
Zamknijcie oczy i wyobraźcie sobie realny i najwyższy stopień zagrożenia infrastruktury teleinformatycznej państwa. Co widzicie? Telekomy rzucone na kolana przez ransomware? Płonące serwerownie platformy ePUAP? Agencję Wywiadu zinfiltrowaną przez wrogów? Ujawnione sekrety NATO? No to się zdziwicie.
W opinii niektórych urzędników, bardziej niszczycielskie skutki miałoby… udostępnienie kodu źródłowego Systemu Losowego Przydziału Spraw. Przecieracie oczy z zaskoczenia? Ja, podczas lektury pisma z Ministerstwa Sprawiedliwości, miałem ochotę je sobie wydłubać.
Wcześniejsze teksty o Systemie Losowego Przydziału Spraw
[2020-12-14] System Pseudolosowego Przydziału Spraw – opisałem problemy z SLPS i objaśniłem, dlaczego celowe błędy wpływające na działanie generatora liczb pseudolosowych mogą wyglądać tak, jak staranny kod niekompetentnego programisty
[2021-05-02] NIK o SLPS: Nie osiągnięto celów całego przedsięwzięcia – zestaw cytatów na temat SLPS z raportu Najwyższej Izby Kontroli
[2021-07-30] O algorytmach dla prawników – objaśniam krok po kroku, czym algorytm różni się od programu komputerowego i dlaczego bez dostępu do kodu źródłowego nie będziemy wiedzieć, czy pozornie poprawny program nie zawiera błędów
[2021-10-03] Poznaliśmy algorytm losowania SLPS czyli… co dokładnie? – oceniam, jaką wartość ma dokument udostępniony przez Ministerstwo Sprawiedliwości
[2022-01-14] Przejrzystość SLPS – duży krok do przodu – na stronach Portalu Sądowego pojawiła się wyszukiwarka raportów z losowań – niestety zabezpieczona mechanizmem reCAPTCHA
[od kwietnia 2024] Monitor SLPS – wpisy w serwisie slps.pl
[2025-01-09] Realny i najwyższy stopień zagrożenia – opinia do wyroku WSA oddalającego skargę na odmowę udostępnienia kodu źródłowego SLPS
Dwa słowa wprowadzenia: Mamy rok 2025. Sprawa dostępu do kodu źródłowego SLPS ciągnie się od roku 2017. Dokładniejsze informacje znajdziecie na stronach Sieci Obywatelskiej Watchdog Polska i w podlinkowanych tam zasobach. Niniejszy tekst stanowi komentarz do następujących dokumentów:
- Decyzja z 16 października 2023, w której Ministerstwo Sprawiedliwości odmawia udostępnienia informacji publicznej, jaką jest kod źródłowy SLPS.
- Wyrok WSA w Warszawie z dnia 26 kwietnia 2024 oddalający skargę Sieci Obywatelskiej Watchdog Polska na ową decyzję.
Niniejszy tekst został przygotowany dla Stowarzyszenia Sieć Obywatelska Watchdog Polska na potrzeby postępowania kasacyjnego i jest publikowany za zgodą Stowarzyszenia na licencji Creative Commons CC BY 4.0 (uznanie autorstwa).
O autorze: Tomasz Zieliński, zawodowy programista z ponad 20-letnim stażem. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad wyszukiwarką internetową Microsoft Bing. Pasjonat bezpieczeństwa informatycznego, autor bloga Informatyk Zakładowy oraz serwisu Monitor SLPS.
Uwagi do wyroku II SA/Wa 2336/23
W niniejszym tekście wskazuję błędy w rozumieniu zagadnień związanych z oprogramowaniem, które znalazły się w uzasadnieniu oddalenia skargi Stowarzyszenia Sieć Obywatelska Watchdog Polska na decyzję o odmowie udostępnienia przez Ministerstwo Sprawiedliwości kodu źródłowego Systemu Losowego Przydziału Spraw.
Zamierzam wskazać, że skarżona decyzja była pełna fałszywych tez, mających siać strach, wątpliwości i niepewność. Już podstawowa wiedza o budowie systemów informatycznych wystarcza, by obalić ich znakomitą większość.
Pojęcia i definicje
… przeznaczone dla osób, które chcą lepiej zrozumieć terminy związane z produkcją oprogramowania.
