
Jeśli zdarza ci się klikać w nieco bardziej szemranych rejonach internetów, być może znasz krwiście czerwony ekran przeglądarki ostrzegający przed niebezpieczeństwem na otwieranej stronie. Ta funkcja uratowała przed problemami niezliczone rzesze użytkowników, ale rodzi wątpliwości innej natury – czy Google śledzi każde nasze kliknięcie?
Nie śledzi! Dziś dowiemy się, w jaki sposób działa funkcja Safe Browsing, używana w przeglądarkach Chrome, Firefox, Safari i innych – zarówno na desktopie jak i mobilkach. Podczas lektury przydatna będzie wiedza z poprzedniego artykułu, w którym poznaliśmy funkcje skrótu.
O jakich zagrożeniach mowa?
Aby było jasne – samo otworzenie problematycznej strony w przeglądarce internetowej niesie małe ryzyko. Problemy sprowadzimy na siebie dopiero wypełniając formularze z danymi logowania, przekazując dane karty kredytowej lub pobierając zainfekowane pliki.
Przestępcy starają się wyłudzić dane logowania np. do bankowości elektronicznej (aby ukraść pieniądze) albo do sieci społecznościowych (aby wyłudzić pieniądze od twoich bliskich). Zazwyczaj rejestrują w tym celu domeny podobne do prawdziwych – np. facedook.com albo rnbank.pl
Inną metodą ataku jest namówienie użytkownika do pobrania i otworzenia zainfekowanego pliku – np. dokumentu ze złośliwymi makrami albo (rzekomego) instalatora poszukiwanej aplikacji. Tu rezultaty mogą być różnorakie:
- komputer ofiary stanie się częścią botnetu atakującego inne witryny
- złośliwy program przyczai się w komputerze, aby wykradać dane logowania
- złośliwy program zaszyfruje wszystkie dane na komputerze i zażąda okupu za ich odszyfrowanie.
W jaki sposób przeglądarki nas ostrzegają?
