
Systemowi Losowego Przydziału Spraw poświęciłem kilka krytycznych tekstów, miło dla odmiany napisać coś pozytywnego. W Portalu Informacyjnym Sądów Powszechnych pojawiła się „Wyszukiwarka raportów z SLPS” której jeszcze kilka dni temu na pewno tam nie było. Czyżbyśmy wreszcie mieli nieskrępowany dostęp do raportów z wszystkich losowań? Byłoby to świetną wiadomością – każdy chętny mógłby sprawdzić, czy nie pojawiają się tam jakieś nieprawidłowości.
Niestety, Ministerstwo Sprawiedliwości wdrożyło w wyszukiwarce mechanizm utrudniający zautomatyzowane pobranie kompletu raportów. Co gorsza, rolę tę pełni reCAPTCHA od Google, co oznacza tak naprawdę, że polski obywatel pragnący pobrać dokument wytworzony przez polskie ministerstwo a przechowywany na serwerze w Polsce, musi poprosić o taką możliwość… amerykańską megakorporację.
Wcześniejsze teksty o Systemie Losowego Przydziału Spraw
[2020-12-14] System Pseudolosowego Przydziału Spraw – opisałem problemy z SLPS i objaśniłem, dlaczego celowe błędy wpływające na działanie generatora liczb pseudolosowych mogą wyglądać tak, jak staranny kod niekompetentnego programisty
[2021-05-02] NIK o SLPS: Nie osiągnięto celów całego przedsięwzięcia – zestaw cytatów na temat SLPS z raportu Najwyższej Izby Kontroli
[2021-07-30] O algorytmach dla prawników – objaśniam krok po kroku, czym algorytm różni się od programu komputerowego i dlaczego bez dostępu do kodu źródłowego nie będziemy wiedzieć, czy pozornie poprawny program nie zawiera błędów
[2021-10-03] Poznaliśmy algorytm losowania SLPS czyli… co dokładnie? – oceniam, jaką wartość ma dokument udostępniony przez Ministerstwo Sprawiedliwości
[2022-01-14] Przejrzystość SLPS – duży krok do przodu – na stronach Portalu Sądowego pojawiła się wyszukiwarka raportów z losowań – niestety zabezpieczona mechanizmem reCAPTCHA
[od kwietnia 2024] Monitor SLPS – wpisy w serwisie slps.pl
[2025-01-09] Realny i najwyższy stopień zagrożenia – opinia do wyroku WSA oddalającego skargę na odmowę udostępnienia kodu źródłowego SLPS
Wielki brat czuwa
Wyobraźmy sobie następującą scenę rozgrywającą się gdzieś w Polsce przed bramą sądu:
— Доброе утро. Dokąd to? Do sekretariatu sądu?
— Chwila, kim pan jest?
— Jestem obcokrajowcem wydającym przepustki. Tak jesteśmy umówieni z sądem. Nikogo nie szpieguję. Proszę zapisać na tej kartce swój wiek, kod pocztowy, posiadany model telefonu i zainteresowania. Czy to „Wiadomości wędkarskie”, tu w tej reklamówce?
— Obcokrajowcem? Umówionym z sądem? To tak można? A jak ktoś się dowie?
— Pan się właśnie dowiedział, i co? Poproszę dane albo spadówa.
— No cóż, muszę do środka, oto moje dane: [————————–]
— Хорошо, спасибо. Oto pańska przepustka. Następny! Pan dokąd, też sekretariat?
Śmieszne, oburzające, absurdalne, niedorzeczne? No to teraz popatrzmy na obrazki:
1.
Wchodzimy na stronę Portalu Informacyjnego Sądów Powszechnych. Klawiszem F12 włączamy narzędzia deweloperskie, otwieramy zakładkę „Sieć”.
2.
Klikamy po lewej stronie pozycję „Raporty z SLPS”. Widzimy, że portal ładuje komponent reCAPTCHA wprost z serwerów Google.
