
Niepewna przyszłość Twittera sprawia, że część jego użytkowników rozgląda się za alternatywami. Korzysta na tym Fediverse i Mastodon, ale czy niespodziewaną szansę wykorzystuje Albicla?
Ta rodzima sieć społecznościowa, która będzie obchodziła niedługo drugie urodziny, nie przebiła się do mainstreamu. A może… Może straciliśmy czujność a w rzeczywistości mamy do czynienia z przyczajonym tygrysem? Odpowiedź znajdziecie w artykule!
Nasz cel: chcemy dowiedzieć się, ilu użytkowników przybywa co miesiąc portalowi Albicla. Co więcej – chcemy dowiedzieć się tego tu i teraz, bez konieczności prowadzenia obserwacji długoterminowych.
Albicla nie ma centralnego spisu kont, więc musimy poradzić sobie inaczej. Na szczęście dostępne są podstawowe funkcje każdej sieci społecznościowej, czyli obserwowanie oraz nawiązywanie znajomości – zaś listy znajomych i obserwowanych są publiczne. Spójrzmy na profil Tomasza Sakiewicza, założyciela Albicli.
Uwagę zwracają dwa liczniki – znajomych oraz obserwujących. Nie działa niestety – i nigdy nie działała – funkcja pokazująca użytkowników obserwowanych. Z satysfakcją odnotowujemy jednak, że na stronie albicla.com/TomaszSakiewicz/obserwujacy odnajdziemy tysiące ułożonych chronologicznie profili obserwujących Tomasza Sakiewicza (choć jest ich nieco mniej, niż sugeruje licznik).

Mamy więc listę osób obserwujących Sakiewicza. Zapiszmy ją sobie. A gdyby tak odwiedzić po kolei te profile i znaleźć wszystkich, którzy obserwują obserwujących Sakiewicza? A potem tych, którzy obserwują obserwujących obserwujących Sakiewicza? Wiecie o co chodzi. Za którymś razem nie odnajdziemy już żadnych nowych profili.
Teoria zbiorów
Przypomnijmy sobie operacje na zbiorach z pierwszej klasy szkoły podstawowej (na studiach mówi się na to teoria mnogości). Utworzymy dwa zbiory – kont oczekujących na przetworzenie oraz kont przetworzonych. Następnie zaczniemy przeglądanie portalu Albicla według następującego algorytmu
* dodaj konto TomaszSakiewicz do zbioru oczekujących
* wykonuj blok operacji, dopóki zbiór kont oczekujących jest niepusty:
{
* rozpatrz dowolne konto ze zbioru oczekujących
* odczytaj z portalu wszystkie kontakty i obserwujących rozpatrywanego konta
* dodaj do zbioru oczekujących te znalezione konta, których nie ma w żadnym zbiorze
* przenieś rozpatrywane konto do zbioru kont przetworzonych
}Gdy powyższy algorytm zakończy pracę, zbiór kont oczekujących będzie pusty a w zbiorze kont przetworzonych będziemy mieli wszystkie konta, do których da się dojść po listach „znajomych” i „obserwujących”, począwszy od konta TomaszSakiewicz (gdybyśmy chcieli szpanować terminologią, przytoczylibyśmy w tym momencie definicję relacji przechodniej).
Implementacja scrapera
Gdy skrypt wykonujący powyższą operację będzie jednowątkowy, w roli zbiorów mogą wystąpić dwa foldery. Elementami zbioru będą wówczas pliki tworzone w pierwszym folderze, które stopniowo będą przenoszone do drugiego folderu.