Niebezpieczne serwery są identyfikowane w różny sposób – część z nich odnajdą roboty indeksujące zawartość witryn internetowych, część zgłoszą niedoszłe ofiary, jeszcze inne zostają odkryte przez badaczy analizujących próbki złośliwego oprogramowania. Listy niebezpiecznych adresów są tworzone i utrzymywane przez wiele instytucji, takich jak Google, Microsoft, operatorzy telekomunikacyjni czy krajowe zespoły reagowania (CERT).
Przeskoczmy na sam koniec procesu. Gdy spróbujemy otworzyć niebezpieczną stronę w popularnych przeglądarkach, zobaczymy:
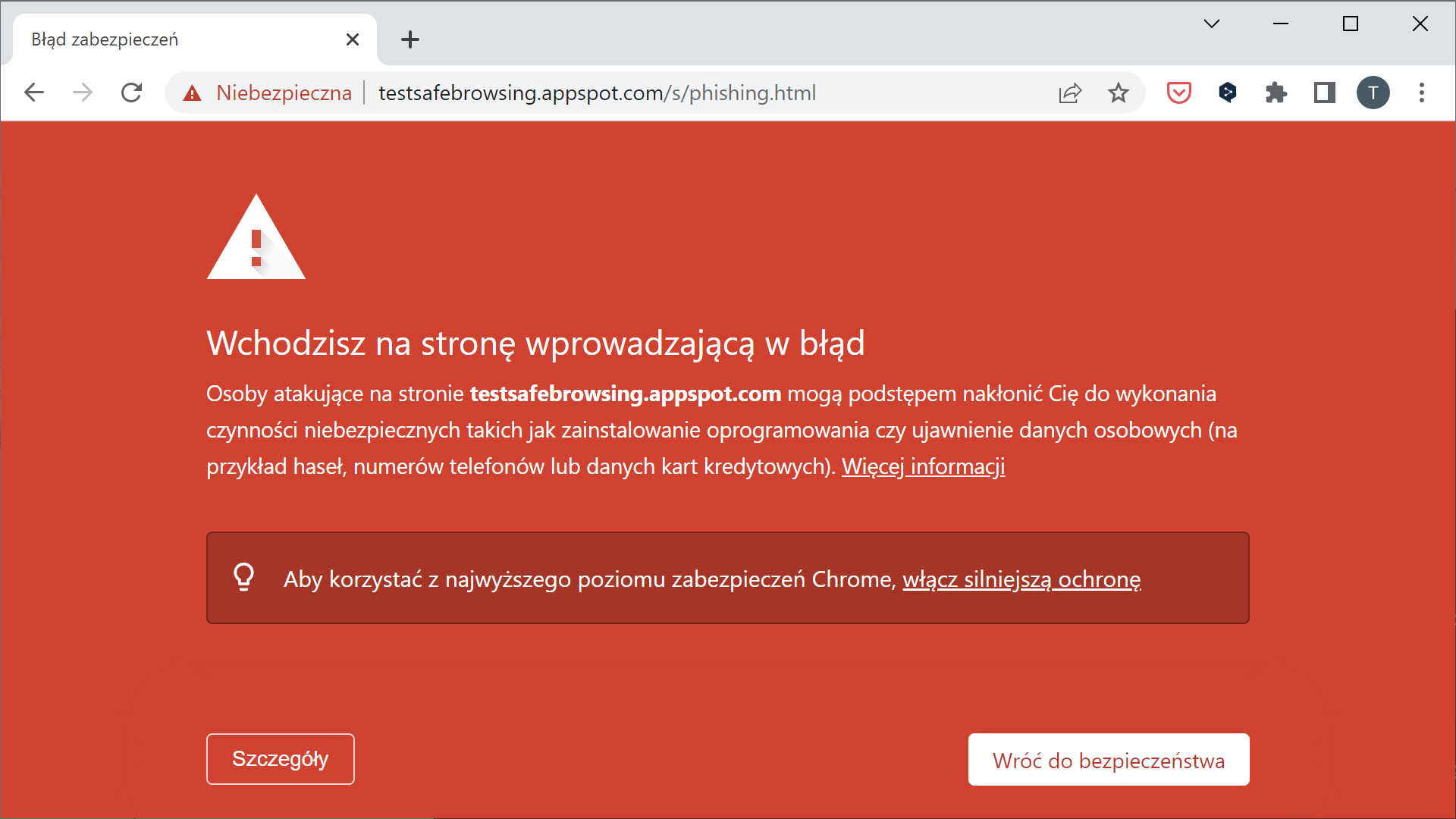
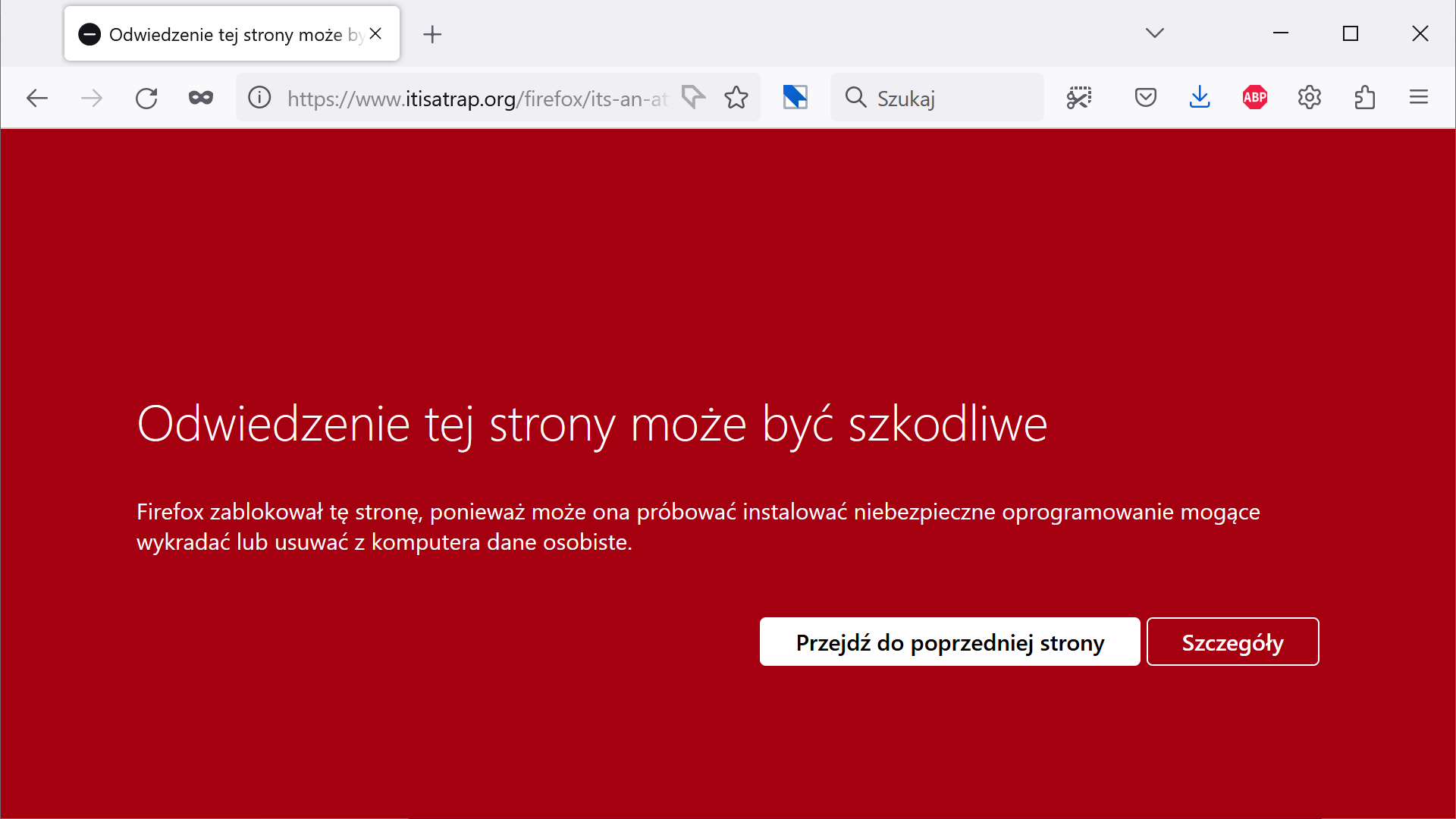

Powyższe screenshoty zostały przygotowane przy użyciu stron testowych, każda przeglądarka ma swój własny zestaw:
- Chrome i Firefox: https://testsafebrowsing.appspot.com/
- Firefox: https://wiki.mozilla.org/Security/Safe_Browsing#QA
- Edge: https://demo.smartscreen.msft.net/
Jak to w ogóle działa?
Gdy przed próbą wejścia na złośliwą stronę włączymy analizę ruchu sieciowego, zobaczymy… brak ruchu sieciowego. Przeglądarka nie wygeneruje żądań do strony zidentyfikowanej jako niebezpieczna, więc kontrola musi dokonywać się na bazie już zgromadzonych informacji.
Nie jest to takie całkiem proste zadanie, bo liczba zarejestrowanych domen to – w chwili pisania niniejszego tekstu – ponad 650 milionów. Dziennie rejestrowanych jest kilkaset tysięcy nowych domen, podobna liczba wygasa. A skoro nowa domena może być użyta do ataków już chwilę po rejestracji, jasne staje się, że dane do mechanizmu kontrolnego muszą być aktualizowane na bieżąco.
Chcielibyśmy, aby mechanizmy bezpieczeństwa zużywały możliwie mało pamięci i mocy obliczeniowej – oraz gwarantowały użytkownikowi poufność jego historii przeglądania. Jak pogodzić to z milionami złośliwych lokalizacji? W rozwiązaniu wykorzystane są skróty kryptograficzne, o których napisałem więcej w poprzednim artykule.
