
Łączenie danych z dwóch różnych źródeł przy użyciu funkcji WYSZUKAJ.PIONOWO albo X.WYSZUKAJ (czyli VLOOKUP/XLOOKUP) to w Excelu swoisty rytuał przejścia. Oddziela on użytkowników początkujących od średnio zaawansowanych.
Wyszukiwanie wg klucza jest w Excelu nierozerwalnie związane ze wspólnym układem współrzędnych. Podajemy zakresy danych dla kluczy, zakresy danych dla rezultatów, preferowany tryb dopasowania danych – przy większych zbiorach danych staje się to naprawdę niewygodne.
Ramki danych języka R pozwalają wiele operacji przeprowadzić w sposób szybszy i czytelniejszy. Tak też będzie dzisiaj – poznamy trzy różne sposoby na łączenie informacji z różnych zestawów danych.
Dane źródłowe
Naszym pierwszym zestawem danych będą dane pogodowe IMGW z roku 2022, których używaliśmy już w poprzednim odcinku Poradnika (obowiązkowa wzmianka: źródłem pochodzenia danych jest Instytut Meteorologii i Gospodarki Wodnej – Państwowy Instytut Badawczy). Spojrzymy na maksymalne temperatury dzienne we Wrocławiu.
Drugim zestawem danych będą pomiary ze Stacji Ciągłych Pomiarów Ruchu (SCPR) zarządzanych przez Główną Dyrekcję Dróg Krajowych i Autostrad (GDDKiA), a konkretnie wartości Średniego Dobowego Ruchu Rocznego (ŚDRR). Spośród dostępnych pomiarów wybierzemy Jawor (stacja nr 2012).

Tak zupełnie przy okazji – byłbym skłonny pochwalić publikacje GDDKiA z taką analizą, jak na obrazku wyżej, gdyby nie fakt, że… zrobiła ją jakaś firma konsultingowa. Takie rzeczy państwowa jednostka powinna ogarniać własnymi siłami.
Najprostsze złączenie kolumn
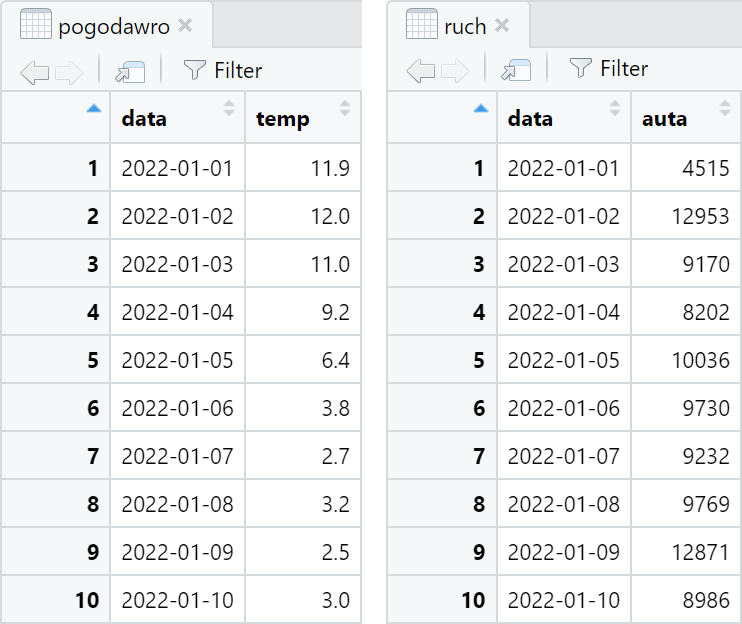
Nasze dwie ramki danych, które możemy na własnym komputerze załadować tym skryptem, wyglądają jak na obrazku powyżej. Obie mają po 365 wierszy i są posortowane wg daty. To oznacza, że możemy je złączyć czysto mechanicznie, bez dopasowywania klucza ani wyszukiwania wartości. W Excelu zaznaczylibyśmy w tym celu kolumnę „auta” i wkleili ją na prawo od kolumny „temp”.