Oto przykładowa implementacja takiego skryptu
#!/bin/bash
set -euo pipefail
SOURCEDIR=/home/ubuntu/albiclator/01beforecheck/
TARGETDIR=/home/ubuntu/albiclator/02checked/
while [ "$(ls -A $SOURCEDIR)" ]; do
files=($SOURCEDIR/*)
file="${files[0]}"
basefile=$(basename ${file})
echo $basefile
dotnet run --project _01findusers/ $SOURCEDIR $TARGETDIR $basefile
mv $file $TARGETDIR
doneUwaga – w powyższym przykładzie świadomie godzimy się na niską efektywność rozwiązania, które pozostaje dzięki temu bardzo proste. Brakuje też reakcji na błędy pobierania danych, wynikające np. z błędnego cookie. Szkolenie uczy metod przyspieszania pobierania danych z tego samego serwera oraz monitorowania wyników scrapowania.
W katalogu _01findusers znajduje się dotnetowy program, który dla każdej przekazanej nazwy konta odczyta dwa pliki HTML z lokalizacji albicla.com/nazwakonta/znajomi oraz albicla.com/nazwakonta/obserwujacy.
Aby dostęp do tych stron był możliwy, do żądania HTTP należy dołączyć ciasteczko aa_user otrzymane z serwera po udanym zalogowaniu. Ciasteczko takie jest ważne miesiąc. Albicla stosuje tzw. renderowanie po stronie serwera, czyli dostarcza do przeglądarki kompletną stronę HTML do wyświetlenia. Jak z takiej strony wyciągnąć nazwy obserwujących i znajomych? W pojedynczym bloku interesują nas tagi oznaczone na żółto (obrazek z avatarem) oraz zielono (nazwa obserwującego / polubionego konta).

Komplet takich elementów najprościej wyciągnąć za pomocą wyrażenia XPath //img[@class="rounded-circle img-responsive"], które dopasuje się do wszystkich obrazków z klasami CSS „rounded-circle img-responsive” (wyrażenie XPath wypróbujesz tutaj). Dostaniemy zbiór obrazków profilowych, zaś nazwę konta odczytamy sięgając poziom wyżej, do atrybutu href macierzystego węzła a.
Realizujący to zadanie kod C#, korzystający z biblioteki HtmlAgilityPack, wygląda następująco:

Funkcja foundUser sprawdza, czy dany profil był już kiedyś widziany (czy występuje w dowolnym z dwóch katalogów). Jeśli nie, tworzy plik o nazwie takiej, jak nazwa profilu, w katalogu plików oczekujących na przetworzenie. W treści pliku zapisuje URL obrazka profilowego.
Skrypt o powyższej konstrukcji odnalazł 31187 profili, których użytkownicy choćby w niewielkim stopniu zainteresowali się funkcjami portalu. Wśród nich możemy wyróżnić dokładnie 16636 użytkowników bardziej aktywnych, którzy dodali własny obrazek profilowy.
Chytra sztuczka
Po co nam URL do obrazka? Przypomnijmy – chcemy dowiedzieć się, ilu użytkowników przybywa co miesiąc portalowi Albicla. Na razie nie zbliżyliśmy się do tego celu, poznaliśmy jedynie listę tych użytkowników portalu, którzy korzystają z funkcji obserwowania lub dodawania do znajomych. Nazwy kont ani daty ich założenia nie powiedzą nam, ile profili przegapiliśmy.
Typowy URL obrazka profilowego ma następującą postać: albicla.pl/imgcache/150x150/c/uploads/avatar/1000000103_1611157274.png
(konta bez obrazka profilowego używają URL-aalbicla.pl/imgcache/150x150/c/data/img/no-avatar.png)
Przyjrzyjmy się nazwie pliku, na którą składają się dwie liczby. Porównanie kilku URL-i pozwala nam stwierdzić, że pierwsza liczba to numer kolejny konta Albicli (możemy założyć dwa konta jedno za drugim, aby zyskać pewność). Druga liczba to czas uniksowy, liczba sekund liczona od początku roku 1970. Eksperymentalnie potwierdzamy, że jest to data wysłania obrazka na serwery Albicli – wystarczy kilka razy wysłać ten sam obrazek i zaobserwować zmiany URL-a.