Sekwencja działań podnoszących bezpieczeństwo surfowania po WWW wygląda następująco:
1. Google gromadzi listę niebezpiecznych lokalizacji
Lista niebezpiecznych lokalizacji znana pod marką Safe Browsing zawiera obecnie ponad 30 milionów wpisów. Wiemy, że przestępcy masowo rejestrują i porzucają domeny – nie jest to więc lista statyczna. Dział bezpieczeństwa Google działa w trybie ciągłym, dużą część pracy wykonują automaty, nowe pozycje są dodawane bez przerwy.
Do użytkownika nie trafiają jednak nazwy domenowe ani ścieżki do niebezpiecznych podstron albo plików – Safe Browsing udostępnia jedynie ich czterobajtowe skróty. Dlaczego tak krótkie? O tym za chwilę.
2. Przeglądarka pobiera listę skrótów
Skoro lista Safe Browsing zmienia się 24 godziny na dobę, przeglądarka musi regularnie aktualizować lokalną kopię. Tu poznajemy pierwszą zaletę małych skrótów – setki tysięcy nowych wpisów to raptem megabajt lub dwa do pobrania. Zazwyczaj będzie ich dużo mniej, bo przeglądarki pobierają aktualizacje listy co pół godziny.
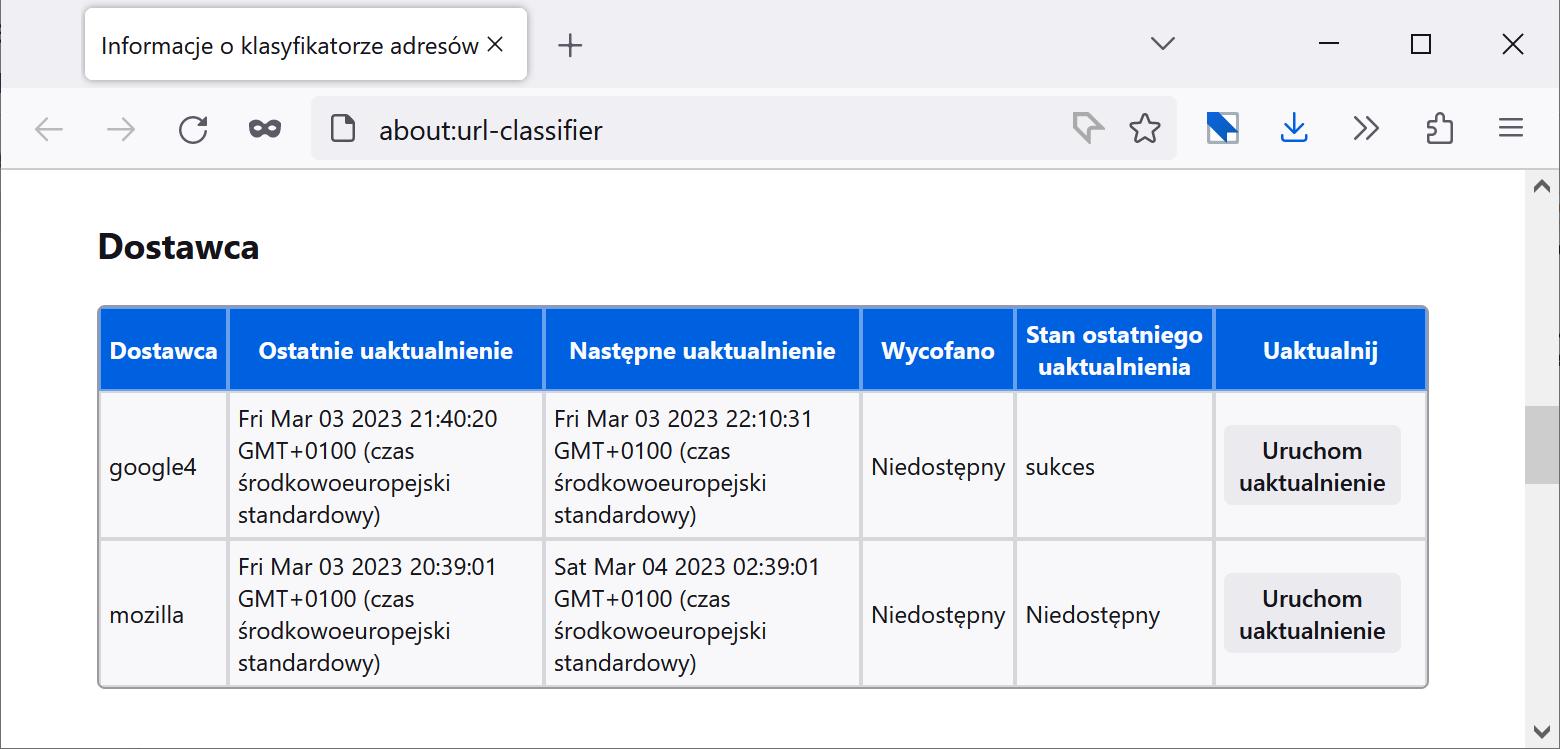
Możemy przekonać się o tym otwierając w Chrome stronę chrome://safe-browsing/#tab-db-manager albo w Firefoksie stronę about:url-classifier (uwaga – jeśli tego typu linki nie dają się kliknąć, ręcznie przenieś je do paska adresu). Zobaczymy datę ostatniej i kolejnej aktualizacji, Firefox pozwoli nam dodatkowo na wymuszone pobranie świeżych danych.
3. Użytkownik klika link lub otwiera stronę
Gdy użytkownik wykonuje akcję, w wyniku której mają zostać pobrane zasoby wskazywane przez danego URL-a, przeglądarka najpierw oblicza skrót SHA-256 tego adresu. Następnie sprawdza, czy pierwsze cztery bajty tego skrótu znajdują się na liście skrótów niebezpiecznych lokalizacji Safe Browsing.