W języku R proste złączenie realizujemy za pomocą komendy bind_cols
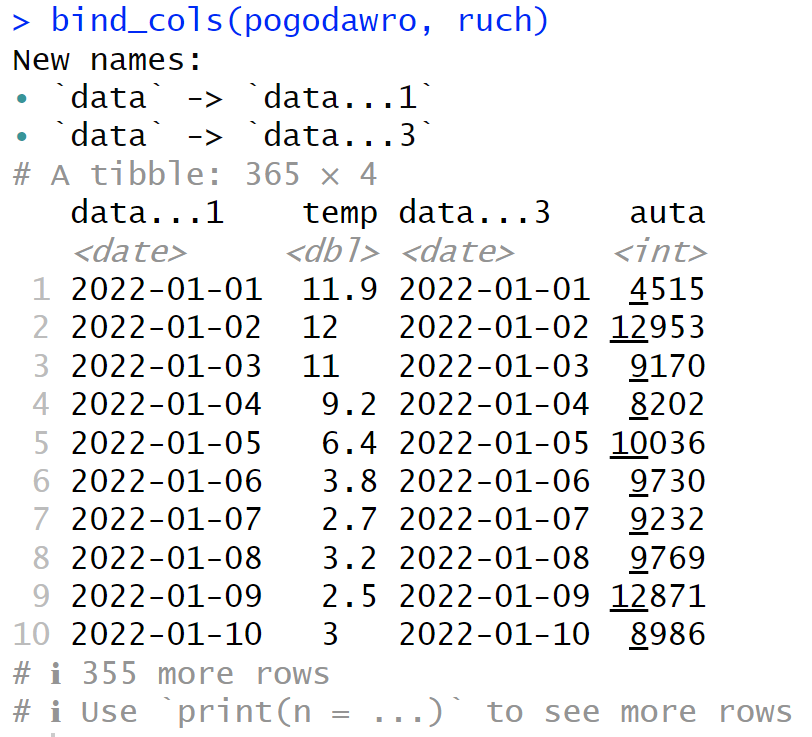
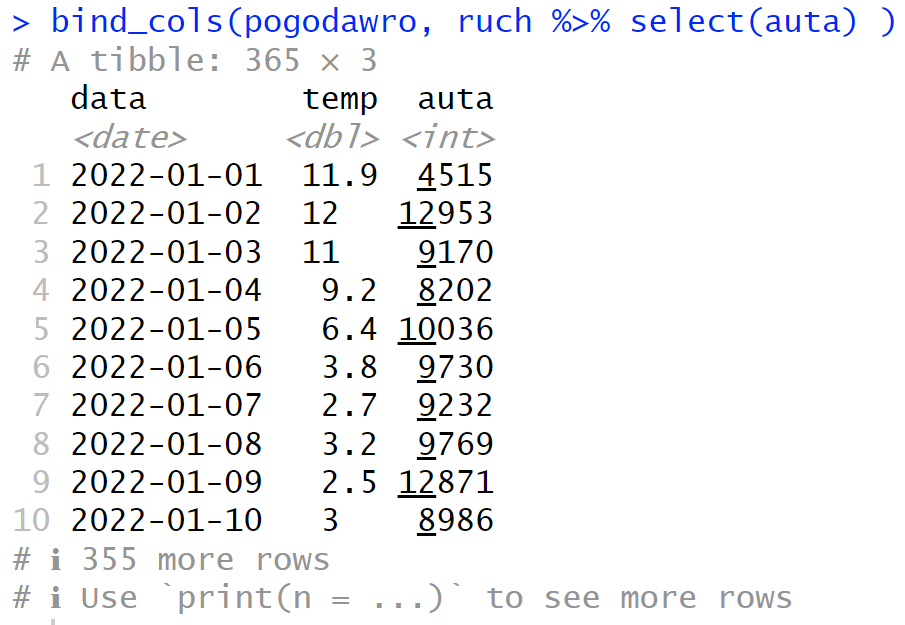
Kolumna „data” pojawia się w złączeniu dwukrotnie, więc obie kopie dostały własne nazwy. Aby tego uniknąć, możemy wyselekcjonować z drugiej ramki jedynie kolumnę „auta”:
Złączenie poprzez przekształcanie ramki
Ta metoda nie jest oczywista, ale przyda się w wielu sytuacjach. Pamiętacie jeszcze szósty odcinek Poradnika, ten o przekształcaniu ramek danych do postaci szerokiej lub wąskiej? Dziś do tego wracamy!
