
W pracy z danymi można wyróżnić kilka etapów. Pierwszym jest import danych, omówiliśmy go pobieżnie w odcinku czwartym. Ostatnim będzie analiza i wyciąganie wniosków. Etap pośredni to dostosowanie załadowanych danych do postaci najbardziej dogodnej do przetwarzania – tym tematem zajmiemy się dzisiaj.
Bardzo rzadko kontrolujemy format i „kształt” danych wejściowych. Najczęściej dostaniemy na twarz zestaw plików CSV albo XLSX o losowym układzie i przypadkowym nazewnictwie kolumn. Dla początkujących analityków będzie to dużą niespodzianką, ale w projektach Data Science nierzadko 80% czasu spędzimy na… konwersji i łączeniu danych z różnych źródeł.
Proces dostosowania danych
Język R pozostawia nam na etapie transformacji danych dużą swobodę działania. Gdy wczytamy ramkę danych, najpierw zajmujemy się podstawami: dostosowaniem nazewnictwa kolumn, typów pól (np. zamiana tekstu na daty), konwersją typów kategorycznych itd. Tego typu podstawowe przekształcenia przeprowadzamy z reguły „w miejscu”, nadpisując istniejące pola i kolumny.
Na tym etapie często przeprowadzamy też walidację danych – np. kontrolę zakresów liczb i dat albo sprawdzenie, czy w ramce danych nie występują niepożądane „dziury” (pola bez zawartości, oznaczane jako NA).