Przykład: pierwsze cztery bajty skrótu SHA-256 z napisu facedook.com to (w zapisie szesnastkowym) b8fd296d, można to sprawdzić tutaj.
Aby zwiększyć czułość wykrywania złośliwych adresów, przeglądarka wygeneruje dodatkowo do kilkudziesięciu wariantów pokrewnych – np. bez subdomen, bez parametrów w URL, ze skróconą ścieżką do pliku. Również dla takich wariantów zostaną wyliczone skróty, których pierwsze bajty będą porównane z listą.
Przykład: przy próbie otworzenia strony http://a.b.c/1/2.html?param=1, sprawdzone zostaną następujące ciągi znaków
- a.b.c/1/2.html?param=1
- a.b.c/1/2.html
- a.b.c/
- a.b.c/1/
- b.c/1/2.html?param=1
- b.c/1/2.html
- b.c/
- b.c/1/
Jak duże jest ryzyko, że niewinny URL wygeneruje skrót z czarnej listy? Wiemy, że Safe Browsing ma około 30 milionów pozycji, tymczasem liczba kombinacji czterech bajtów to 232 czyli około 4.29 miliarda. Prawdopodobieństwo nie przekracza więc jednego procenta. To z jednej strony niewiele, ale – przy tysiącach sprawdzeń dziennie – nie tak znowu mało.
Odpowiedzmy więc na pytanie, co stanie się dalej.
4a. Nie odnaleźliśmy skrótu na liście Safe Browsing
Sytuacja jest prosta – wiemy na pewno, że otwierany link nie stanowi znanego zagrożenia.
4b. Skrót występuje na liście Safe Browsing
Tu robi się ciekawie – albo otwierany URL występuje na liście zagrożeń, albo jest bezpieczny lecz wystąpiła kolizja. Aby się tego dowiedzieć, musimy zapytać serwer o pełne skróty SHA-256.
Serwer Safe Browsing otrzymuje wspomniane cztery bajty i odsyła wszystkie znane skróty niebezpiecznych URL-i zaczynające się od tej sekwencji. Przeglądarka odbiera ową listę i sprawdza, czy występuje na niej pełny skrót SHA-256 otwieranego URL-a. Jeśli tak, zagrożenie jest realne, przeglądarka zamiast pobrania docelowej strony wyświetla czerwony ekran alertu. Jeśli nie, miała miejsce kolizja skrótów, przeglądarka kontynuuje ładowanie docelowej strony.