Kod źródłowy
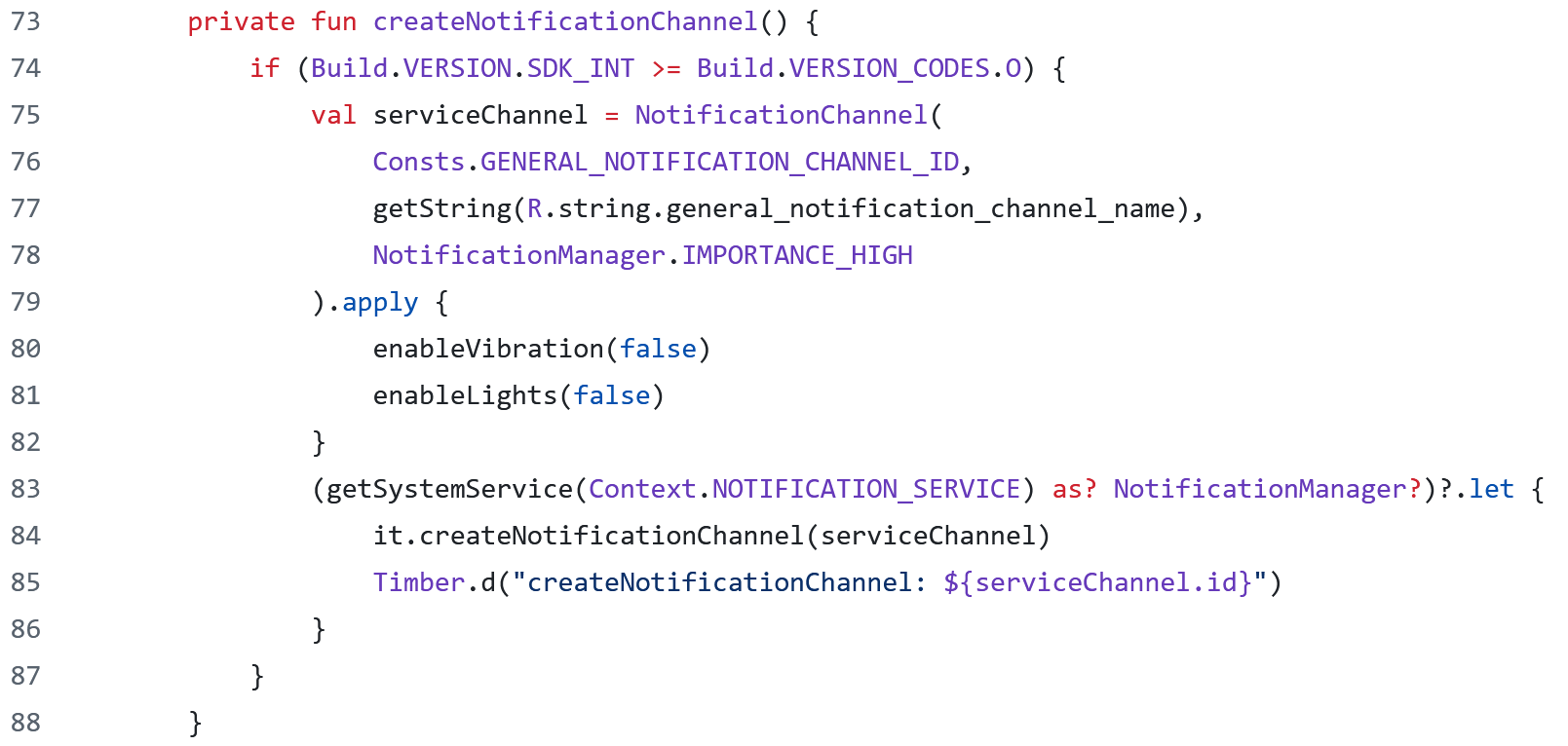
Kod źródłowy to tekst programu tworzony przez programistę w wybranym języku programowania. Kod źródłowy opisuje, jak komputer będzie przetwarzał dane, ale jest to tylko zestaw plików z napisami podobnymi do tych na obrazku powyżej.
Osoby znające dany język programowania potrafią prześledzić „w głowie” sekwencję czynności, jakie podejmie program, i w ten sposób zrozumieć jego działanie. Nie jest do tego potrzebny komputer, analizę taką można byłoby przeprowadzić czytając kod źródłowy wydrukowany na papierze.
Kod źródłowy przekształcany jest w program wykonywalny za pomocą narzędzi programistycznych, w skład których wchodzi tzw. kompilator.