Przetwarzamy numery z avatarów
Ściągnęliśmy kilkadziesiąt tysięcy plików, w części z nich mamy interesujące nas informacje. Oto zawartość dwóch przykładowych plików:
https://albicla.pl/imgcache/150x150/c/uploads/avatar/1000000103_1611157274.png
https://albicla.pl/imgcache/150x150/c/uploads/1000000008/avatar/1000000008_1612270752.jpg
Jak najprościej wyciągnąć dane do dalszej analizy? Poznajcie uniksowe narzędzia tekstowe!
grep -v no-avatar * \
| sed 's/\:https.*\//,/' \
| sed 's/\..*//' \
| sed 's/\([0-9]\)_\([0-9]\)/\1,\2/' \
> ../extracted.csvSkrypt operuje na wszystkich plikach z bieżącego katalogu. Oto znaczenie poszczególnych linii, wszystkie połączone są potokami (wyjście jednej komendy jest wejściem dla kolejnej) a na końcu wynik zapisywany jest do pliku csv.
W linii pierwszej czytamy zawartość wszystkich plików i usuwamy linie zawierające tekst no-avatar (argument -v odwraca zachowanie polecenia grep). Grep doklei do każdego wiersza nazwę pliku w którym odnaleziono wzorzec. Dostaniemy więc na wyjściu linie wyglądające np. tak:GazetaPolska:https://albicla.pl/imgcache/150x150/c/uploads/1000000008/avatar/1000000008_1612270752.jpg
W drugiej linii skryptu wycinamy zawartość URL-a, od pierwszego dwukropka do ostatniego ukośnika i wstawiamy w ich miejsce przecinek. Przykładowe wyjście:GazetaPolska,1000000008_1612270752.jpg
W trzeciej linii usuwamy rozszerzenie pliku czyli kropkę i wszystko, co następuje po niej. Przykładowe wyjście:GazetaPolska,1000000008_1612270752
W czwartej linii zamieniamy podkreślenie między dwoma cyframi na przecinek. Znacznie prostszą konstrukcję miałby filtr tr '_' ',', lecz wtedy rykoszetem oberwie profil o nazwie MS_GOV_PL. Przykładowe wyjście:GazetaPolska,1000000008,1612270752
Potem wszystkie 16636 tak przetworzonych linii tekstu kierujemy do pliku wyjściowego CSV.
Dynamika wzrostu Albicli