Może zdarzyć się, że potencjalnie niebezpieczny prefiks trzymany w lokalnej bazie należy do URL-a, który wyleciał już z listy Safe Browsing. W takiej sytuacji serwer zwróci w odpowiedzi pustą listę a przeglądarka może przystąpić do pobierania zawartości strony.
Szczegóły techniczne
Na stronie developers.google.com/safe-browsing/v4 możemy znaleźć szczegółowy opis usługi wraz ze wszystkimi niezbędnymi detalami. Dowiemy się na przykład, że baza Safe Browsing może zawierać prefiksy skrótów dłuższe, niż czterobajtowe – co zapobiega zbyt dużej liczbie zapytań w sytuacji, gdy wystąpi kolizja niebezpiecznego URL-a i bezpiecznego adresu popularnej witryny internetowej.
Klient usługi odpytujący serwery Safe Browsing jest zobowiązany do przechowywania odpowiedzi w pamięci podręcznej – zarówno trafienia (klient otrzymał pełne skróty niebezpiecznych URL-i) jak i pudła (klient dowiedział się, że dany prefiks nie stanowi zagrożenia).
Sprawdzamy to wszystko ręcznie
Dowiedzieliśmy się, jak działają mechanizmy wbudowane w przeglądarkę – teraz spróbujemy sprawdzić Safe Browsing samodzielnie, na kilka różnych sposobów.
Metoda 1 – sprawdzaczka adresów wbudowana w Firefoksa
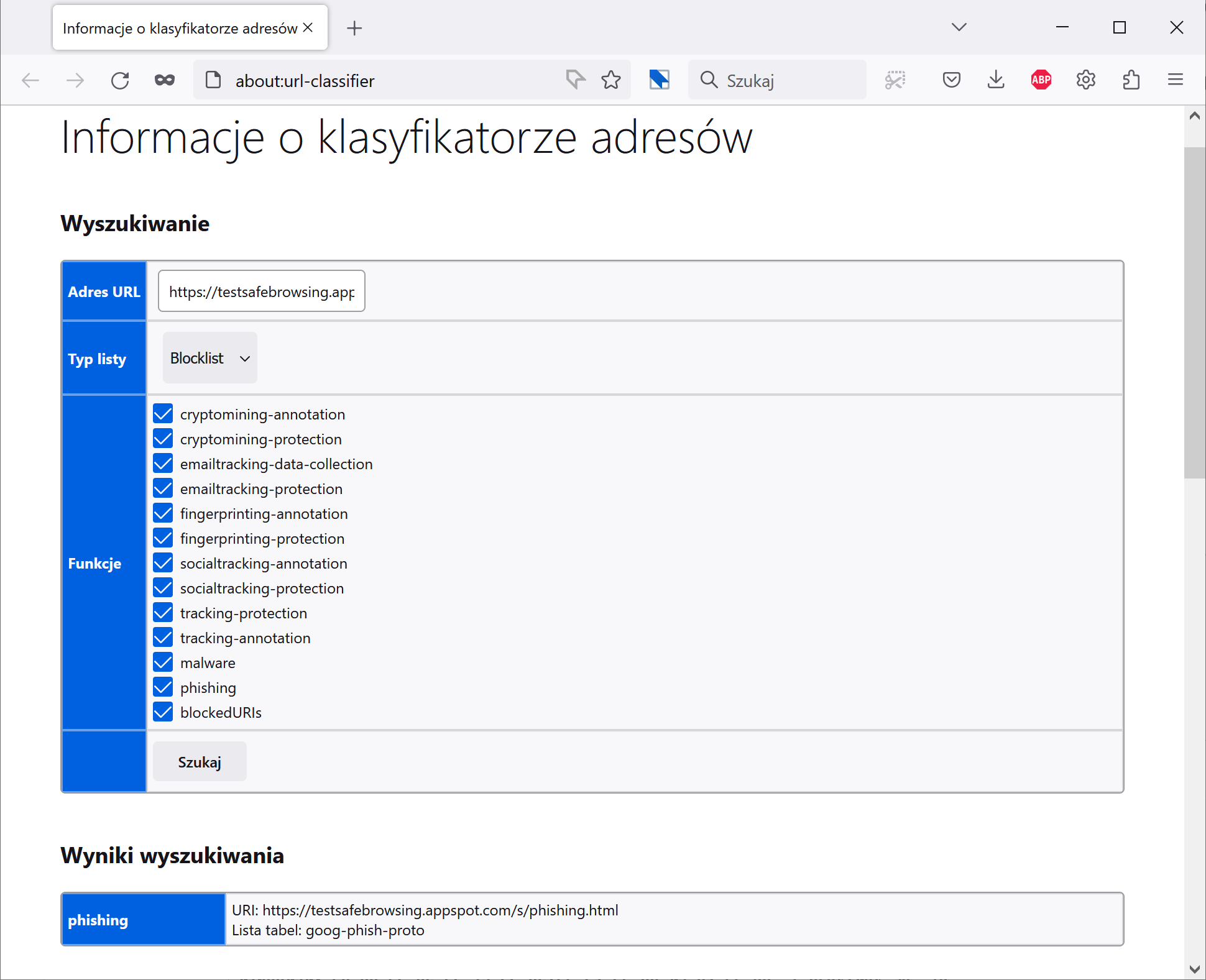
Gdy w przeglądarce Firefox otworzymy stronę about:url-classifier, zobaczymy wbudowaną sprawdzaczkę obecności wskazanego URL-a na listach zagrożeń (Firefox korzysta z Safe Browsing oraz listy utrzymywanej przez fundację Mozilla).
Metoda 2 – narzędzia wbudowane w Chrome
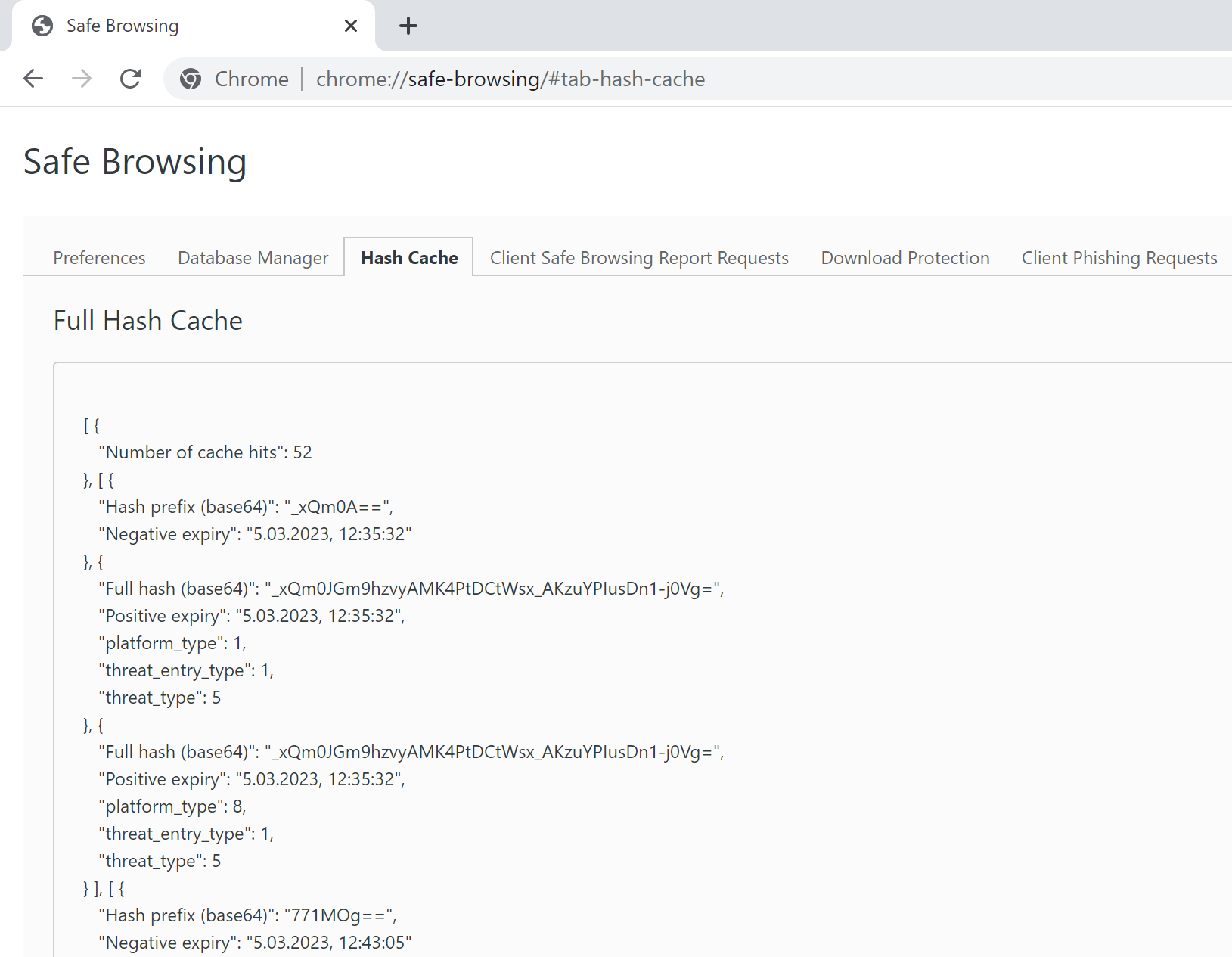
Chrome nie ma narzędzia do testowania URL-i, ale można łatwo obejrzeć bieżący cache chrome://safe-browsing/#tab-db-manager – zawierający listę trafień (pobrane skróty niebezpiecznych adresów) i chybień (wykryte kolizje).