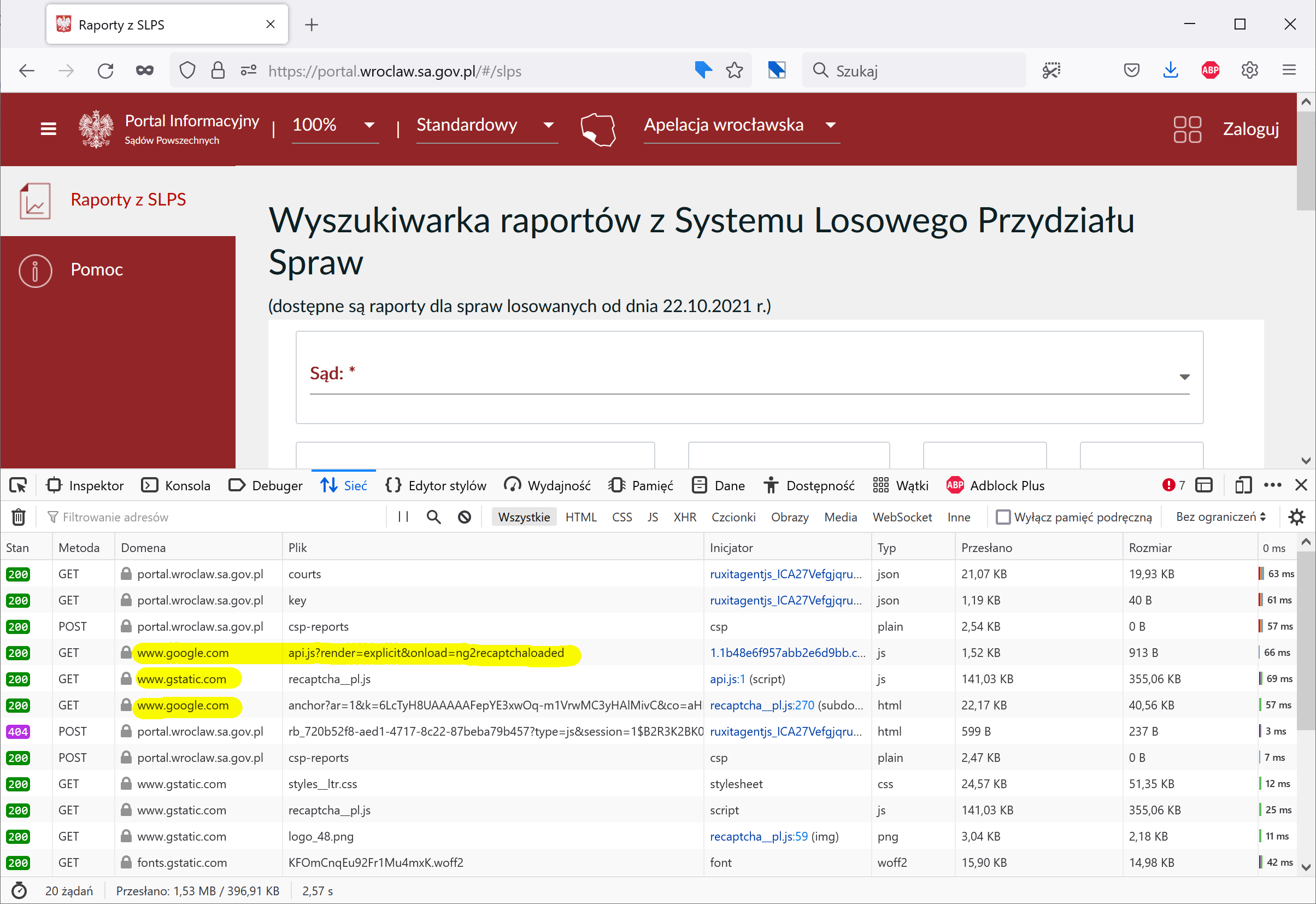
3.
Aby nie było wątpliwości – w internet wysyłane są dane o bieżącej stronie, informacje o języku, przeglądarce, numerze IP i tak dalej. W drugim okienku mam otwartego Gmaila, więc Google może w ciemno zakładać, że to właśnie ja otworzyłem wyszukiwarkę raportów SLPS.