Podsumujmy – dysponujemy niekompletnymi informacjami o numeracji kont oraz datach, w których po raz ostatni ustawiono obrazek profilowy. Umieśćmy te dane na wykresie (uczestnicy szkolenia otrzymali skrypty języka R generujące poniższe grafiki i tabele)
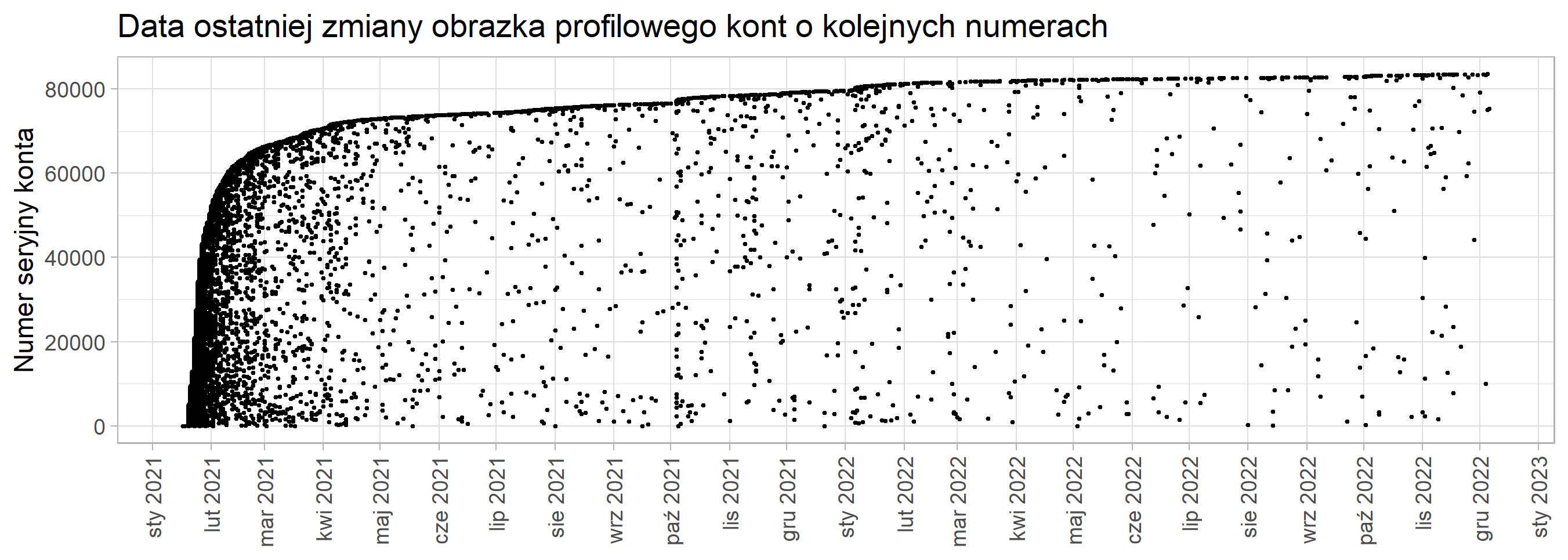
Mało to przejrzyste, ograniczmy się do kont o największym numerze w obrębie jednego dnia.

Znacznie lepiej. Teraz dla każdego miesiąca określimy konto o największym numerze i sprawdzimy, ile kont przybyło w stosunku do poprzedniego miesiąca. Uwaga – choć pomagamy sobie danymi użytkowników mających ustawione obrazki profilowe, to numery profili zdradzają informację o globalnej liczbie zarejestrowanych kont.
month maxindex delta 2021-01 50381 50381 2021-02 66177 15796 2021-03 70508 4331 2021-04 72947 2439 2021-05 73772 825 2021-06 74327 555 2021-07 75375 1048 2021-08 76182 807 2021-09 76605 423 2021-10 78325 1720 2021-11 79063 738 2021-12 79586 523 2022-01 81226 1640 2022-02 81619 393 2022-03 81932 313 2022-04 82187 255 2022-05 82355 168 2022-06 82479 124 2022-07 82634 155 2022-08 82776 142 2022-09 82922 146 2022-10 83338 416 2022-11 83497 159
Widzimy, że w ostatnim półroczu średnia liczba nowych użytkowników Albicli (kolumna „delta”) nie przekraczała 200 miesięcznie. Nie jest to imponujący wynik – social media Informatyka Zakładowego rosły w tym czasie o łącznie 1200 obserwujących miesięcznie.
Aktywność użytkowników sieci Albicla
Dowiedzieliśmy się, ilu użytkowników przybywa Albicli w jednym miesiącu, ale nie wiemy, czy procent „martwych dusz” zmieniał się w czasie (odkryliśmy 38% procent łącznej liczby profili).
Skorzystajmy z faktu, że konta zawierają informację o dacie założenia – pobierzmy ją ze wszystkich stron profilowych. Da się to zrobić jednorazowym wywołaniem curl-a! No dobra, polecenie ma niebagatelne 400 tysięcy znaków, ale działa! Potem prosty grep sprawi, że do osobnego pliku wpadnie 31187 dat, które pogrupujemy miesiącami i dokleimy do poprzedniej tabeli. Policzymy też stosunek profili odnalezionych do wszystkich z danego miesiąca.