Potem zajmiemy się dostosowaniem danych do potrzeb przyszłej analizy i tu pośrednie etapy pracy mogą trafiać do kolejnych ramek danych. Zapoznaliśmy się już z możliwością zapisu i odczytu danych do pliku. Pamiętajmy o tym, gdy zbiór danych jest bardzo duży a operacje na nim – długotrwałe. Możemy weryfikować poprawność przekształceń na małej części zbioru a potem odpalić operację na całym zbiorze i pójść po kawę. Wynik długotrwałych obliczeń zapiszemy do pliku – dzięki temu będziemy mieli punkt pośredni do którego można szybko wrócić.
Przyjrzyjmy się teraz operacjom, jakie mogą przydać nam się w procesie przekształcania ramki danych.
Transpozycja
Jedną z najprostszych operacji jest transpozycja obszaru czyli zamiana wierszy i kolumn. W Excelu służy do tego formuła tablicowa TRANSPONUJ, która tworzy nowy obszar zawierający dane powiązane z lokalizacją źródłową.

Ja częściej korzystam z opcji wklejania przetransponowanych danych. W takim przypadku powstająca kopia jest niezależna od danych źródłowych.
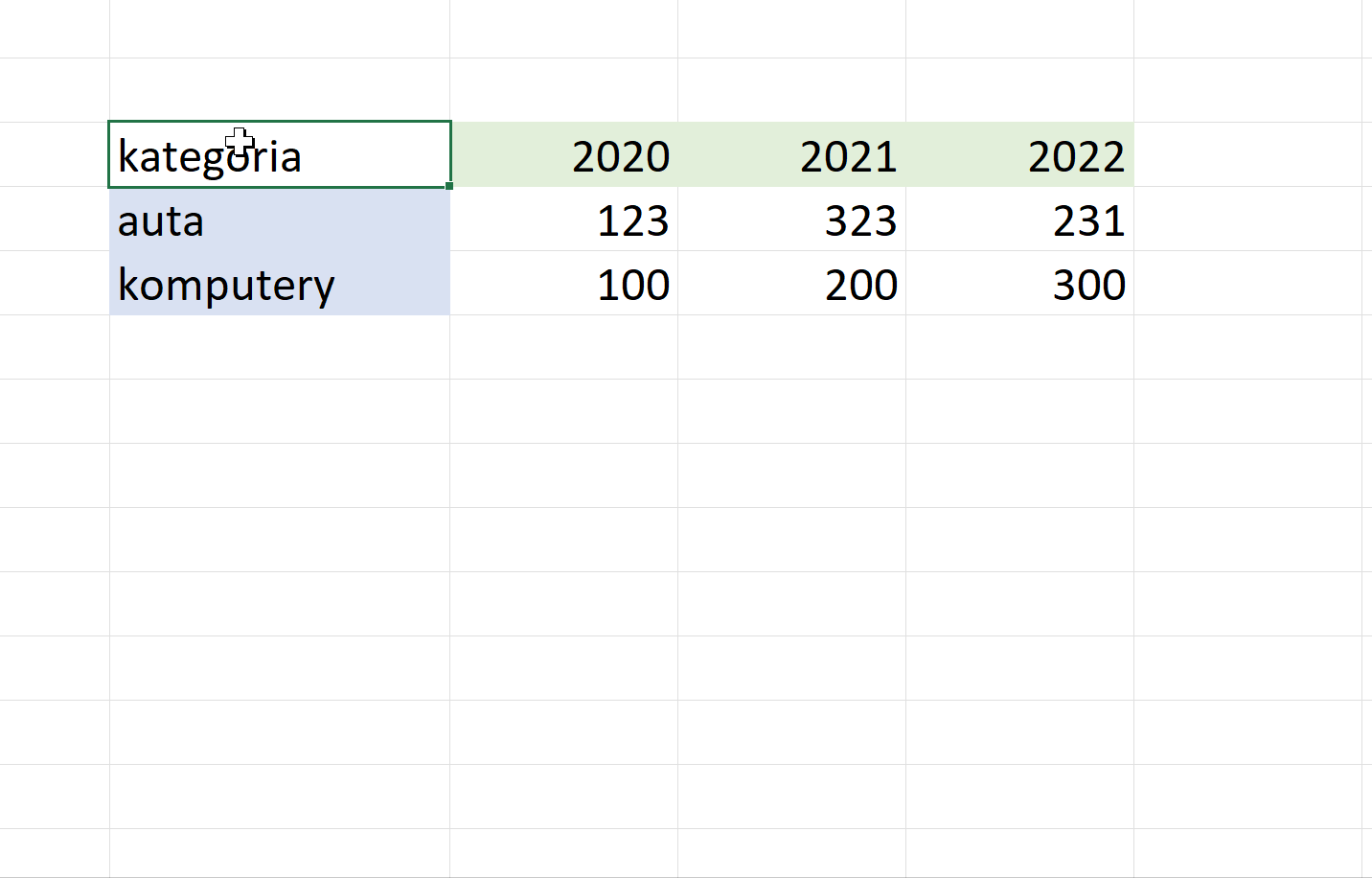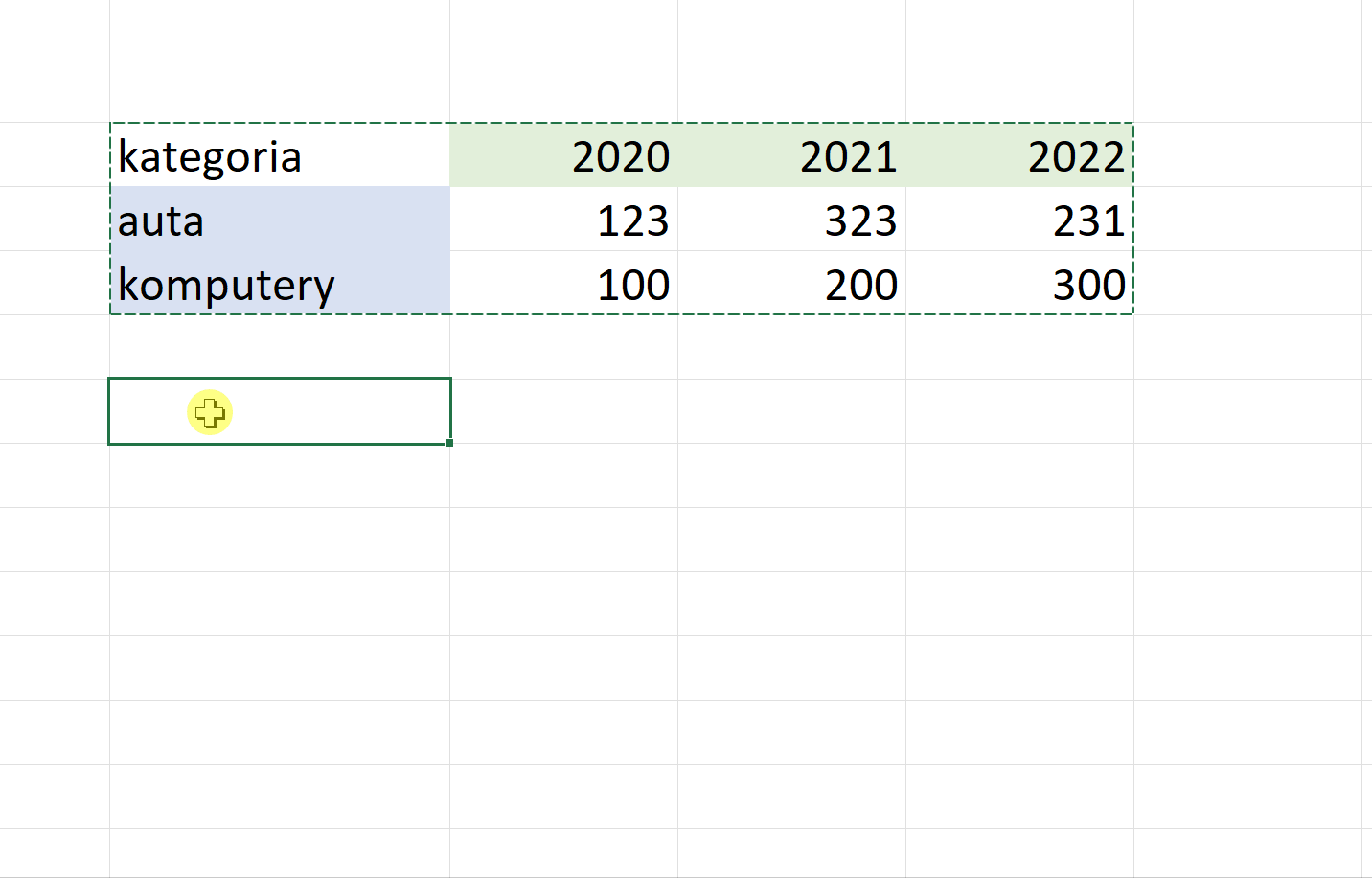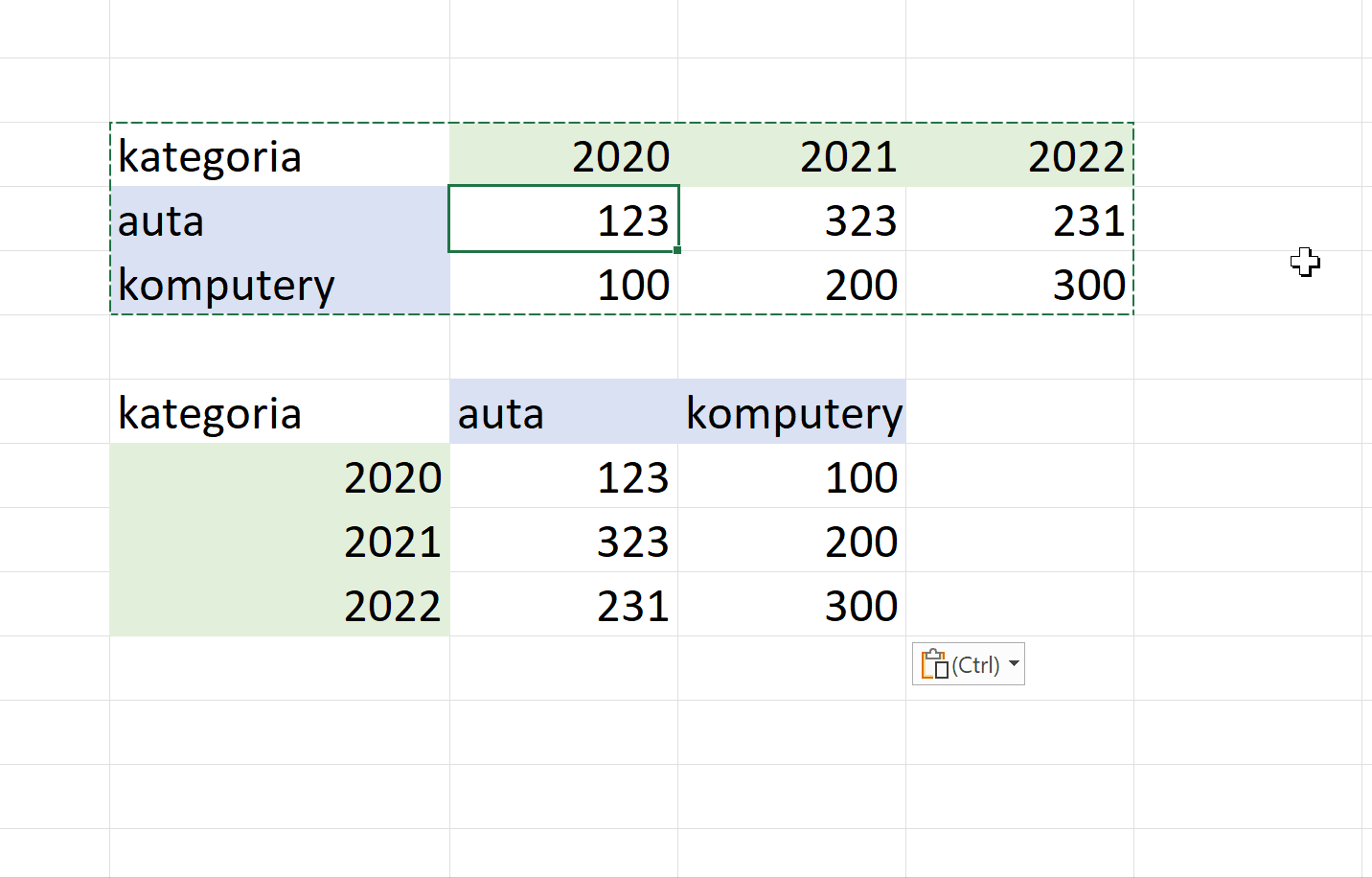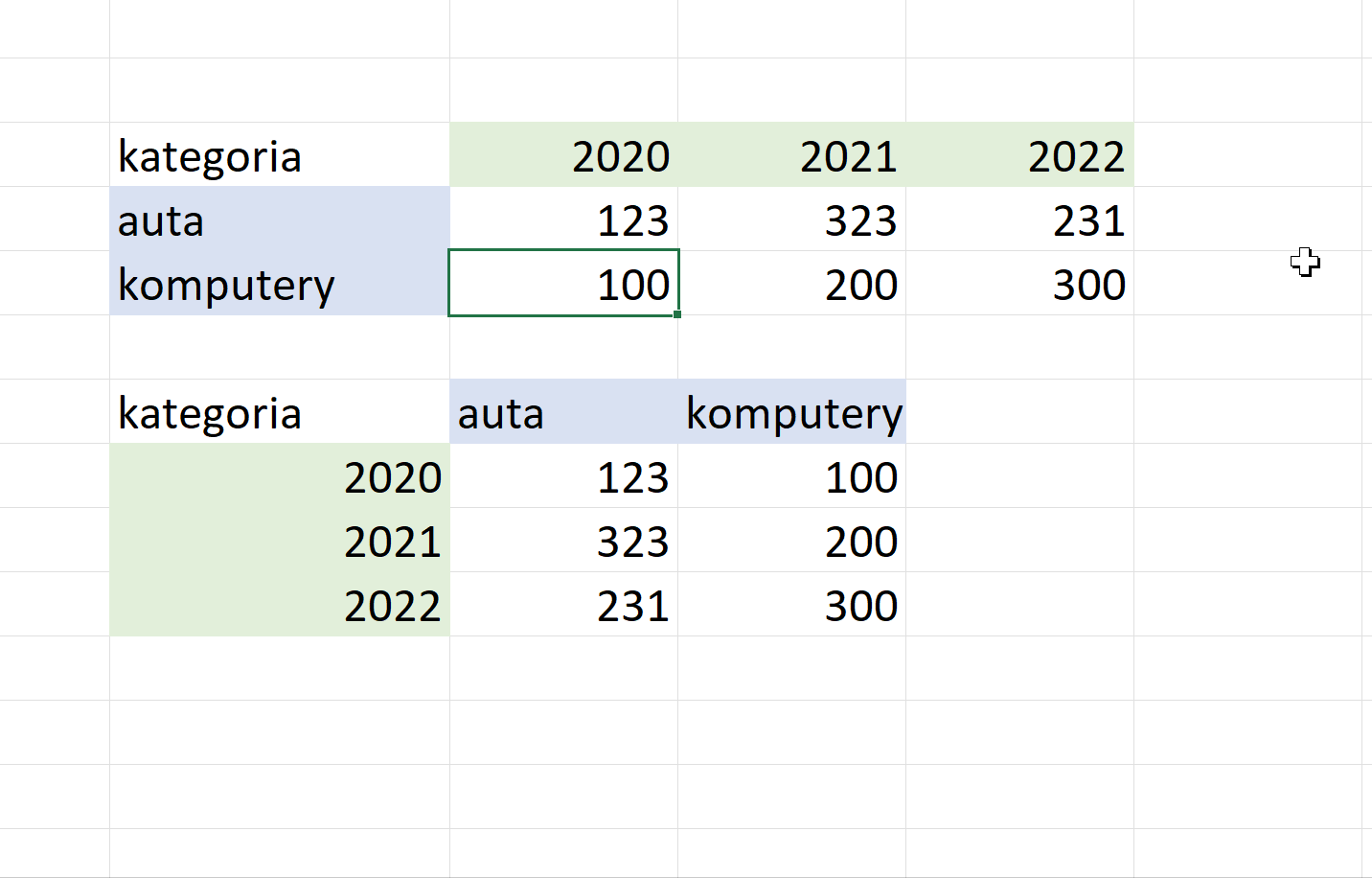
W języku R transpozycji dokonujemy funkcją t(), która zwraca przetransponowaną kopię źródłowej ramki danych (przykłady z niniejszego odcinka znajdziesz na GitHubie).