Aby przykład był czytelniejszy, z obu ramek danych weźmiemy pierwszych 30 pomiarów. Z nich losowo wybierzemy po 20 wierszy, by dowieść, że kryterium złączenia stanowi kolumna z datą. Następnie zunifikujemy nazewnictwo kolumn i połączymy wiersze w jedną ramkę danych.

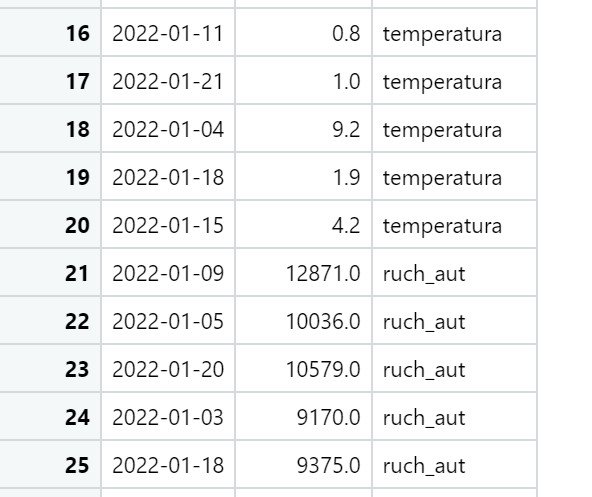
Środek nowej ramki danych o nazwie „sklejka” wygląda następująco, zwróćmy uwagę na losową kolejność wierszy w każdej sekcji.
Teraz wystarczy użyć funkcji pivot_wider, aby wąską ramkę danych przekształcić do postaci szerokiej. Kluczem przekształcenia jest kolumna „data”, która zachowuje swoją pozycję.
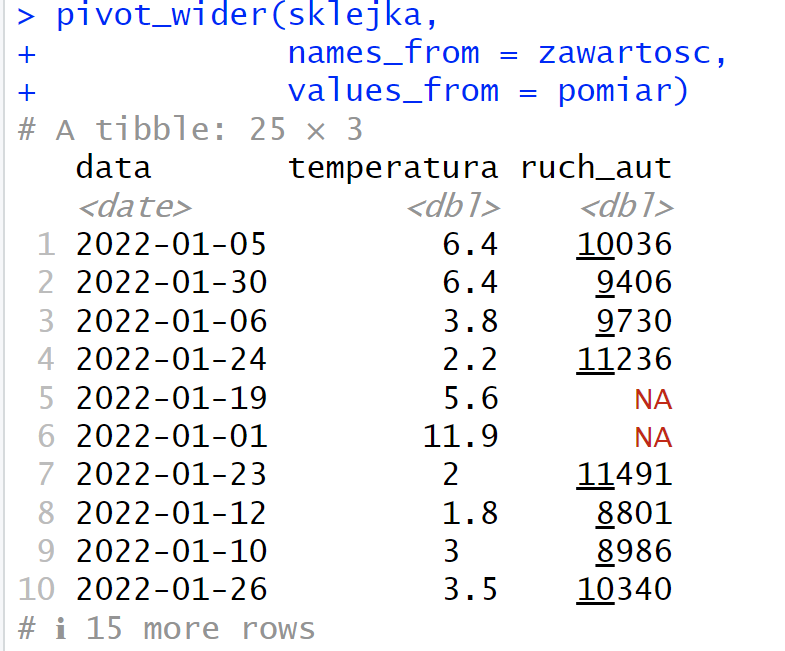
W moim przykładzie finalna szeroka ramka danych ma 25 wierszy, czyli 15 dat powtórzyło się w obu zbiorach zaś po 5 było unikalnych. Gdy wykonacie kod z GitHuba, losowanie zapewne przebiegnie inaczej – jednak wierszy wynikowych będzie zawsze od 20 do 30.