month maxindex delta znalezieni ratio 2021-01 50381 50381 20501 0.40 2021-02 66177 15796 5903 0.37 2021-03 70508 4331 1522 0.35 2021-04 72947 2439 680 0.27 2021-05 73772 825 194 0.23 2021-06 74327 555 152 0.27 2021-07 75375 1048 305 0.29 2021-08 76182 807 212 0.26 2021-09 76605 423 108 0.25 2021-10 78325 1720 406 0.23 2021-11 79063 738 168 0.22 2021-12 79586 523 118 0.22 2022-01 81226 1640 402 0.24 2022-02 81619 393 99 0.25 2022-03 81932 313 70 0.22 2022-04 82187 255 63 0.24 2022-05 82355 168 49 0.29 2022-06 82479 124 28 0.22 2022-07 82634 155 27 0.17 2022-08 82776 142 31 0.21 2022-09 82922 146 32 0.21 2022-10 83338 416 74 0.17 2022-11 83497 159 37 0.23
Widzimy, że w pierwszych trzech miesiącach istnienia portalu użytkownicy byli najbardziej towarzyscy – odnaleźliśmy 35-40% profili z tego okresu. Potem miała miejsce długotrwała stagnacja, podczas której raptem jeden na czterech nowych użytkowników zaczynał obserwować inne profile. W ostatnich miesiącach 2022 ten wskaźnik jeszcze się pogorszył.
Zastrzeżenia
Inaczej, niż w artykule sprzed półtora roku, tym razem nie scrapowaliśmy wpisów ani serduszek. W powyższych zestawieniach nie uwzględniamy więc profili, które tylko publikują i lajkują, nie obserwując ani nie lubiąc żadnego innego konta. Wspomnijmy dla porządku, że opisana powyżej metoda nie pozwoli wykryć grup użytkowników obserwujących się jedynie we własnym gronie, jednak ich istnienie jest mało prawdopodobne. Dane, na których bazuje artykuł, pobrano na początku grudnia 2022.
Podsumowanie
W niniejszym artykule zademonstrowałem, jak za pomocą automatycznego pobierania i przetwarzania danych pozyskaliśmy informacje o aktywności sieci społecznościowej Albicla od początku jej istnienia. Dowiedzieliśmy się, że liczba nowych użytkowników to obecnie kilka osób dziennie i nic nie wskazuje na to, aby kłopoty Twittera w jakikolwiek sposób przełożyły się na popularność Albicli. Aktywność sieci również spada – w pierwszym półroczu opublikowano w Albicli tyle wpisów, co przez kolejne półtora roku.
Skrypty użyte do przygotowania niniejszego artykułu stanowią materiał dodatkowy udostępniony uczestnikom Szkolenia ze scrapowania, którego druga edycja pozostanie w sprzedaży już tylko dwa dni, do soboty 10.12.2022, godz. 22:00.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

16 odpowiedzi na “Nieliczni fani portalu Albicla”
[…]
| sed 's/\:https.*\//,/’ \
| sed 's/\..*//’ \
| sed 's/\([0-9]\)_\([0-9]\)/\1,\2/’
[…]
Nie dałoby się zamienić na:
sed -e … -e … -e …
?
A drugie pytanie:
„No dobra, polecenie ma niebagatelne 400 tysięcy znaków, ale działa! ”
Nie pamiętam jakie są teraz limity na długość lini komend w linuksie, ale trochę jestem zaskoczony, że działa.
Sam sobie odpowiem.
~%getconf ARG_MAX
2097152
Czyli jakieś 2 miliony 🙂
Nie musisz tego robić przez „-e”. Wystarczy zwykły średnik między regexpami.
Podejrzewam że taki zapis jest zastosowany przede wszystkim dla poprawy czytelności.
Limit nie dotyczy przypadkiem jednego polecenia? Ja tu widzę zbiór poleceń połączonych potokiem, więc nie takie jedno polecenie. 😉
Tego polecenia na 400k znaków nigdzie nie publikowałem 😉
Masz szczęście, że mieszkasz w Polsce i atakujesz w ten sposób polski serwis, bo rozumiem, że zgody na scraping tysięcy profili nie dostałeś od nich?