Metoda 3 – Ręczne przeszukanie bazy skrótów
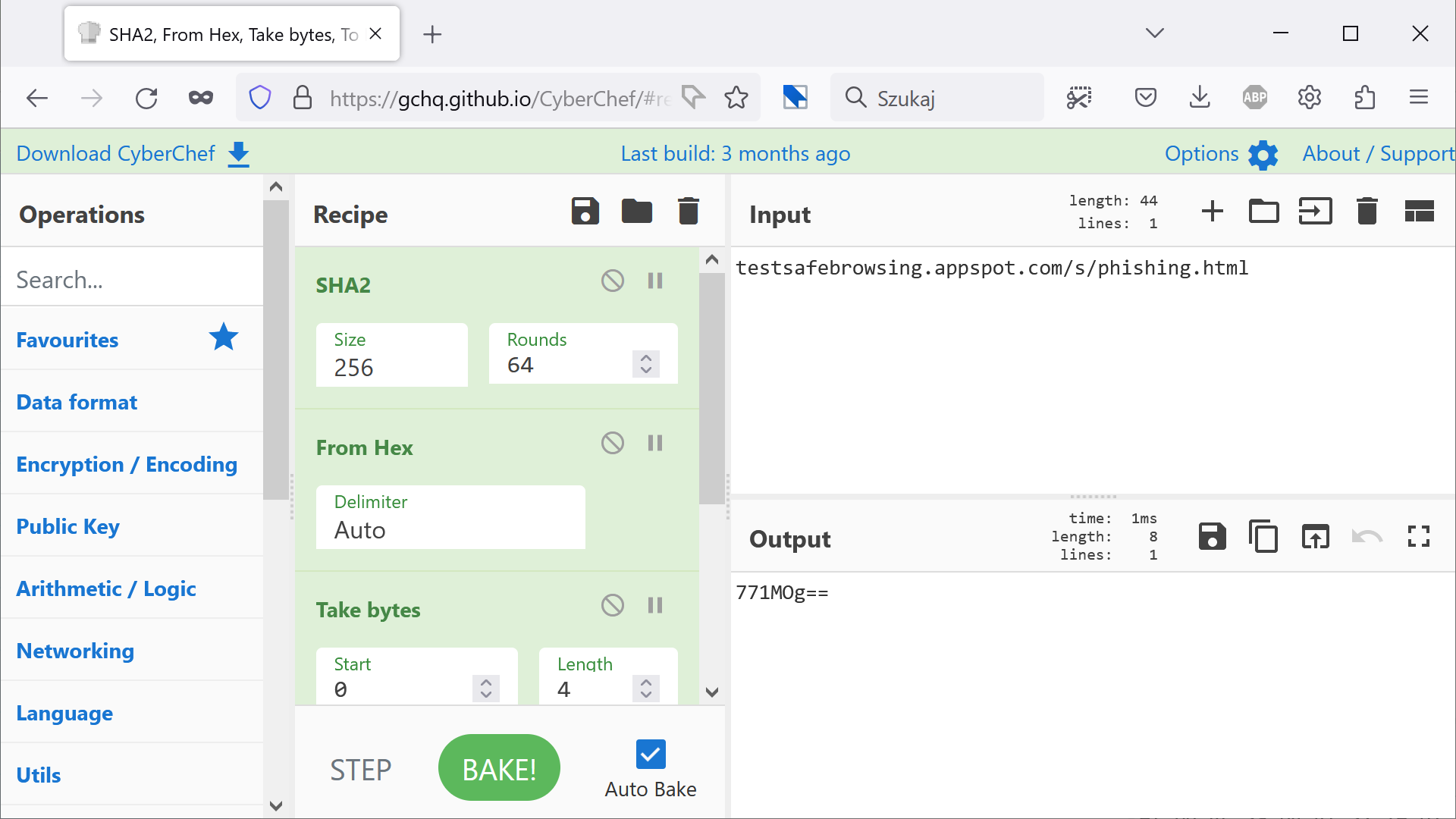
Zajrzyjmy do katalogu c:\Users\%USERNAME%\AppData\Local\Google\Chrome\User Data\Safe Browsing\ – można tam znaleźć kilkanaście plików z danymi. Wyszukajmy teraz ciąg (zapis szesnastkowy) efbd4c3a czyli czterech pierwszych bajtów skrótu SHA-256 wyliczonego z tekstu testsafebrowsing.appspot.com/s/phishing.html.
Okazuje się, że taką sekwencję można odnaleźć w pliku UrlSoceng.store. Oczywiście metoda jest niedoskonała, bo możemy przypadkowo znaleźć poszukiwane bajty na granicy dwóch różnych skrótów, ale tu akurat wszystko gra. Na poniższej ilustracji widzimy, że skróty są posortowane a my oglądamy fragment ze skrótami zaczynającymi się od “efbd”.