Program wykonywalny (kod binarny, kod programu)
Program wykonywalny to plik z instrukcjami, które mogą być wykonane przez procesor komputera – w systemie Windows są to m.in pliki typu EXE (np. calc.exe to aplikacja Kalkulator).

Program wykonywalny ma postać nieczytelną dla człowieka, co widać na obrazku. Specjaliści bezpieczeństwa potrafią analizować i zrozumieć kod wykonywalny, jest to jednak umiejętność wymagająca talentu i wytrwałości.
Baza danych
Baza danych (lub bardziej poprawnie: silnik bazy danych) to program pozwalający na przechowywanie dużych ilości danych. Składowane informacje mają określoną strukturę i relacje, np. baza danych SLPS przechowuje listę sądów i wydziałów, gdzie sąd może mieć wiele wydziałów a każdy wydział należy do dokładnie jednego sądu.
Silnik bazodanowy jest wyspecjalizowany w szybkim zapisie i odczycie danych oraz efektywnym wyszukiwaniu wg zadanych kryteriów. Pozwala też przydzielać różnym użytkownikom różne uprawnienia, np. pokazywać strukturę sądów każdemu, ale pozwalać na jej edycję tylko administratorowi bazy.
Sekrety
W terminologii twórców oprogramowania sekretem jest informacja, która jest potrzebna do działania programu, ale która musi być chroniona przed ujawnieniem. Przykładem mogą być hasła dostępowe wymagane do współdziałania różnych systemów informatycznych.
Poprawnie napisany kod źródłowy nie zawiera sekretów. W powyższym przykładzie hasło powinno być zapisane w pliku konfiguracyjnym, który nie stanowi części kodu źródłowego, lecz jest tworzony dopiero podczas instalacji programu.
Co wiemy o budowie SLPS
Z dokumentów opublikowanych na stronach internetowych Ministerstwa Sprawiedliwości (www.gov.pl/web/sprawiedliwosc/rozeznanie-rynku-na-uslugi-wsparcia-i-modyfikacji-systemu-losowego-przydzialu-spraw-slps) dowiadujemy się o następujących cechach systemu SLPS:
- napisany jest w języku programowania C#
- działa pod kontrolą systemu Microsoft Windows Server i usługi Microsoft Internet Information Server
- korzysta z silnika bazodanowego Microsoft SQL Server
- jest zintegrowany z usługą katalogową Active Directory, służącą do weryfikacji użytkowników oraz ich uprawnień w systemie
- jest chroniony przed nieuprawnionym dostępem na poziomie sieciowym – wczytanie zawartości strony slps.ms.gov.pl jest możliwe tylko ze stacji roboczej pracującej w sieci sądowej MS-WAN
Dowiadujemy się też, że System Kadrowo-Finansowy ZSRK oraz inne systemy sądowe (jak Currenda/SAWA albo Sędzia-2) są odrębnymi bytami i nie wchodzą w skład SLPS.
Dlaczego w kodzie źródłowym nie ma sekretów
Podczas budowy systemów informatycznych stosowana jest zasada najmniejszego uprzywilejowania, zgodnie z którą każda osoba ma dostęp tylko do tych informacji i zasobów, które są niezbędne do spełnienia wyznaczonego mu celu lub zadania.
Programiści nie uczestniczą we wdrażaniu oraz utrzymaniu systemu, więc nie powinni znać hasła do produkcyjnej bazy danych. W kodzie źródłowym nie znajdziemy więc linii:
var HasloDoBazy = "Qwerty123!"
