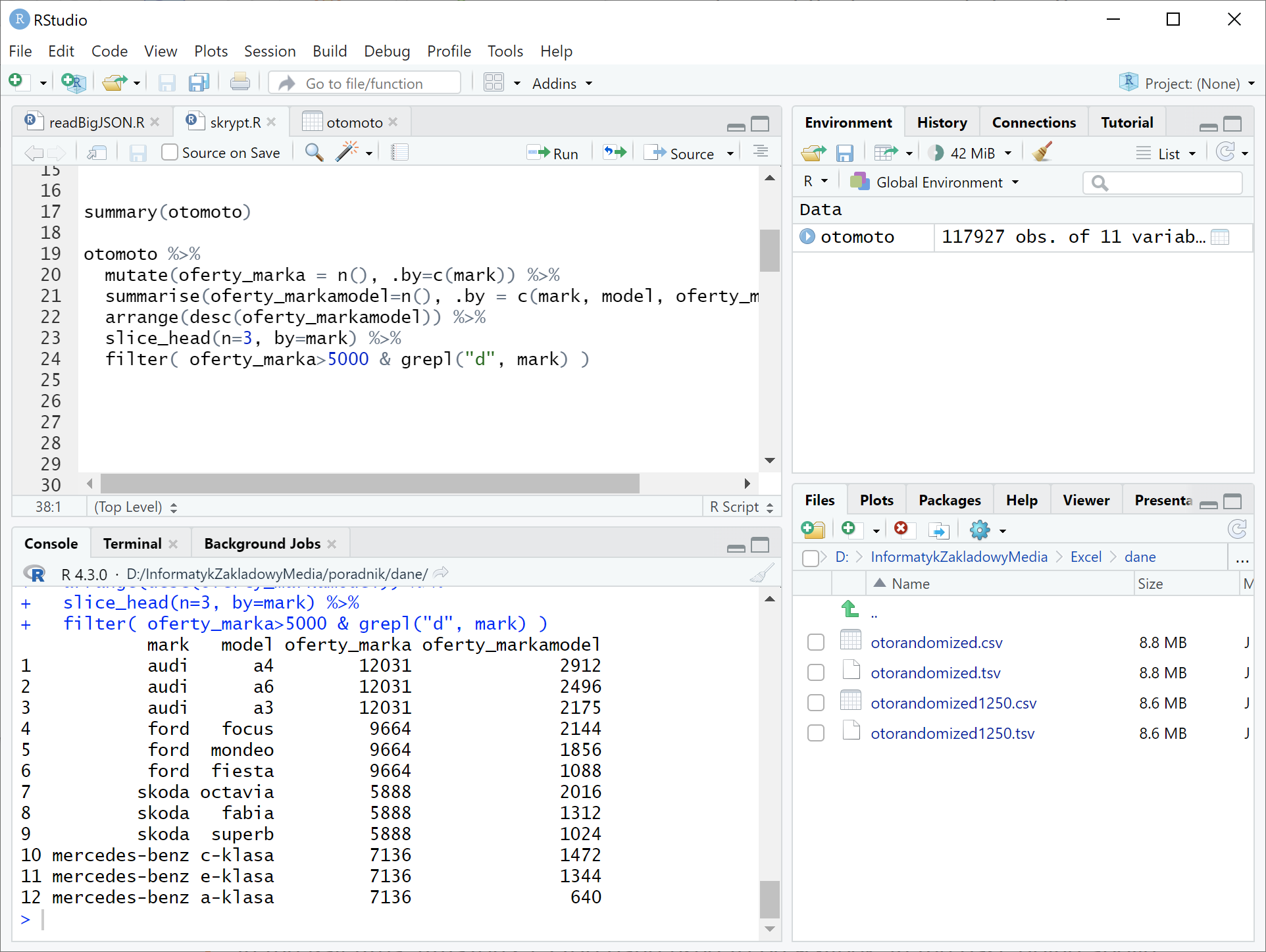
Zadanie, jakie przed nami stoi, to wskazanie trzech najpopularniejszych modeli samochodów każdego producenta aut z literą „d” w nazwie, ale tylko wtedy, gdy OtoMoto ma w ofercie co najmniej pięć tysięcy aut tego producenta. Brzmi… kłopotliwie? Cóż, w Excelu czeka nas sporo manualnej pracy. Do tego małe szanse, aby nasze tabele przestawne dało się szybko przestawić (badum tsss…) na co piąty najpopularniejszy model, prawda? Zobaczmy, jak będzie wyglądało rozwiązanie w języku R:
Wariant podstawowy:
otomoto %>%
mutate(oferty_marka = n(), .by=c(mark)) %>%
summarise(oferty_markamodel=n(), .by = c(mark, model, oferty_marka) ) %>%
arrange(desc(oferty_markamodel)) %>%
slice_head(n=3, by=mark) %>%
filter( oferty_marka>5000 & grepl("d", mark) )
Dziś nie będziemy pochylać się nad składnią ani dokładnym znaczeniem powyższych poleceń. Wskażę tylko rolę poszczególnych wierszy, by udowodnić, że złożoność całego polecenia jest pozorna:
- odwołanie do danych (wczytanych – podobnie, jak w Excelu – do wierszy i kolumn)
- dodanie nowej kolumny z łączną liczbą ofert danej marki
- dodanie nowej kolumny z łączną liczbą ofert dla kombinacji marki i modelu
- sortowanie danych malejąco względem liczby ofert wyliczonych w kroku 3
- pozostawienie po trzy pierwsze wiersze dla każdej marki
- pozostawienie tylko marek z literą „d” w nazwie i liczbą ofert przekraczającą pięć tysięcy
Wynik uruchomienia powyższego skryptu:
mark model oferty_marka oferty_markamodel
audi a4 12031 2912
audi a6 12031 2496
audi a3 12031 2175
ford focus 9664 2144
ford mondeo 9664 1856
ford fiesta 9664 1088
skoda octavia 5888 2016
skoda fabia 5888 1312
skoda superb 5888 1024
mercedes-benz c-klasa 7136 1472
mercedes-benz e-klasa 7136 1344
mercedes-benz a-klasa 7136 640