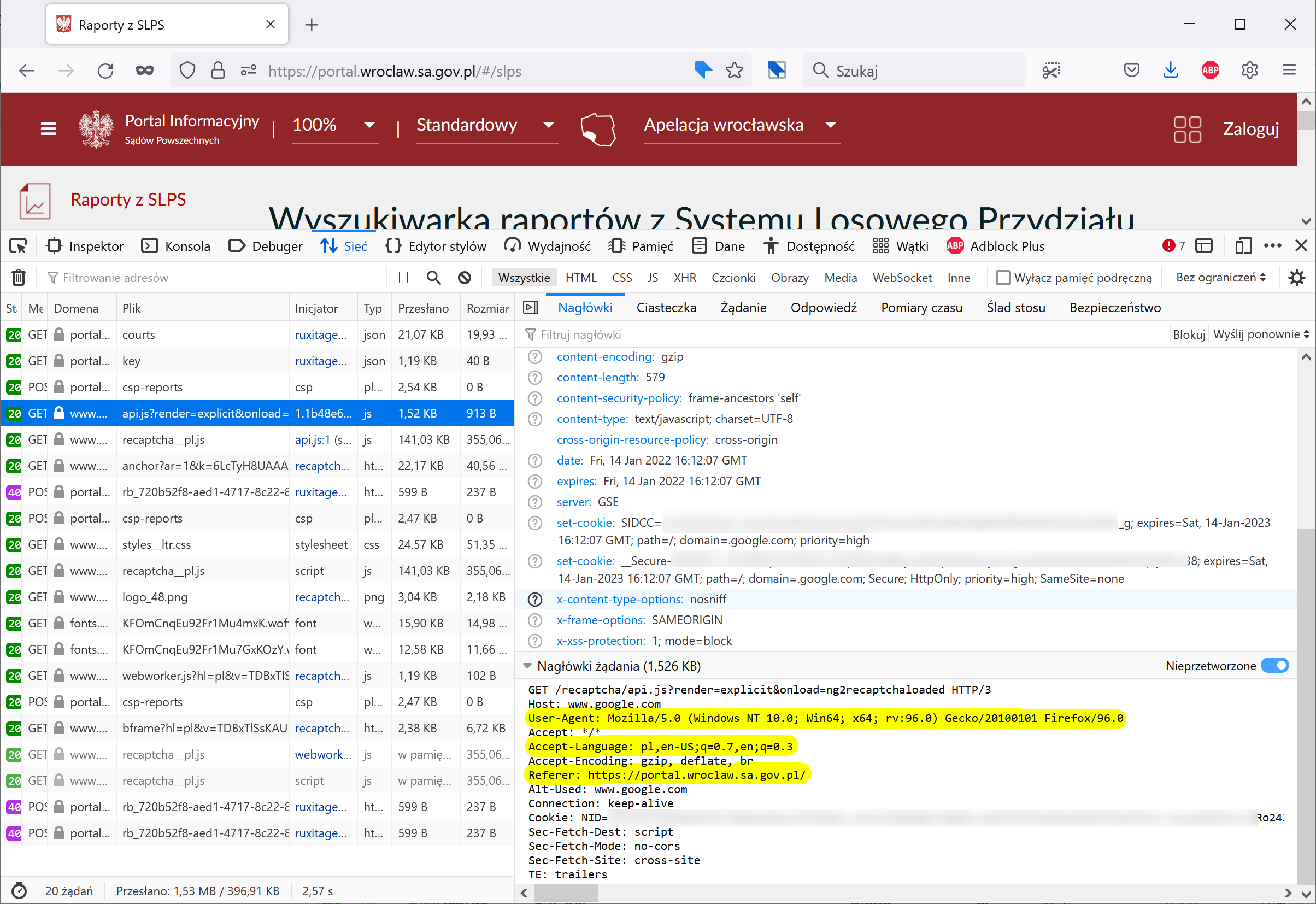
4.
Serwis przygotowany przez polski rząd nie pozwala mi na pobranie żądanego dokumentu. Muszę dodatkowo poprosić o zgodę amerykańską megakorporację.

5.
Klikam reCAPTCHĘ. Dotyczące mnie zapisy w amerykańskim megakorpo są w porządku, nie muszę rozwiązywać obrazkowej łamigłówki by dowieść, że nie jestem automatem. Google daje Ministerstwu Sprawiedliwości zielone światło, można wysłać mi dokument.