Metoda 4 – sięgamy do update API
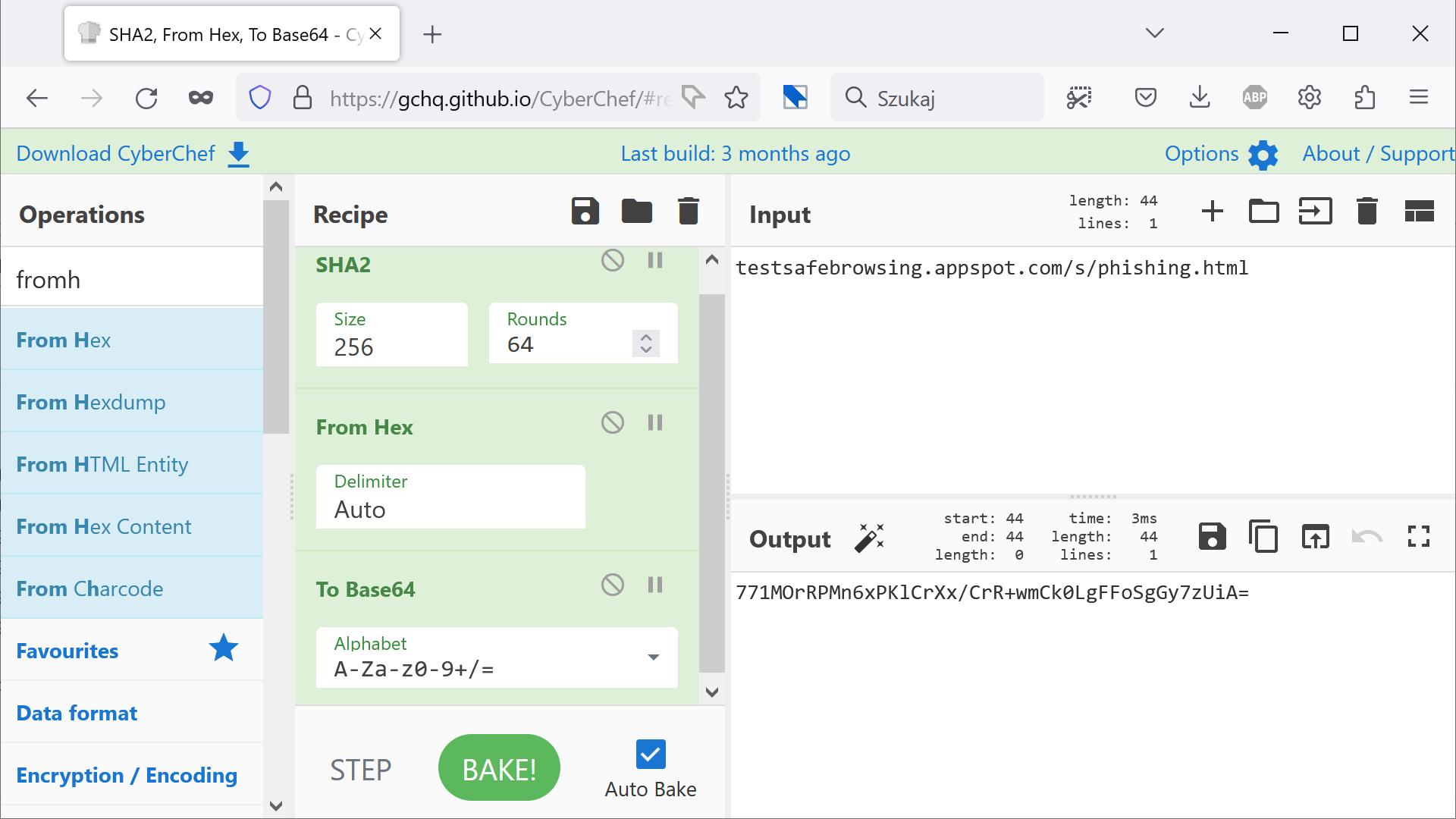
Tu odpytujemy bezpośrednio API Safe Browsing (potrzebny będzie do tego darmowy klucz API), pytając o lokację testsafebrowsing.appspot.com/s/phishing.html. Najpierw zapiszemy cztery pierwsze bajty skrótu w formacie Base64 (osobny artykuł na ten temat znajdziesz tutaj). Jest to wartość 771MOg==.
Wysyłamy żądanie do serwerów Safe Browsing, przekazując zakodowane cztery bajty skrótu. W odpowiedzi dostajemy pełny skrót znanego serwerowi „niebezpiecznego” URL-a (również w Base64).

Jak łatwo sprawdzić, otrzymany pełny skrót jest tym samym, który wcześniej zredukowaliśmy do czterech bajtów.
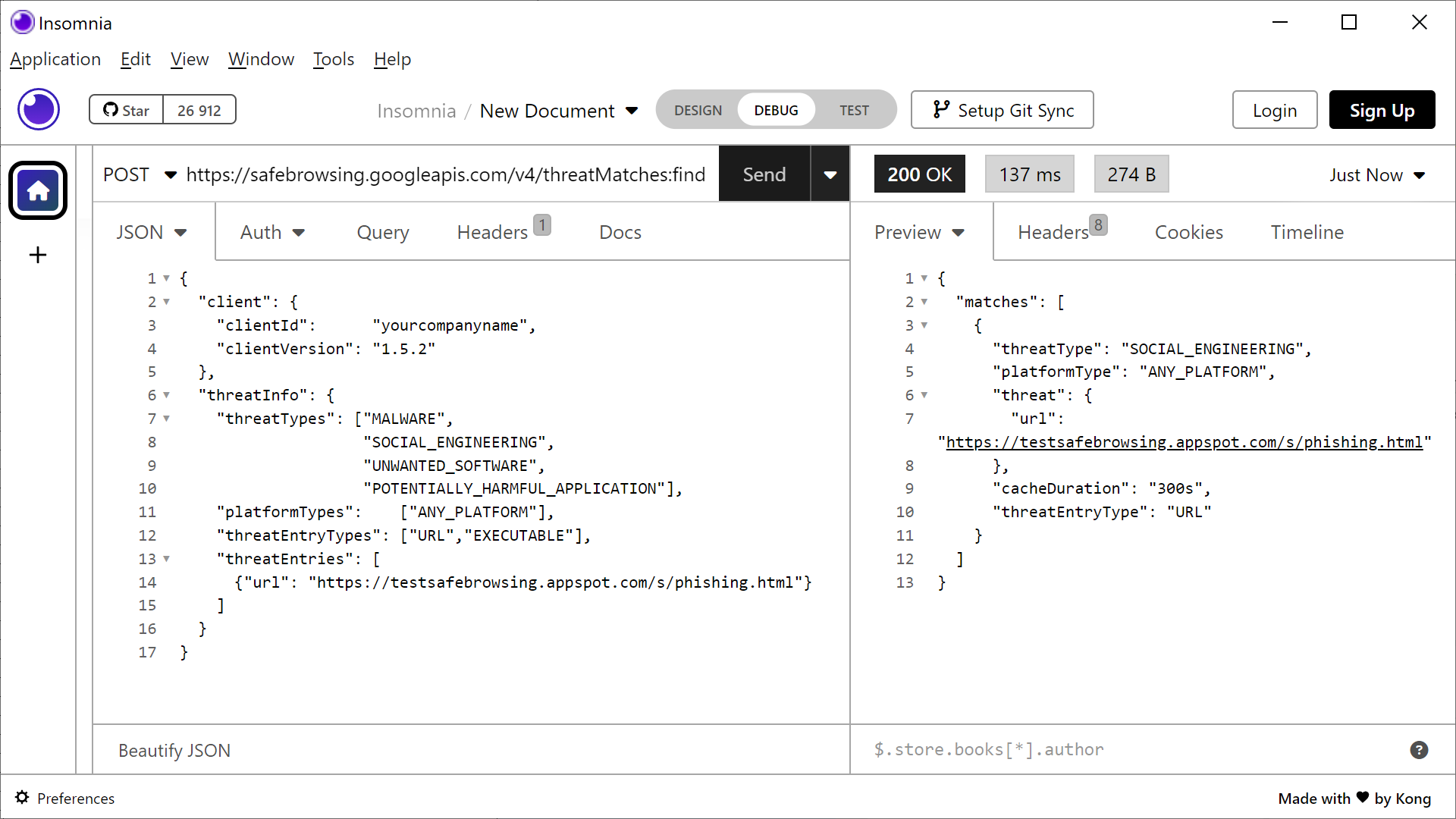
Metoda 5 – sięgamy do lookup API
Google udostępnia także uproszczony wariant API. Nie wymaga ono wyliczania skrótów i stosowania ich prefiksów, jednak kosztem obniżonej prywatności. Poniżej widzimy przykładowe zapytanie (lewa część obrazka) o znaną nam już przykładową, „niebezpieczną” stronę. Odpowiedź (prawa część obrazka) potwierdza zagrożenie i podaje nam jego klasyfikację.
Podobną ścieżką podąża obecna w Chrome opcjonalna usługa Enhanced Safe Browsing – zapewnia ona kontrolę odwiedzanych stron w czasie rzeczywistym. Ponoszonym przez użytkownika kosztem jest obniżona prywatność tak chronionej sesji.
Jeśli bardziej ufasz firmie Apple niż Google, skorzystaj z opcji „Alerty o fałszywych witrynach” w mobilnym Safari – wówczas zapytania do Safe Browsing wystosują w twoim imieniu serwery Apple, pośredniczące w komunikacji.
Metoda 6 – Raport Przejrzystości Google
Mniej zaawansowani użytkownicy mogą sprawdzić podejrzane URL-e w serwisie Raport Przejrzystości Google – dane są tu prezentowane w formie mocno uproszczonej.
Czy to już wszystko?
Istnieje wiele innych metod ochrony użytkownika przeglądarki – na przykład na poziomie DNS (serwera nazw domenowych). Wielu użytkowników zna adres 1.1.1.1 – jest to DNS prowadzony przez firmę Cloudflare. Nie wszyscy wiedzą, że wariant dostępny pod adresem 1.1.1.2 wycina domeny niosące znane zagrożenia – więc nasz komputer nie będzie w stanie się z nimi skomunikować. Podobnie – DNS o adresie 1.1.1.3 eliminuje zagrożenia oraz serwisy dla dorosłych.