Całkiem efektywna metoda pracy, prawda? Ale, ale! Co musimy zrobić, by przestawić obliczenia na co piąty najpopularniejszy model auta? Wystarczy, że piątą linijkę zamienimy na:
slice(which(row_number() %% 5 == 1), .by=mark) %>%
Wiele osób dostrzega już w tym miejscu jedną z największych zalet przetwarzania danych przy użyciu sekwencji poleceń. Dane są oddzielone od operacji na danych. To kluczowa różnica, dzięki której eksperymentowanie i eksploracja danych są w przypadku języka R znacznie szybsze i wygodniejsze.
Pozwól, że w nadchodzącym cyklu będę twoim przewodnikiem po tym nowym świecie. Jeśli chcesz zacząć eksperymentować już teraz, zapraszam do blogonotki opisującej instalację języka R oraz środowiska RStudio.
Dlaczego R a nie Python?
Po pierwsze: bo Python jest językiem ogólnego przeznaczenia, zaś R jest językiem przeznaczonym do obróbki i analizy danych. Gdy przed wyborem stoi sponiewierany użytkownik Excela, nauka R przyniesie szybszy zwrot z inwestycji.
Po drugie: bo istotną część pracy w Excelu stanowi sporządzanie wykresów, zaś ggplot (biblioteka R) jest narzędziem o większych możliwościach od matplotlib (biblioteka Pythona) i lepiej wpisze się w naszą docelową metodę pracy z danymi
Po trzecie: bo RStudio jest środowiskiem dojrzalszym od pythonowych alternatyw, a konfigurowanie Anacondy, pip-a i późniejsza aktualizacja środowisk wirtualnych jest (moim zdaniem) trudniejsza do ogarnięcia. Użytkownicy Excela nawykli do narzędzi wizualnych, więc RStudio będzie dla nich prostszy do opanowania.
Podsumowanie
Jeśli nie wiesz jeszcze, czy RStudio i język R są dla ciebie – doskonale to rozumiem! Na razie nowe techniki mogą wydawać się skomplikowane a sposób ich użycia – zagmatwany.
Już za tydzień napiszę o tym, w jaki sposób język R przechowuje dane i jak oglądać je w RStudio. Później rzucimy okiem na tworzenie wykresów a jeszcze później zajmiemy się wczytywaniem i zapisywaniem danych z i do plików Excela.