Uwaga – użytecznym trikiem jest uprzednie przekształcenie wartości wybranej kolumny na nazwy wierszy, bo po transpozycji staną się one nazwami kolumn.

Oto ilustracja działania funkcji rownames_to_column i column_to_rownames:

Ramka danych szeroka i wąska
Podczas pracy z ramką danych najbardziej naturalną reprezentacją danych jest taka, w której kolumny gromadzą zmienne jednego typu zaś wiersze to obserwacje zestawu zmiennych. Taki format ramki danych nazywamy „szerokim”, bo nowe zmienne (tutaj: wartości dla kolejnego roku) trafią do nowych kolumn.
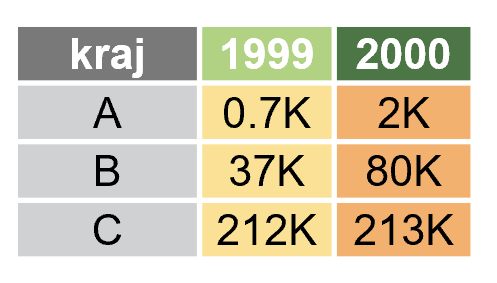
Ten sam zestaw informacji możemy jednak przedstawić w inny sposób:
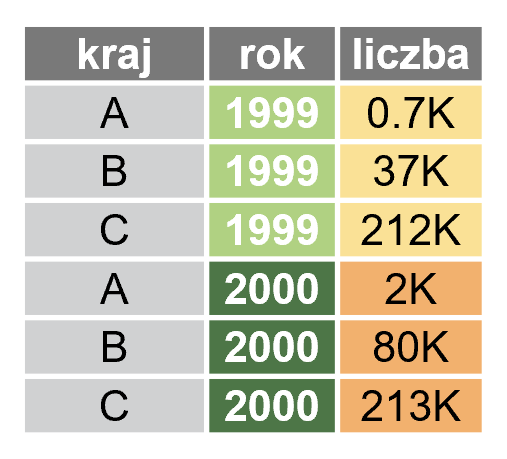
Taki format ramki danych nazywamy „wąskim” albo „długim”, nowe dane (wartości dla kolejnego roku) spowodują dodanie kolejnych wierszy. Liczba kolumn się nie zmieni.
Do czego służy format wąski? Na przykład do składowania różnorodnych zestawów danych w relacyjnej bazie danych. Gdy mamy do czynienia z systemem, w którym znajdą się tysiące unikalnych zestawów o unikalnych schematach, stworzenie tysięcy tabel bazodanowych wywoła problemy związane np. z zarządzaniem uprawnieniami. Łatwiej pracować z bazą, która te same informacje przechowa w jednej tabeli.
Jak przekształcać dane między wariantem szerokim a wąskim? Ten e-mail jest za mały, aby pomieścić instrukcję dla Excela. Serio. Zainteresowani czytelnicy odnajdą skomplikowane poradniki, my zaś spojrzymy na… jednolinijkowe komendy języka R.