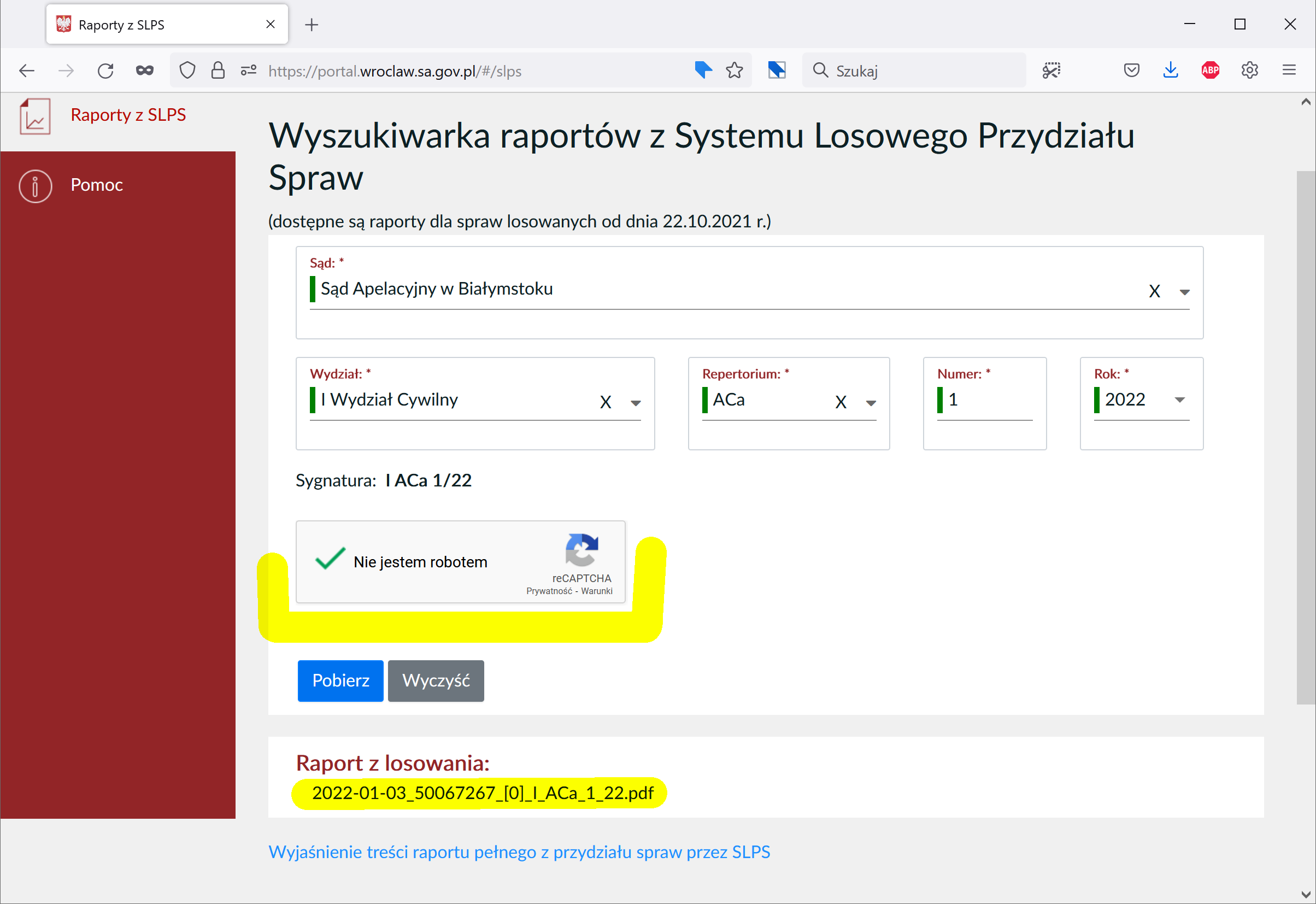
Teraz zadajcie sobie pytanie – czy dialog opisany na początku jest RZECZYWIŚCIE czymś innym, niż kliknięcie ramki „Nie jestem robotem” obsługiwanej przez Google? Nie wiem, jak Wy, ale ja jestem oburzony. Jako polski obywatel oczekuję, że moje państwo będzie mnie szanować, tymczasem nie dość, że moje dane wędrują za ocean, to co jakiś czas będę musiał rozwiązać graficzną łamigłówkę której rezultat Google użyje do trenowania algorytmów rozpoznawania obrazu.
Czy to zabezpieczenie da się ominąć?
Choć każdy protokół losowania ma swój unikalny liczbowy identyfikator, to nie da się go wpisać w parametrach wyszukiwania – trzeba obowiązkowo podać sąd, wydział, repertorium oraz numer sprawy. Czemu takie filtry? Nie ma wątpliwości, że chodzi o utrudnienie pobierania wszystkich losowań dotyczących danego sędziego, wydziału czy sądu. Po co utrudniać automatyzację pobierania?