Czy masz w swoim otoczeniu ludzi pracujących z Excelem? Prześlij im link do niniejszej strony. Razem łatwiej będzie wam się uczyć!
Zadanie domowe (nieobowiązkowe)
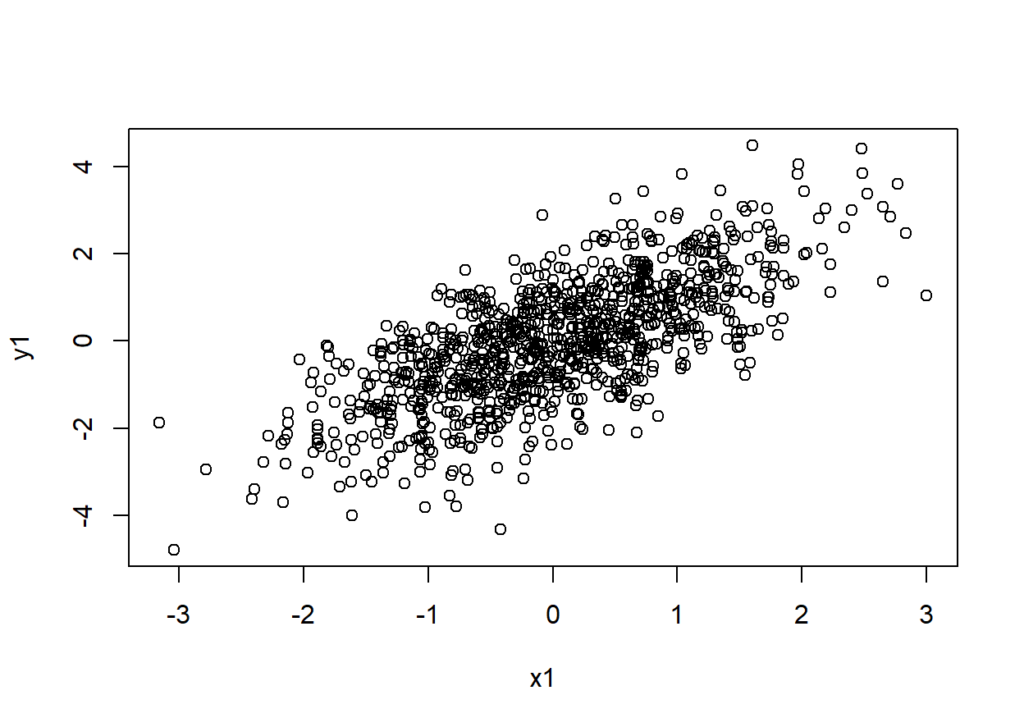
Zadaniem domowym jest wykonanie kroków opisanych na blogu – zainstaluj R, zainstaluj RStudio, uruchom komendę:
x1 <- rnorm(1000); y1 <- x1 + rnorm(1000); plot(x1, y1)
Zadanie będzie zaliczone, jeśli zobaczysz wykres podobny do poniższego.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

2 odpowiedzi na “Analiza danych w języku R – odcinek 1”
Spróbowałem odtworzyć wyniki za pomocą TSQL dla SQL Server, też nie za długi kod, choć R wydaje się bardziej intuicyjny i przejrzysty.
select * from
(
select c.mark,c.model,modeli=count(*)
,lp=ROW_NUMBER() over(partition by c.mark order by count(c.mark) desc)
,ileMarki.ileMarki
from [dbo].[Car_Prices_Poland_Kaggle] c
outer apply (select count(*) ileMarki from [dbo].[Car_Prices_Poland_Kaggle] where mark = c.mark) ileMarki
where c.mark like '%d%’ and ileMarki.ileMarki>=5000
group by c.mark, c.model,ileMarki.ileMarki
) a
where a.lp<=3
Może nie R i nie Excel, ale u mnie jest wielka miłoszcz do Visidata. Wszystko do ogarnięcia z klawiatury, łyka milion formatów i jest całkiem intuicyjny. Może nie jest demonem prędkości – ale wciągałem do niego półgigowe pliki i dał radę, a sam workflow jest fantastyczny do robienia rzeczy, które niekoniecznie musimy wizualizować.