
W dziewiątym odcinku Poradnika dotarliśmy do obliczeń agregujących. Wielu użytkowników Excela zostało tu solidnie sponiewieranych, bo choć same operacje są intuicyjne, to ich przełożenie na dwuwymiarową siatkę komórek – niekoniecznie.
Po raz kolejny przekonujemy się, że oddzielenie danych od operacji na danych bardzo ułatwia śledzenie przebiegu obliczeń. Ani przez chwilę nie zaprzątamy sobie głowy rozmieszczeniem kolejnych etapów obliczeń we wspólnym układzie współrzędnych, jak muszą to robić użytkownicy Excela.
Agregacje
Jeśli chcemy obliczyć zagregowane cechy kolumny z ramki danych, możemy odwołać się bezpośrednio do tej kolumny. Przykłady – średnia, mediana i suma:
mean(otomoto$price)
median(otomoto$price)
sum(otomoto$price)Często będziemy chcieli użyć tak wyliczonej wartości do utworzenia nowej kolumny. Dodajmy do ramki danych otomoto dwie nowe kolumny, z których druga będzie informować, jaki procent mediany wartości wszystkich aut (41900 zł) stanowi konkretna oferta:
otomoto %>%
mutate(mediana = median(price), procent_mediany = 100*price/mediana) %>%
select(mark, model, year, mileage, price, mediana, procent_mediany)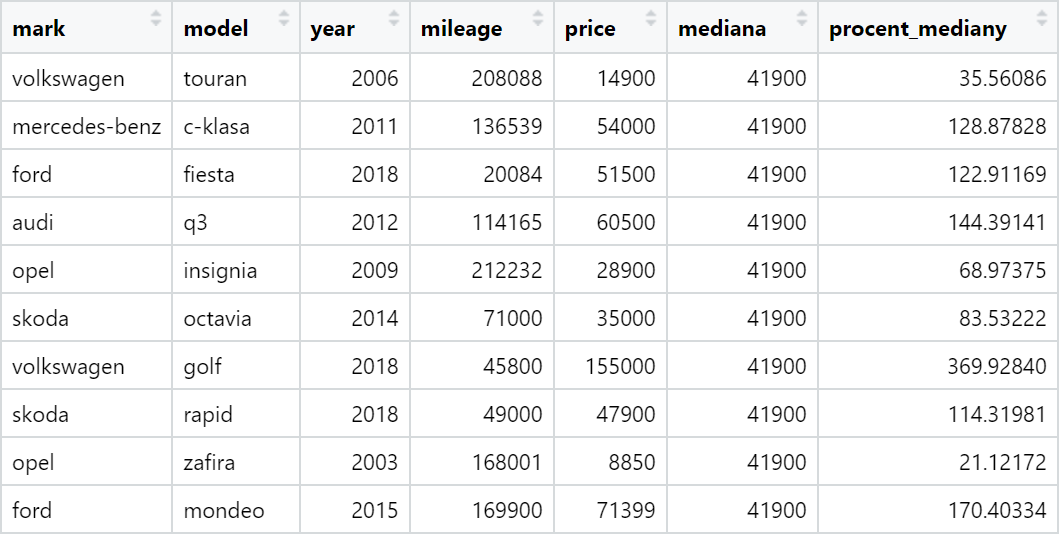
Funkcji agregujących możemy użyć do obliczenia minimum, maksimum, kwintyli, decyli i percentyli, odchyleń i wariancji oraz wielu innych wartości używanych w statystyce czy finansach.
Grupowanie
Funkcja grupowania rozbija ramkę danych na segmenty. Od tej chwili funkcje agregujące będą operować w obrębie każdego segmentu z osobna. Ramka danych nie musi być posortowana względem kryterium podziału.