Cóż, w jednym z poprzednich tekstów opisywałem, że choć sama tylko lektura kompletu protokołów nie da pewności, iż losowania są uczciwe, to odnalezienie niespójności w serii protokołów dowodziłoby błędów lub manipulacji. Trzeba pamiętać, że SLPS jest systemem scentralizowanym i jest w całości kontrolowany przez Ministerstwo Sprawiedliwości. Zewnętrzny obserwator nie jest w stanie zrobić wiele więcej, niż poszukiwać nieprawidłowości w danych wystawianych „poza system”. Z jakiegoś powodu ministerstwo chce to utrudnić lub uniemożliwić.
Czy taki mechanizm pobierania da się oszukać? Ominąć filtry i reCAPTCHę, by pobrać wszystkie udostępnione protokoły? Oto przykładowy cennik usługi polegającej na pośrednictwie w rozwiązywaniu różnych typów captchy – wersja druga kosztuje do dwóch dolarów za tysiąc sztuk, dostawca deklaruje krótki czas reakcji i dużą przepustowość.

Czy to drogo? Zależy od kontekstu. Spójrzmy na statystyki bliskiego memu sercu pionu cywilnego Sądu Okręgowego we Wrocławiu. W pierwszym półroczu 2021 wpłynęło tam 4650 spraw w I instancji oraz 3337 w II instancji co razem daje niemal osiem tysięcy nowych spraw do losowania składów. Pozyskanie wszystkich protokołów kosztowałoby 50-60 zł.
Co roku do polskich sądów wpływa jednak kilkanaście milionów spraw. To nie jest mało. Scrapowanie rocznego urobku protokołów z losowań SLPS trwałoby wiele dni i kosztowałoby górne kilkadziesiąt tysięcy zł – nawet po uwzględnieniu zniżek za zakupy hurtowe. Tymczasem nam te protokoły się po prostu należą, że swobodnie strawestuję klasyka.
Światełko w tunelu
Czy na bazie ustawy o dostępie do informacji publicznej moglibyśmy domagać się od Ministerstwa Sprawiedliwości PDF-ów z protokołami? Na przykład podając zakres losowań o numerach od 10.000.000 do 18.000.000? Nie ma sensu sięgać za głęboko – przez pierwsze kilka (sic!) lat SLPS miał szereg znanych usterek a obciążenia sędziów kilkukrotnie resetowano, więc nie ma sensu poddawać audytowi zbyt starych protokołów.
Jeśli ktoś chce spróbować tej ścieżki, proszę o kontakt, chętnie uzupełnię niniejszy artykuł o kopię takiego wniosku i dalszej korespondencji. Miejmy tylko nadzieję, że ów wniosek zostanie zrealizowany, zanim jawność życia publicznego zostanie przez naszą coraz droższą Partię całkowicie rozmontowana.
Pamiętajmy jednak, że skoro istnieje działająca infrastruktura do generowania i składowania protokołów, to usunięcie reCAPTCHy da się wykonać jednym ruchem. Osobiście życzyłbym nam wszystkim, aby stało się to jak najszybciej. Obecny stan jest dowodem słabości państwa, spowodowanej brakiem wyobraźni projektantów i polityków odpowiedzialnych za rozwój SLPS. Dobrze chociaż, że szkody mają ograniczony zasięg – reCAPTCHA pojawia się jedynie na stronie wyszukiwarki raportów.
Pytania do Ministerstwa Sprawiedliwości
Do Ministerstwa Sprawiedliwości wysłałem wczoraj następujące pytania:
1. Dlaczego wyszukiwarka zabezpieczona jest przed możliwością masowego pobierania raportów z losowań SLPS? Z jakiego powodu dostęp do raportów archiwalnych został ograniczony?
2. Dlaczego do zabezpieczenia przed masowym pobieraniem raportów z losowań SLPS użyto usługi reCAPTCHA oferowanej przez Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Irlandia?
3. Dlaczego REGULAMIN PORTALU INFORMACYJNEGO SĄDÓW POWSZECHNYCH Z OBSZARU APELACJI WROCŁAWSKIEJ nie wspomina ani słowem o zewnętrznych podmiotach przetwarzających dane osobowe użytkowników, w szczególności o Google Ireland Limited, która każdorazowo otrzymuje informacje o osobach otwierających w przeglądarce internetowej Wyszukiwarkę raportów z Systemu Losowego Przydziału Spraw?