tylko coś w rodzaju
var HasloDoBazy = PobierzZmiennąŚrodowiskową("haslo")
Administrator umieści wówczas hasło w tzw. zmiennej środowiskowej, do której dostęp mają tylko uprawnieni operatorzy serwera
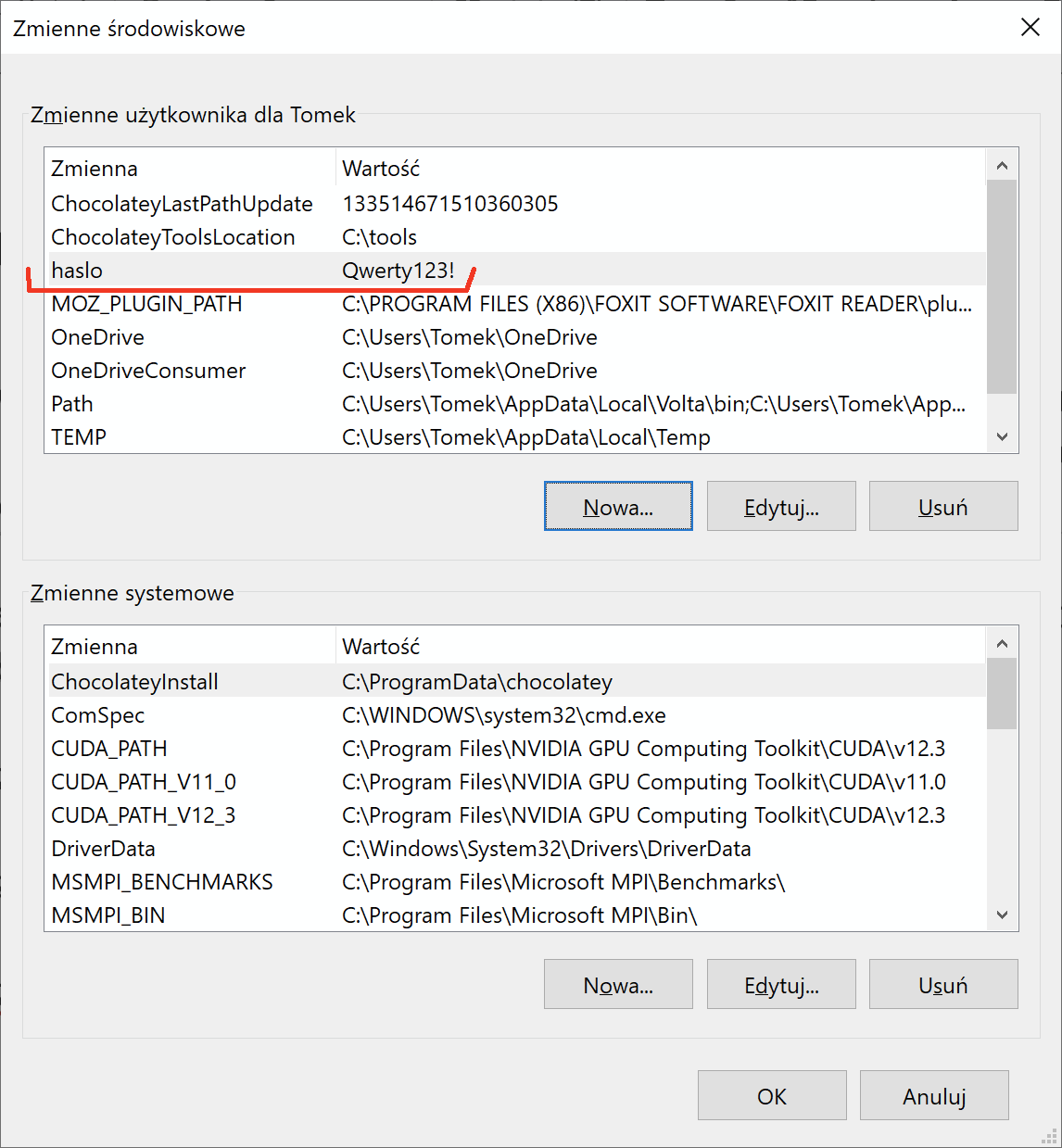
W wielu systemach stosuje się rozwiązania bardziej zaawansowane, niż zmienna środowiskowa, by hasło jeszcze lepiej chronić przed niezamierzonym ujawnieniem.
Warstwowa budowa zabezpieczeń
W uzasadnieniu odmowy czytamy na str. 19: „Dostęp do kodu źródłowego w połączeniu ze znajomością algorytmu SLPS […] umożliwiłby niekontrolowane zdalne wejścia do tego programu bez konieczności dostępu do infrastruktury SLPS”. Dalej: „Potencjalny cyberatak, przy znajomości kodu źródłowego, umożliwiłby ingerowanie w SLPS, łącznie z wprowadzaniem zmian w programie, jego zablokowanie i zakłócenie pracy sądów […]”.
W mojej opinii stanowisko takie jest błędne. Bezpieczeństwo systemów informatycznych jest konstruowane w oparciu o kolejne warstwy zabezpieczeń, które działają w sposób niezależny i wzmacniają wzajemnie swoją skuteczność. Zabezpieczenia takie mogłyby wyglądać następująco:
- warstwa 1 – dostęp do systemu SLPS (adresu slps.ms.gov.pl) możliwy jest tylko z wewnątrz sieci sądowej MS-WAN. Znajomość kodu źródłowego SLPS niczego nie zmienia.