Tym razem do ramki danych otomoto dodamy nową kolumnę, która będzie informować o tym, jaki procent mediany danej marki wynosi cena konkretnej oferty:
otomoto %>%
group_by(mark) %>%
mutate(mediana_marki = median(price), procent_mediany_marki = 100*price/mediana_marki ) %>%
ungroup() %>%
select(mark, model, year, mileage, price, mediana_marki, procent_mediany_marki)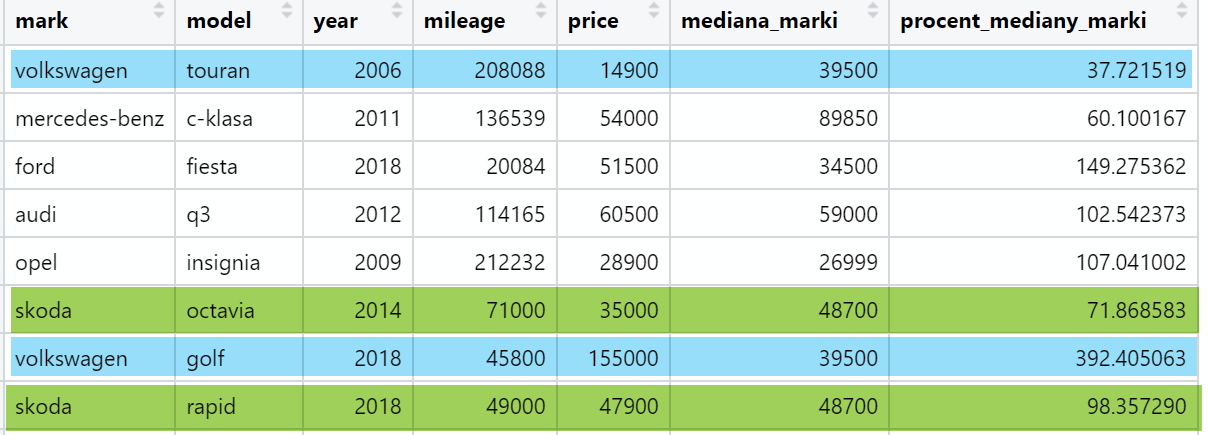
Co stanie się, jeśli zapomnimy o rozgrupowaniu?
otomoto %>%
group_by(mark) %>%
mutate(mediana_marki = median(price), procent_mediany_marki = 100*price/mediana_marki ) %>%
select(mark, model, year, mileage, price, mediana_marki, procent_mediany_marki)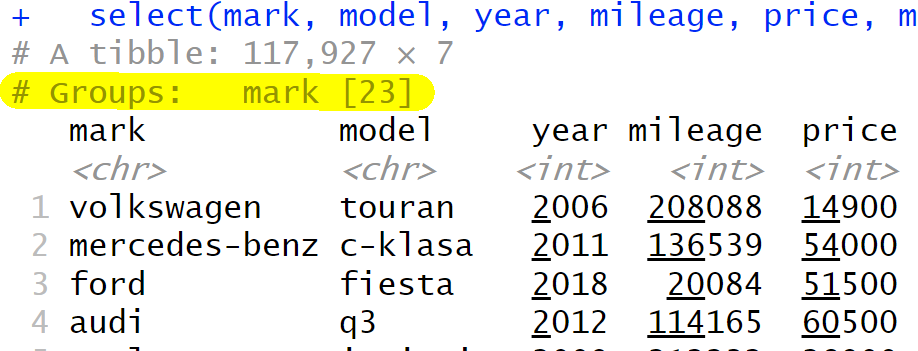
Zwróćmy uwagę na wyróżnienie – ramka danych pamięta grupowania. Dalsze operacje na niej będą nadal operowały na każdym segmencie z osobna. Może to prowadzić do trudnych do zauważenia błędów obliczeniowych. Każde grupowanie powinno występować wraz z pobliskim rozgrupowaniem.
Aby uniknąć takich problemów, kryterium grupowania może być wstawione bezpośrednio do wyrażenia agregującego. Takie grupowanie działa tylko w obrębie jednego wyrażenia i automatycznie się rozgrupowuje. Przykład:
otomoto %>%
mutate(procent_mediany_marki = 100*price/ median(price), .by = mark)Grupowanie wierszy może bazować nie tylko na wartości przechowywanej w kolumnie ramki danych, ale na dowolnym wyrażeniu – jego wartość zostanie w locie obliczona dla każdego wiersza. Przykład – grupowanie wierszy wg numeru tygodnia daty obecnej w ramce danych
ramka_danych %>% group_by(lubridate::isoweek(kolumna_z_datą))Podsumowania
Często w analizie danych nie interesują nas pojedyncze pomiary, lecz statystyki grupowe. Poleceniem summarize zredukujemy każdą grupę do pojedynczego wiersza z podsumowaniem.