4. Czy dostęp do raportów Systemu Losowego Przydziału Spraw zostanie w przewidywalnym czasie udostępniony w postaci API (interfejsu programistycznego), aby dane zawarte w dokumentach PDF mogły być przetwarzane w sposób bardziej cywilizowany, tj. bez konieczności wyciągania danych z dokumentów PDF oraz bez konieczności pokonywania zabezpieczenia reCAPTCHA?
5. Czy dostęp przez API pozwoli na pobranie pełnych informacji o wynikach losowań dokonywanych we wskazanym okresie przez SLPS?
Do chwili publikacji niniejszego tekstu nie otrzymałem na nie odpowiedzi. Gdy tak się stanie, artykuł zostanie zaktualizowany.
[Aktualizacja 25.01.2022]
Po 11 dniach dostałem z Biura Komunikacji i Promocji Ministerstwa Sprawiedliwości następujące odpowiedzi:
1a. Dlaczego wyszukiwarka zabezpieczona jest przed możliwością masowego pobierania raportów z losowań SLPS?
Wyszukiwarka raportów z Systemu Losowego Przydziału Spraw adresowana jest do wszystkich obywateli, w tym uczestników postępowania sądowego, którzy tą drogą mogą uzyskać informację na temat wyników losowania składu orzekającego. Ze względu na konieczność zapewnienia dostępności wyszukiwarki dla szerokiego grona odbiorców, przy jednoczesnym wymogu wydatkowania środków w sposób celowy i oszczędny, system nie przewiduje możliwości masowego pobierania raportów z losowań SLPS. Ponadto przyjęte założenie o precyzyjnym wskazaniu konkretnej sprawy (kryteria wyszukiwawcze) do uzyskania raportu wyklucza w ocenie MS zastosowanie mechanizmu do masowego pobierania raportów z losowań.
1b. Z jakiego powodu dostęp do archiwalnych został ograniczony?
Wymagania tego rozwiązania nie zakładały dostępu do archiwalnych raportów otrzymywanych z Systemu Losowego Przydziału Spraw.
2. Dlaczego do zabezpieczenia przed masowym pobieraniem raportów z losowań SLPS użyto usługi reCAPTCHA oferowanej przez Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Irlandia?
Usługi CAPTCHA służą do zapobiegania wykonywaniu przez zautomatyzowane oprogramowanie (tzw. boty) na stronie internetowej, w tym przypadku wyszukiwarce raportów z Systemu Losowego Przydziału Spraw, czynności będącej w sprzeczności z celem, w jakim wyszukiwarka ta została zaprojektowana. Tym samym zastosowanie usługi CAPTCHA zwiększa dostępność usługi wyszukiwarki raportów z Systemu Losowego Przydziału Spraw dla wszystkich użytkowników Internetu oraz znacznie ogranicza możliwość zablokowania działania usługi przez pojedynczych użytkowników. Spośród dostępnych w chwili wdrożenia wyszukiwarki usług CAPTCHA, w wyniku prac projektowych, wybrano usługę reCAPTCHA ze względu na doświadczenie wykonawcy, ugruntowaną pozycję rynkową i koszty. Nie wykluczamy, że w przyszłości usługa ta zostanie zastąpiona przez usługę własną MS opartą o analizę ruchu sieciowego, tożsamą z używaną obecnie na portalu ekw.ms.gov.pl, służącym wyszukiwaniu Elektronicznych Ksiąg Wieczystych.
3. Dlaczego REGULAMIN PORTALU INFORMACYJNEGO SĄDÓW POWSZECHNYCH Z OBSZARU APELACJI WROCŁAWSKIEJ nie wspomina ani słowem o zewnętrznych podmiotach przetwarzających dane osobowe użytkowników, w szczególności o Google Ireland Limited, która każdorazowo otrzymuje informacje o osobach otwierających w przeglądarce internetowej Wyszukiwarkę raportów z Systemu Losowego Przydziału Spraw?