Oto konwersja ramki szerokiej do wąskiej:
pivot_longer(ramkaszeroka, cols = 2:3, names_to ="rok", values_to = "liczba")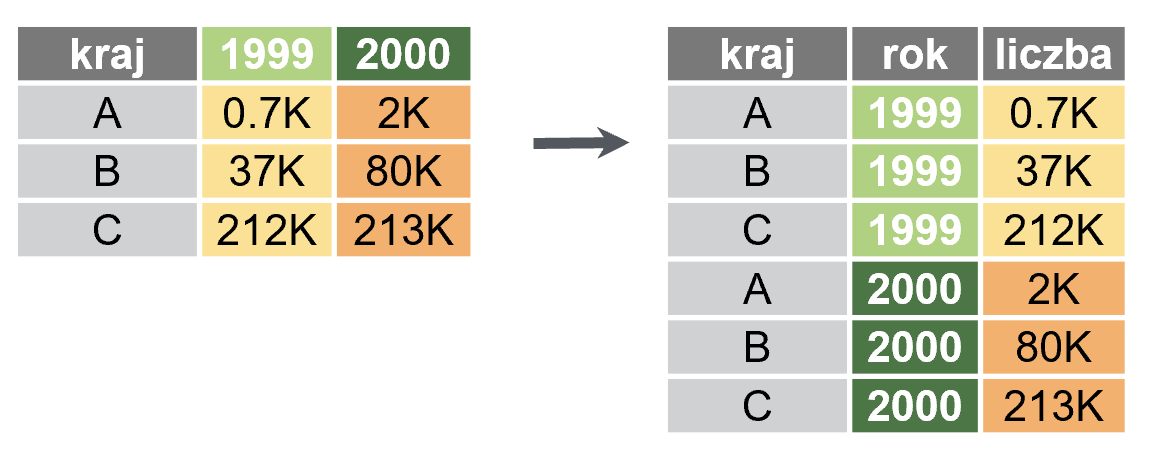
Poniżej widzimy konwersję ramki wąskiej do szerokiej
pivot_wider(ramkawaska, names_from = typ, values_from = liczba)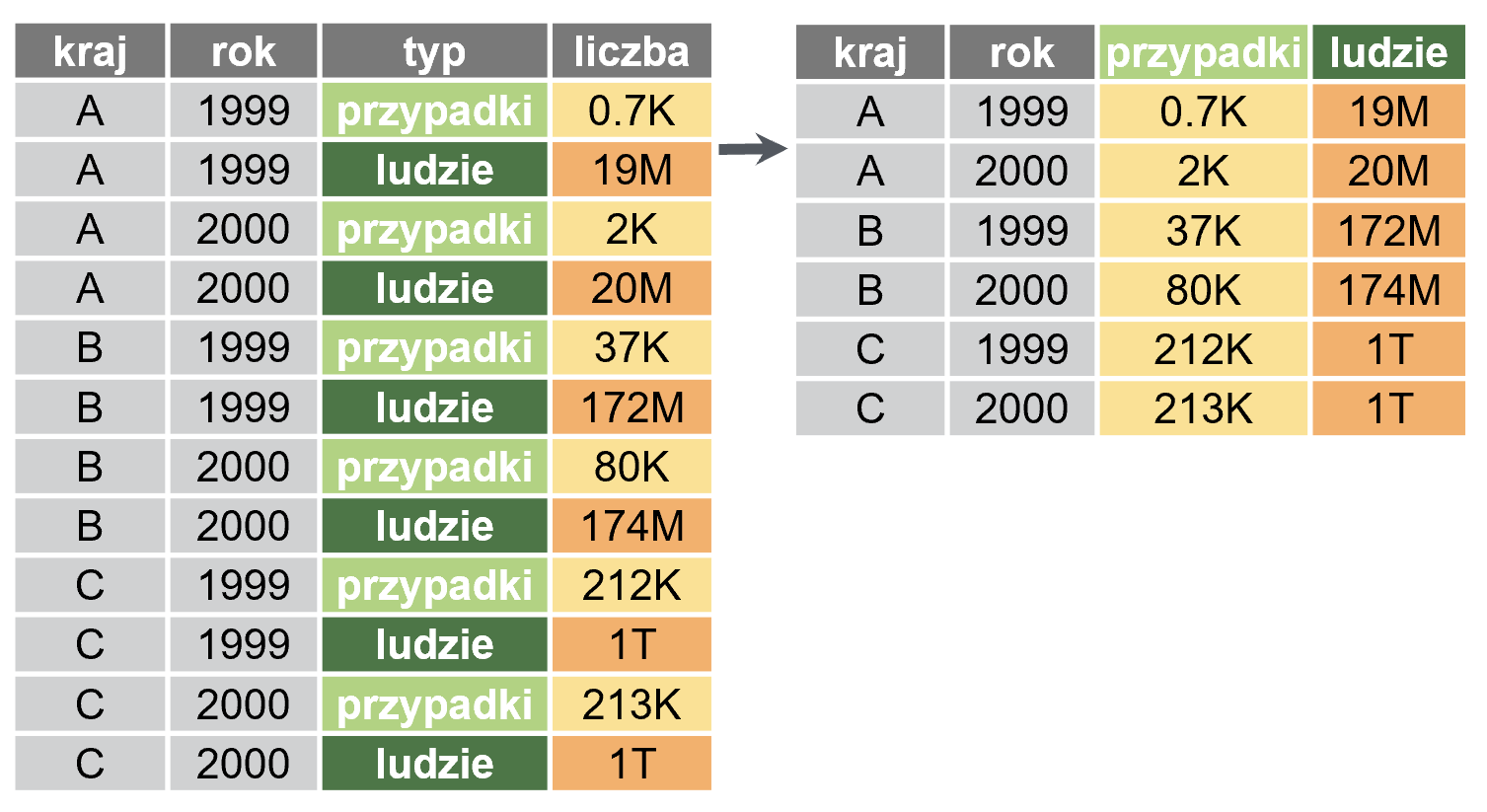
Przekształcenie ramki wąskiej do szerokiej pozwala na łatwą agregację danych z różnych źródeł. Przykład: połączenie w jednej ramce danych godzinowych informacji o temperaturze, wilgotności ściółki leśnej, zajętości miejskich parkingów oraz wartości indeksu giełdowego WIG20. Dane z każdej kategorii są łatwe do zdobycia, ale na pewno nie znajdziemy ich w jednym źródle.