Złączenie poprzez… złączenie
W podstawowym języku R złączenia dwóch ramek w oparciu o wspólny klucz dokonuje się przy użyciu funkcji merge, jednak my skupimy się na rodzinie funkcji _join wywodzącej się z pakietu Tidyverse. Wszyscy, którzy mają doświadczenie w pracy z językiem SQL, poczują się jak w domu – semantyka opisywanych funkcji będzie bliźniaczo podobna do operacji JOIN w relacyjnych bazach danych.
Przypomnijmy – dysponujemy dwiema ramkami danych, każda z kolumną zawierającą datę, będącą kluczem złączenia. Jedna ramka danych zawiera dane o temperaturach, druga o ruchu pojazdów. Aby pokazać wszystkie daty z co najmniej jednym z pomiarów, użyjemy polecenia:
zlaczenie <- full_join(pogodawro20, ruch20, by="data") %>% arrange(data)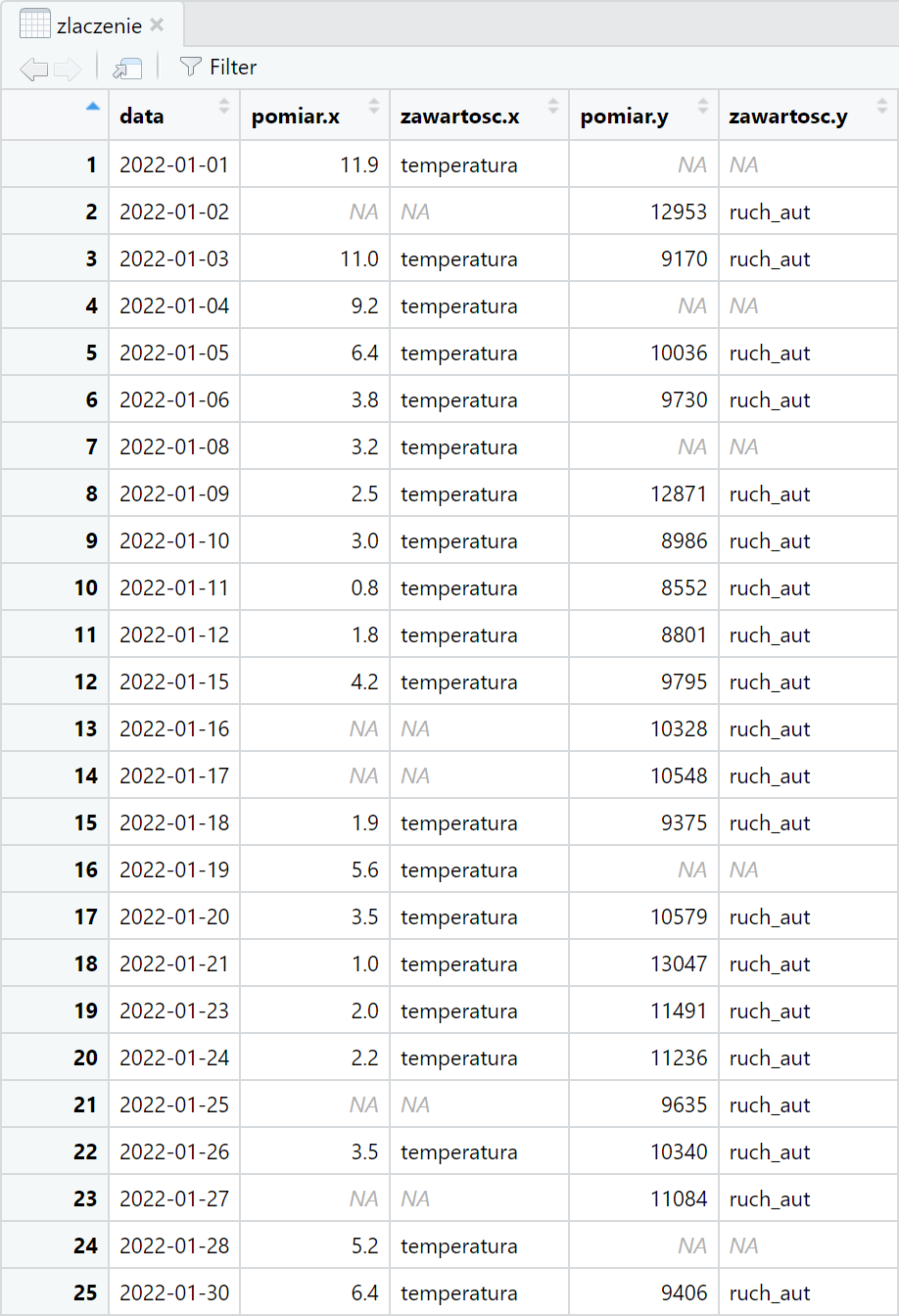
Rezultatem jest 25 wierszy, z których 15 ma obie mierzone wartości, 5 – tylko temperaturę, zaś 5 – tylko ruch pojazdów. Tutaj kolumny, których nazwa powtarzała się, otrzymują końcówki „.x” lub „.y”.
Mamy do dyspozycji także inne typy złączeń:
inner_join– tylko wiersze z obustronnym dopasowaniem; w opisywanym przypadku będzie to 15 wierszy z pomiarami obu kategoriileft_join– wszystkie wiersze z lewej strony, plus dopasowania; tu otrzymamy 20 pomiarów temperatury, wśród nich 15 dopasowanych pomiarów ruchuright_join– wszystkie wiersze z prawej strony, plus dopasowania; tu otrzymamy 20 pomiarów ruchu, wśród nich 15 dopasowanych pomiarów