otomoto %>%
group_by(mark) %>%
summarize (
liczba_modeli = n_distinct(model),
liczba_ofert = n(),
srednia_cena = mean(price),
odchylenie_standardowe_ceny = sd(price)
) %>%
ungroup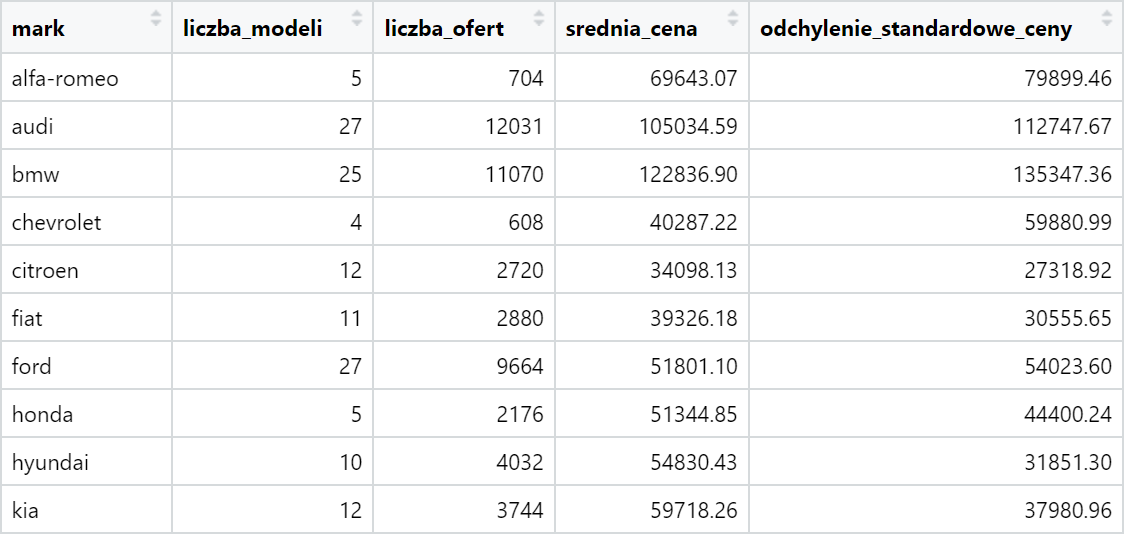
Jak widzimy, po wykonaniu summarize znikają wszystkie kolumny, które nie były bazą grupowania. Również tutaj możemy grupować nie tylko po kolumnach (w tym wielu naraz), ale także po wyrażeniach definiowanych w locie. Przykład: podsumujemy ofertę samochodów z podziałem na marki, modele i przebieg (poniżej / powyżej 100 tys. km) i przekonamy się, że auta z mniejszym przebiegiem są zazwyczaj warte więcej.
otomoto %>%
group_by(mark, model, niski_przebieg = mileage < 100000) %>%
summarize (
liczba_ofert = n(),
srednia_cena = mean(price),
odchylenie_standardowe_ceny = sd(price)
) %>%
ungroup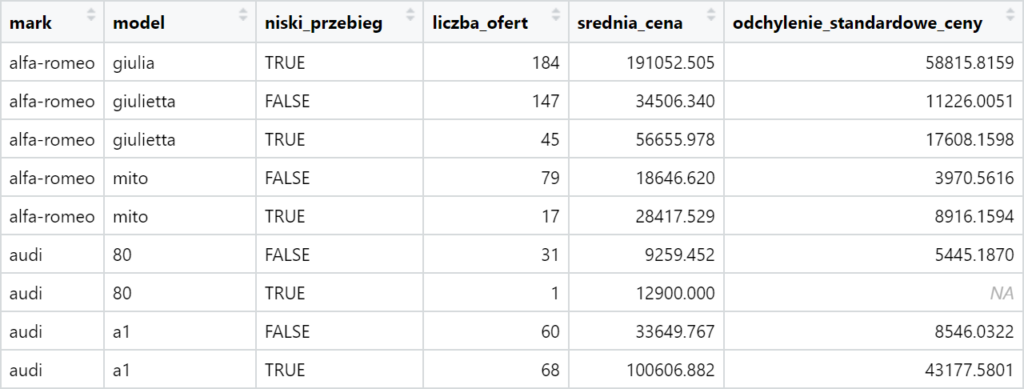
Wypróbuj wszystkie polecenia z dzisiejszego odcinka w swoim RStudio! Plik z gotowymi do uruchomienia komendami znajdziesz na GitHubie.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.