Wystarczy jednak, że w każdej źródłowej ramce danych zadbamy o wspólny klucz (data i godzina) oraz nazwę kategorii („temperatura”, „wilgotność”, itd.), by potem połączyć je w pojedynczą długą ramkę danych i jednym ruchem przekształcić do ramki szerokiej. W przyszłości poznamy także inne metody łączenia danych z różnych źródeł.
Łączenie i dzielenie komórek
Czasem surowe dane źródłowe zawierają wartości, które musimy połączyć lub podzielić, by móc je sensownie wykorzystać. Posłużą nam do tego komendy unite oraz separate – oto przykłady użycia:
unite(ramka, stulecie, rok, col = "rok", sep = "")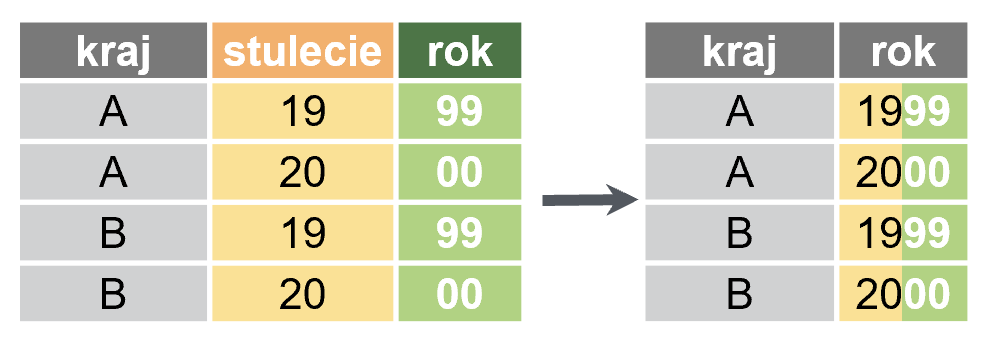
separate(ramka, wskaźnik, sep = "/", into = c("przypadki", "ludzie"))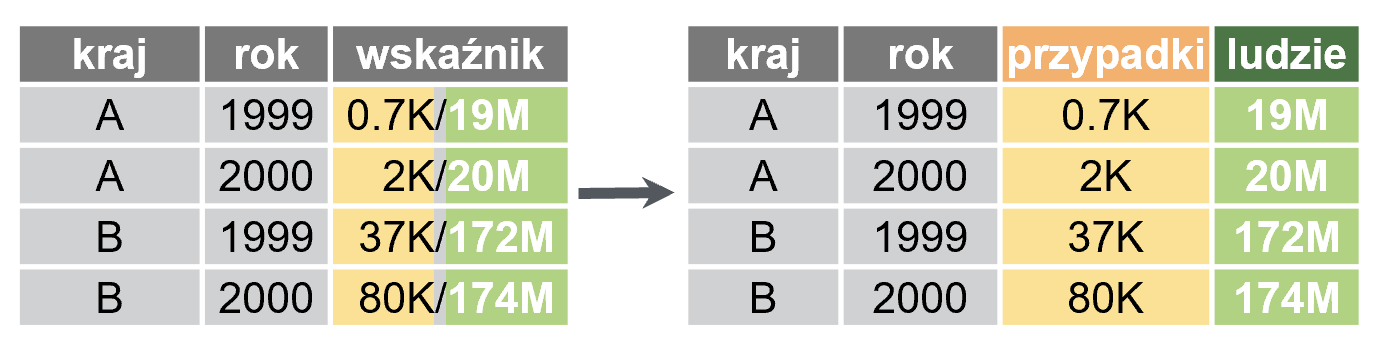
Zagnieżdżanie ramek danych
To jest sztuczka zaawansowana, więc trafia tu tylko jako ciekawostka – w języku R ramki danych mogą zawierać inne ramki danych (oraz wektory i listy, o których jeszcze nie mówiliśmy).