- warstwa 2 – uwierzytelnienie Active Directory. Nie wystarczy fizyczny dostęp do gniazdka sieciowego w budynku Ministerstwa, zalogowanie do SLPS wymaga znajomości nazwy i hasła użytkownika z nadaną odpowiednią rolą. Ochronę można wzmocnić drugim składnikiem uwierzytelniania, np. kluczem sprzętowym. Znajomość kodu źródłowego SLPS niczego nie zmienia.
- warstwa 3 – WAF czyli firewall aplikacyjny kontrolujący komunikację między przeglądarką a serwerem webowym SLPS i blokujący żądania, które nie pasują do znanych wzorców. Znajomość kodu źródłowego SLPS nie pomaga pokonać WAF-a.
A mówimy tu dopiero o nieuprawnionym dostępie do interfejsu webowego! Aby móc „wprowadzić zmiany w programie”, konieczne byłoby uzyskanie dostępu do serwera i eskalacja uprawnień do poziomu pozwalającego na modyfikację plików – to kolejne warstwy zabezpieczeń.
SLPS nie przetwarza danych milionów obywateli
W uzasadnieniu czytamy: „zasadność ujawnienia kodu źródłowego programu SLPS w przestrzeni publicznej […] jawi się jako wątpliwa jeśli się zwróci uwagę na wskazane przez organ zagrożenia związane z możliwością ujawnienia danych milionów obywateli”.
Z dokumentów opisujących działanie SLPS wiemy, że SLPS nie przetwarza ani danych osobowych stron postępowań, ani dziesiątek tysięcy pracowników sądów. Nie ma tam też danych prokuratorów, świadków ani biegłych. W bazie SLPS możemy znaleźć jedynie dane sędziów i referendarzy, które i tak ujawniane są każdego dnia na stronach elektronicznej wokandy.
Argument, że po ataku na SLPS intruz spenetruje ZSRK, Księgi Wieczyste i Bazę PESEL, powinien nas przerażać z innego powodu – dowodziłoby to katastrofalnych zaniedbań i złamania wszystkich dobrych praktyk dotyczących izolacji systemów informatycznych. Paradoksalnie – kod źródłowy SLPS nie byłby pomocny w takim ataku, bo SLPS integruje się wprost jedynie z ZSRK a i to tylko w zakresie pobierania słownika sędziów i informacji o nieobecnościach.
Idąc tym tokiem rozumowania: obywatelom należy odmawiać wszelkiej informacji publicznej, skoro kserując dokument ryzykujemy, że na odwrocie kartki znajdą się dane osobowe, finansowe i medyczne dziesiątek lub setek obywateli. Skąd? Nie wiadomo. Jak? Nie wiadomo. Ale ryzyko istnieje, bo przecież państwo ma te dane.
Nota bene – kuriozalne jest odmawianie dostępu z powołaniem na argument, że w planach rozwoju SLPS znajduje się integracja z systemami repertoryjno-biurowymi. Może zamiast tego założyć, że kod modułów integracyjnych zostanie ujawniony i dlatego należy realizować obecne i przyszłe integracje zgodnie z zasadami sztuki? Powołanie na stopień alarmowy CHARLIE-CRP budzi z kolei lekkie rozbawienie, bo oprogramowanie nie robi się od tego ani bardziej, ani mniej bezpieczne.
Co stanie się, gdy przypadkowy odbiorca uruchomi u siebie kopię SLPS
Przyjmijmy, że przypadkowy człowiek uzyskał dostęp do kompletnego kodu źródłowego SLPS i zamierza uruchomić go na swoim komputerze. Jakie ryzyka się z tym wiążą? Zgoła żadne.
Człowiek taki będzie w stanie przetworzyć źródła w program komputerowy, zainstalować go na swojej maszynie, powiązać z własną usługą katalogową Active Directory oraz nadać dostęp do własnej bazy danych SQL Server. Następnie będzie w stanie… pobawić się w sekretariat sądu. O ile oczywiście sam wklepie w swój system wszystkie dane niezbędne do tego, by udawać choć jeden wydział jednego sądu.