temperaturyanti_join– złączenie wykluczające, otrzymamy 5 pomiarów temperatury, które nie mają dopasowania w pomiarze ruchunest_join– wariant użyteczny przy relacji jeden-do-wielu, w nowej kolumnie dostajemy zagnieżdżone ramki danych z wszystkimi dopasowaniami
Złączenia w języku R mają tę przewagę nad Excelem, że dopasowanie można definiować parametrem „by” w oparciu o więcej niż jedną kolumnę. Przykład – gdyby rok, miesiąc i dzień były osobnymi kolumnami, użylibyśmy konstrukcji:
full_join(pogodawro20, ruch20, by=c("rok", "miesiąc", "dzień" ))Złączenia nie muszą opierać się o kolumny o identycznych nazwach, w argumentach możemy przekazać nazwy kolumny klucza z obu ramek:
full_join(ramka1, ramka2, by = c("data" = "full_calendar_date"))Dwie wymienione techniki można oczywiście stosować łącznie:
full_join(ramka1, ramka2, by = c("rok"="R", "miesiąc"="M", "dzień"="D" ))Podsumowanie
Po raz kolejny przekonaliśmy się, że użytkownicy Excela mają czego zazdrościć użytkownikom języka R. Choć funkcja X.WYSZUKAJ stanowiła istotny krok do przodu, gdy porównamy ją do funkcji WYSZUKAJ.PIONOWO, to nadal wymaga operowania zakresami i kopiowania formuł między komórkami.
Złączenia w języku R mają nie tylko czytelniejszą składnię, ale oddzielają dane od operacji na danych. Dzięki temu jeden przetestowany skrypt możemy łatwo i szybko użyć do przekształcania wielu plików wejściowych.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.