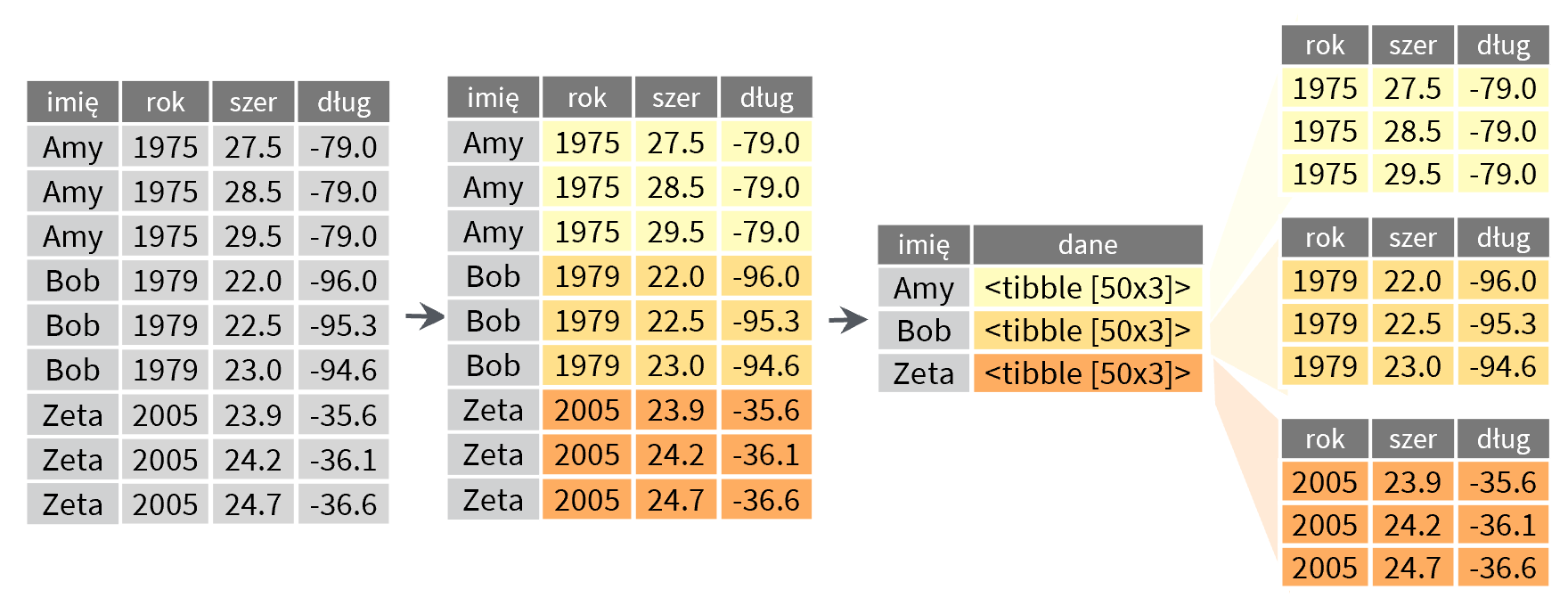
Do czego może nam się przydać taka konstrukcja? Prostych przykładów brak, poprzestaniemy więc jedynie na konkluzji, że wirtuozi języka R dostają do dyspozycji narzędzie, które nie ma odpowiednika w arkuszu kalkulacyjnym Excel.
Źródło obrazków
Obrazki w niniejszym odcinku pochodzą z cheat sheeta tidyr autorstwa firmy Posit Software PBC, wydawcy aplikacji RStudio. Cheat sheet dostępny jest na licencji Creative Commons BY SA 4.0 i warto do niego zajrzeć, by poznać pozostałe komendy do modyfikacji i obróbki danych.

O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.