Dla wszystkich obrońców scrapingu polecam go zrobić na Facebooku albo Instagramie. I się zdziwicie, bo FB pozywa ludzi na całym świecie za scraping, dostaniesz pozew w US i kraju pochodzenia (dane wezmą z twojego profilu, z prywatnych wiadomości etc., mają to w regulaminie, który złamałeś robiąc scraping bez ich zgody), a wyrok z US zostanie potem zarejestrowany w kraju pochodzenia. Zdziwko? No to do boju scrapingowi bohaterowie!
Jestem pełen podziwu jak ludzie tacy jak ty nie zdają sobie sprawy z legalności swoich działań w innych systemach prawnych, a twoje działania tylko mogą kogoś zachęcić do takiego czynu, a w konsekwencji skończą się tak:
https://www.engadget.com/facebook-sues-programmer-over-data-scraping-185924315.html
https://techcrunch.com/2022/10/03/meta-settles-lawsuit-for-significant-sum-against-businesses-scraping-facebook-and-instagram-data/
https://www.zdnet.com/article/facebook-sues-two-chrome-extension-makers-for-scraping-user-data/
(ten przykład pokazuje, że nie musisz scrapować milionów kont)
https://techcrunch.com/2016/08/15/linkedin-sues-scrapers/
(nie tylko FB pozywa za to)
I z informatyka zakładowego zostaniesz skazańcem w zakładzie…
Pozwać może każdy każdego o cokolwiek. Czy wiemy, jakimi wyrokami zakończyły się te procesy?
Jeśli już wrzucasz linki z artykułami o pozwach za scraping to wrzuć także coś o rezultatach tych spraw. Np. tutaj – https://techcrunch.com/2022/04/18/web-scraping-legal-court wspomniany już LinkedIn koncertowo przewalił sprawę w sądzie. Scrapowanie publicznie dostępnych danych (w tym profili na Albicli) jest w pełni legalne i nie różni się niczym od ręcznego odwiedzania profili. Zupełnie inną sprawą byłoby gdyby scraping spowodował niedostępność usługi i to już mogłoby być potraktowane jako atak DoS i tutaj Albicla miałaby w sądzie pole do popisu.
Co do US i pozwów to też zalecałbym dystans. Tam się ludzie pozywają za zbyt ciepłą kawę czy ości w kanapce rybnej. Myślę że Polakowi za scrapowanie profili na fejsie Guantanamo nie grozi.
Zresztą nawet w Polsce możesz założyć sprawę cywilną komukolwiek o cokolwiek, nawet o to że sąsiad za ścianą za głośno bąka puścił. A to że to się nie obroni w żadnym sądzie to inna para kaloszy.
Albiclę scrapowałem jednowątkowo. Portal społecznościowy na kilkadziesiąt tysięcy użytkowników powinien wytrzymać takie obciążenie, wysoki sądzie.
A USA mogą Polaka w rzyć pocałować. Nie jest obywatelem amerykańskim i nie przebywa w USA => nie obowiązuje go amerykańskie prawo.
Oglądałem stare, nowego jeszcze nie. Ale jakoś wtedy nie odczułem, iż tak bardzo skaczesz między językami. Najpierw bash, potem C#, a kończysz R.
niektóre rzeczy łatwiej zrobic w jednym inne w drugim. Wykres chcesz rysować w bashu? 🙂
I jak patrzę na taką kombinację to rozumiem popularność Pythona, jest czytelniejszy i łatwiejszy w użyciu od Basha, w standardzie jest wiele funkcji, które spokojnie zastąpią narzędzia takie find, sed czy awk, a społeczność dostarcza wielu rozszerzeń. I problem z przenośnością kodu jest zdecydowanie mniejszy.
Drugia edycja szkolenia ze scrapowania jest już dostępna?
Była dostępna od 1 do 10 grudnia 2022. Kolejne okienko w przyszłym roku.
W ogóle kwestia indeksowania tego serwisu jest mega dziwna. Większość podstron jest dostępnych tylko po zalogowaniu, przez co Google indeksuje linki /embed/.