Na rodzimym podwórku mamy listę ostrzeżeń prowadzoną przez CERT Polska. Jest ona o tyle cenniejsza, że domeny tam zgłoszone pochodzą z ataków raportowanych przez użytkowników z Polski – lepiej odwzorowuje więc rodzimy krajobraz zagrożeń. Listę można wciągnąć automatycznie do własnej instalacji Pi-hole albo skorzystać z usług operatora, który przystąpił do porozumienia o blokowaniu niebezpiecznych domen.
Poza ramy niniejszego teksty wypadł mechanizm Windows Defender SmartScreen, który dostarcza ochronę dla przeglądarki Edge i systemu Windows.
Na koniec obowiązkowe ostrzeżenie – opisane mechanizmy nie dadzą stuprocentowej ochrony. Zawsze możemy paść ofiarą oszusta, którego schemat działania nie został jeszcze zidentyfikowany i sklasyfikowany. W internecie musisz zachować ciągłą czujność!
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

4 odpowiedzi na “Przeglądarka cię chroni, ale nie śledzi”
W kwestii formalnej – stwierdzenie, że samo w sobie wejście na „lewą” stronę niesie małe ryzyko jest mocnym uproszczeniem. Wprawdzie ostatnio dość dawno nie było jakiegoś głośnego RCE, ani niczego podobnego we współczesnych przeglądarkach, ale nie zakładałbym, że się coś nie trafi. A użytkownicy nie zawsze są z wersjami softu na bieżąco (paradoksalnie, właśnie w niektórych firmach, gdzie każda nowa wersja musi zostać oficjalnie zatwierdzona i ręcznie przyklepana.
Trochę sobie zaprzeczyłeś w dwóch pierwszych zdaniach. A co do firm – równie anegdotycznie powiem, że od dawna już nie słyszałem o jakimkolwiek miejscu walczącym z automatyczną aktualizacją przeglądarek.
Ile to się czasem trzeba napocić, żeby przez te „zabezpieczenia” pobrać plik. A na koniec i tak antywirus jeszcze zablokuje/usunie.
Gmail nie przepuszcza plików exe. Masakra! Też musiałem się pocić, żeby udostępnić koleżance program.
Quad9 – podstawowy 9.9.9.9, zapasowy 149.112.112.112 jest zdecydowanie lepszy od Cloudflare DNS, gdyż używa różnych list, m.in.: CERT Polska.