Kod źródłowy nie zawiera kopii danych! Taka domowa instalacja nie będzie więc zawierać listy sądów, wydziałów, nie będzie tam sędziów ani referendarzy. Nie będzie się też dało wczytać tych danych z ZSRK – po pierwsze kod źródłowy nie zawiera haseł dostępowych, po drugie zaś integracje tego typu często oparte są o obustronne uwierzytelnianie. A „domowy SLPS” nie będzie w stanie udawać wersji z ministerstwa, nie jest włączony w strukturę usług katalogowych sieci MS-WAN.
Te zagadnienia są trudne
Sąd pisze: „nieautoryzowana przy użyciu kodu źródłowego ingerencja w program SLPS narażałaby poufność danych osobowych zawartych w tym programie”. Te słowa nie mają sensu. Wiem, że dla osób niezwiązanych z tworzeniem oprogramowania występujące tu pojęcia są nieintuicyjne i trudne do ogarnięcia, ale to jednak część wyroku wydanego w imieniu Rzeczypospolitej Polskiej i część ta nie niesie żadnego znaczenia.
Absurdalne jest twierdzenie, jakoby niedopuszczalna była sytuacja, w której organy państwa nie są w stanie zagwarantować autentyczności, bezpieczeństwa i rzetelności programu, który służy celom publicznym. Przywołajmy przykład rządowej aplikacji STOP COVID, która służyła celom publicznym i której kod źródłowy jest dostępny publicznie.
Każdy może pobrać źródła tej aplikacji, dokonać dowolnych zmian i instalować ją na swoich urządzeniach (lub namawiać inne osoby do tego samego). Mimo tego nikt nie będzie w stanie podmienić oficjalnej, rządowej wersji dostępnej w sklepie z aplikacjami, bo czym innym jest przekształcenie zmodyfikowanych źródeł w aplikację, czym innym uruchomienie tej aplikacji, a jeszcze czym innym jej dystrybucja bądź uruchomienie na cudzej, chronionej infrastrukturze.
Sąd przyjął jako prawdę z gruntu fałszywe twierdzenie, jakoby samodzielna modyfikacja ujawnionych źródeł na komputerze obywatela mogła doprowadzić do „zdalnego wejścia do tego programu”. Twierdzenie podmiotu, że poczynione na prywatnym komputerze „modyfikacje mogłyby […] wpłynąć na przebieg konkretnych losowań” to już absurd do kwadratu. Mam nieodparte wrażenie, że organ wielokrotnie używał groźnie brzmiącego technobełkotu, by skonfundować i przestraszyć sąd, i że cel ten został niestety osiągnięty.
Błędy SLPS są faktem
System Losowego Przydziału Spraw to program zawierający błędy, które nie są poprawiane latami. Spójrzmy na sprawę I Ns 436/24 z Sądu Rejonowego w Biłgoraju – sprawę wylosował sędzia o wskaźniku obciążenia równym -2147483486,26. To oznacza, że ma on zaległości przekraczające dwa miliardy sto siedemdziesiąt cztery miliony spraw! Podobne wartości można zobaczyć np. w SR w Nowym Sączu, sprawa I Nc 2229/23, i dziesiątkach innych.
Ten spektakularny błąd powinien być wychwycony na etapie testów, a gdy ujawniono go na systemie produkcyjnym, powinien zostać natychmiast załatany. Widzimy tymczasem, że wskaźniki tego typu występują w losowaniach oddalonych o długie miesiące.
W artykule You had one job ujawniłem, że przez ponad rok niektóre losowania były przeprowadzane błędnie – losowana pula sędziów zawsze miała cztery pozycje także w przypadkach, gdy zgodnie z algorytmem (oraz Regulaminem Sądów Powszechnych) do puli powinno trafić 5-10 wpisów.
W takiej sytuacji na żart zakrawa deklaracja, że SLPS jest transparentny. W rzeczywistości system ten jest czarną skrzynką, zaś wgląd w źródła pozwoliłby zidentyfikować źródło tych i innych błędów wpływających na wynik losowań.
W publikacji Śmieci na wejściu umieściłem przykłady raportów z błędnym kosztem sprawy, raporty bez numeru wydziału w sygnaturze, raporty ze sprawami o numerze zero a w tekście Jak SLPS wylicza wskaźniki obciążenia także przykład sprzeczności w dokumentacji opisującej projektowane działanie systemu.
Skoro nawet na podstawie dokumentacji nie da się zrozumieć realizowanego algorytmu, to możliwość wglądu w źródła SLPS jest nie tylko uzasadniona, ale wręcz konieczna.