Usługa wyszukiwarki raportów z Systemu Losowego Przydziału Spraw sądowych dostępna jest na stronach wszystkich jedenastu Portali Informacyjnych Sądów Powszechnych oraz na stronie Ministerstwa Sprawiedliwości. Każdy z użytkowników, przed wypełnieniem formularza i skorzystaniem z usługi, ma możliwość zapoznania się z polityką prywatności jak i warunkami użycia usługi reCAPTCHA (informacja umieszczona pod przyciskiem). Wyszukiwarka raportów z Systemu Losowego Przydziału Spraw jest usługą nową, która podlegać będzie jeszcze modyfikacjom, stąd odpowiednie zapisy, o ile zajdzie taka konieczność, znajdą odzwierciedlenie w Regulaminach Portali Informacyjnych Sądów Powszechnych. Jeżeli użytkownik nie akceptuje polityki prywatności, to nie ma obowiązku z korzystania z usługi.
4. Czy dostęp do raportów Systemu Losowego Przydziału Spraw zostanie w przewidywalnym czasie udostępniony w postaci API (interfejsu programistycznego), aby dane zawarte w dokumentach PDF mogły być przetwarzane w sposób bardziej cywilizowany, tj. bez konieczności wyciągania danych z dokumentów PDF oraz bez konieczności pokonywania zabezpieczenia reCAPTCHA?
Nie planuje się uruchomienia interfejsu programistycznego API umożliwiającego dostęp do raportów Systemu Losowego Przydziału Spraw.
5. Czy dostęp przez API pozwoli na pobranie pełnych informacji o wynikach losowań dokonywanych we wskazanym okresie przez SLPS?
Odpowiedź na to pytanie jest zawarta w pkt. 4.
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

9 odpowiedzi na “Transparentność SLPS – duży krok do przodu, dwa małe kroki w tył [akt.]”
Gdybyś nie dostał odpowiedzi w ustawowym terminie, to też daj znać.
A już po wyroku TSUE w/s „Schrems-2” było oczywiste, że wszystko od Gógla jest do bani…
Dobrze, że o tym piszesz. Dodajmy do tego jeszcze niezliczoną ilość zabudowanych Map Google na stronie „kontakt” niezliczonej ilości urzędów i instytucji.
„Serwis przygotowany przez polski rząd nie pozwala mi na pobranie żądanego dokumentu. Muszę dodatkowo poprosić o zgodę amerykańską megakorporację…”
…korzystając z amerykańskiej przeglądarki, łącząc się z użyciem amerykańskich serwerów DNS, z pomocą urządzeń produkcji….” itd. xD
PS. Sorry, nie mogłem się powstrzymać przed tym kąśliwym komentarzem, ale na poważnie: szacunek za serię artykułów o SLPS i w ogóle całego bloga!
„…korzystając z amerykańskiej przeglądarki, łącząc się z użyciem amerykańskich serwerów DNS, z pomocą urządzeń produkcji….” itd. xD”
DNS spokojnie mógł zmienić, przeglądarkę przejrzeć (bo FF), urządzenia też (nie wiemy, z czego korzysta). I robi to świadomie, z własnej decyzji.
Natomiast na SLPS to nie on wymusza reCAPTCHA – jest różnica.
Najpierw: „Wyszukiwarka raportów z Systemu Losowego Przydziału Spraw adresowana jest do wszystkich obywateli” i „Ze względu na konieczność zapewnienia dostępności wyszukiwarki dla szerokiego grona odbiorców”
Potem: „Jeżeli użytkownik nie akceptuje polityki prywatności, to nie ma obowiązku z korzystania z usługi.”
Czy tylko ja dostrzegam tu konflikt? Zadałbym pytanie: „Czy obywatel dbający o swoją prywatność, jest obywatelem drugiej kategorii i ma być pozbawiony łatwego dostępu do informacji?”
„Czy obywatel dbający o swoją prywatność, jest obywatelem drugiej kategorii i ma być pozbawiony łatwego dostępu do informacji?”
Myślę, że odpowiedź znamy już od lat – spójrz na wszystkie urzędy publikujące tylko na FB.
😀
Ministerstwo Sprawiedliwości stosuje reCAPTCHĘ sprzecznie z RODO?
WTF!?
Poszedł bym dalej! Polski obywatel musi w tym celu skorzystać z libc, procesora produkowanego na tajwanie i systemu operacyjnego z ameryki. Serio wierzycie w cyber-suwerenność czy coś? Przecież oni nie wiedzą co mówią to trzeba wtedy stworzyć nawet własne języki programowania