Kod źródłowy jako czynnik ułatwiający atak
Jedynym argumentem organu wartym uwagi jest twierdzenie, że znajomość kodu źródłowego ułatwia poszukiwanie podatności systemu i przeprowadzenie ataku mającego na celu manipulowanie działaniem SLPS. Nie jest to teza pozbawiona podstaw.
Aby rozważyć zasadność tego argumentu, należy ponownie przywołać wiedzę o warstwowej budowie systemu zabezpieczeń. Większość modułów SLPS działa w chronionym środowisku – moduł losowań komunikuje się jedynie z zaufaną bazą danych, dostęp do interfejsu dla pracowników chroniony jest wymogiem korzystania z zaufanej sieci. Jedynym mechanizmem wystawiającym dane „na zewnątrz” jest wyszukiwarka raportów w portalu sądowym i na stronach Ministerstwa, choć nie wiadomo, czy mechanizm ten jest częścią samego SLPS.
Organ nie wspomniał, że ryzyku towarzyszą także korzyści wynikające z inspekcji źródeł przez hobbystów i pasjonatów bezpieczeństwa. Wielu z nich jest gotowych nie tylko wskazać dostrzeżone usterki, ale zaangażować się w ich usunięcie i weryfikację poprawek. Gdyby jednak miało okazać się, że wybrane fragmenty kodu źródłowego stanowią istotne ryzyko, to…
Źródła można podzielić i „zanonimizować”
Kod źródłowy programu komputerowego nie jest jedną, niepodzielną całością. To zestaw plików tekstowych wyglądających jak na pierwszej ilustracji na początku tekstu. Gdyby program napisano wbrew dobrym praktykom i w kodzie źródłowym faktycznie znalazły się jakieś sekrety – wystarczy je usunąć.
Serio. Gdy w kodzie znajdują się hasła, należy je skasować i przekazać kopie bez haseł. Gdy usuniemy fragment tekstu z pliku tekstowego i skopiujemy plik na nośnik albo prześlemy przez sieć, nie ma żadnego sposobu na odtworzenie wymazanej informacji. Odbiorca „wyczyszczonej” kopii nie pozna haseł, których nie ma w jego kopii.
Gdyby okazało się, że już sam sposób realizacji pewnej funkcji programu zdradza informacje mogące obniżać bezpieczeństwo systemów, to można usunąć fragmenty kodu źródłowego realizujące tę funkcję. Programiści organizują pliki kodu źródłowego w katalogi, aby pliki realizujące daną funkcję stanowiły wydzielony moduł. W takiej sytuacji należałoby usunąć jedynie wybrane pliki a resztę źródeł udostępnić zgodnie z wnioskiem.
Opisane operacje można uznać za odpowiednik zaczerniania fragmentów dokumentu stanowiącego informację publiczną. Jeśli w dokumencie takim znajdą się przypadkowo dane osób trzecich, to nie jest to podstawą do odmowy dostępu. Oznacza to jedynie, że dane takie należy zanonimizować.
Kod źródłowy jako własność i tajemnica
W swojej argumentacji organ wskazał, że kod źródłowy oprogramowania bywa chroniony jako tajemnica przedsiębiorstwa. Cóż, Ministerstwo Sprawiedliwości przedsiębiorstwem nie jest, a system SLPS nie daje organowi publicznemu żadnej przewagi konkurencyjnej – tak w kraju jak i za granicą.
Organ wspomniał, że system SLPS składa się z 3 milionów linii kodu. Zapomniał jednak dodać, że – pozwolę sobie na spekulację – 90% tego kodu należy do kategorii wolnego i otwartego oprogramowania. Są to pomocnicze biblioteki programistyczne, które można swobodnie wykorzystywać do dowolnych celów.
W dokumentach przetargowych zamówienia publicznego na utrzymanie i rozwój SLPS czytamy, że system ten jest zbudowany w oparciu o komponenty: Automapper, CsvHelper, Dapper, FluentAssertions, FluentValidation, JQuery, log4net, Moq, NUnit, bootstrap, jspdf i wiele innych. Łącznie wymieniono tam aż 98 różnych bibliotek.
Dość powiedzieć, że pochodzące z zewnątrz komponenty odpowiadają za kluczowe funkcje, czyli zapis/odczyt plików z danymi (CsvHelper), zapis informacji w bazie danych (EntityFramework), uwierzytelnianie użytkowników (Microsoft.AspNet.Identity.Core) czy generowanie plików PDF z raportami (iTextSharp). Czytelnik może ocenić, jak użycie niemal setki komponentów o otwartym kodzie ma się do rzekomo katastroficznych konsekwencji ujawnienia kodu źródłowego samego SLPS.
Podsumowanie
Organ pisze: „dostęp […] oznacza możliwość”, „wejście […] potencjalnie nie zostałoby powstrzymane”, „podmiot zewnętrzny mógłby w sposób nieograniczony zmieniać kod”, „modyfikacje mogłyby objąć obszar […] a zatem wpłynąć na przebieg”, „udostępnienie może doprowadzić do skutecznego cyberataku na SLPS”, „potencjalne ułatwienie zrozumienia kodu […] oznacza możliwość wprowadzenia zmian w programie”, „potencjalna identyfikacja podatności […] może prowadzić do […] wprowadzenia złośliwego kodu”, „atakujący mogliby podjąć próbę”, „opisane zagrożenia mogą dotyczyć także kolejnych olbrzymich baz danych”, „potencjalny atak jest tym bardziej realny”.
W takim zestawieniu widać powtarzający się schemat – warunkowe postawienie tezy o istnieniu wysokiego zagrożenia, brak oszacowania ryzyka zaistnienia szkody oraz przyjęcie dramatycznego scenariusza wynikowego, który często nie łączy się z zagrożeniem związkiem przyczynowo-skutkowym.
Chybione jest porównanie infrastruktury informatycznej Ministerstwa Sprawiedliwości do budynku oraz paralela między przeniknięciem do sieci wewnętrznej a ułatwionym dostępem do wszystkich pomieszczeń. Trafniejsze będzie raczej porównanie do twierdzy obronnej, gdzie bunkry i forty (aplikacje) stanowią samodzielne umocnienia, transzeje (sieć) są monitorowane przez obrońców zaś koncentryczne fortyfikacje (warstwy zabezpieczeń) wykluczają zdobycie całej twierdzy (infrastruktury) udanym atakiem na zewnętrzny bastion (zasoby wystawione do internetu).
Wisienką na tym atomowym torcie jest teza: „Udostępnienie kodu źródłowego SLPS oznacza zatem realny i najwyższy stopień zagrożenia infrastruktury teleinformatycznej resortu sprawiedliwości i państwa”. W kreskówce słowom tym towarzyszyłaby błyskawica i demoniczny śmiech antagonisty.
Rozczarowaniem jest jedynie, że sąd bezkrytycznie przyjął całość argumentacji obliczonej na budowę atmosfery strachu i niepewności. Zasługujemy na to, aby argumenty za i przeciw udostępnieniu kodu źródłowego SLPS zostały zważone z uwzględnieniem ich rzeczywistej wartości merytorycznej.
Artykuł objęty jest licencją Creative Commons CC BY 4.0 (uznanie autorstwa).
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

2 odpowiedzi na “Realny i najwyższy stopień zagrożenia”
Jest jeszcze NSA..
[…] Dlatego nie ustawaliśmy w wysiłkach, by ten kod ujawniono. Po zmianie władzy, w 2024 roku wspólnie z innymi organizacjami zaapelowaliśmy o to do ministra Adama Bodnara. Niestety kod wciąż nie został udostępniony. Zapytaliśmy także o to ministra Waldemara Żurka podczas spotkania w listopadzie 2025 roku z organizacjami społecznymi. Odpowiedział nam wtedy, że jego zdaniem zapisy w umowie dotyczące praw autorskich uniemożliwiają publikację kodu. W podobnym tonie minister wypowiadał się na marcowym spotkaniu z mieszkańcami Piaseczna. Jedna z naszych członkiń zapytała, dlaczego wciąż nie ujawniono kodu źródłowego Systemu Losowego Przydziału Spraw. W odpowiedzi usłyszała, że według informatyków obsługujących projekt ujawnienie kodu może być ujawnieniem tajemnicy firmy, która go stworzyła, a także może stwarzyć ryzyko ingerencji z zewnątrz w ten system. Eksperci mówią jednak coś innego. Tomasz Zieliński prowadzący portal https://informatykzakladowy.pl/ uważa, że argument o „zagrożeniu” jest w dużej mierze mitem. Ujawnienie kodu nie daje dostępu do systemu, a wręcz przeciwnie: zwiększa możliwość kontroli i bezpieczeństwo, bo pozwala go niezależnie zweryfikować (Realny i najwyższy stopień zagrożenia). […]