
Do pisania tego tekstu siadam czerwony ze wstydu. Musiałem trochę powalczyć sam ze sobą, by napisać to publicznie: w ciągu minionych trzech miesięcy nie powstał ani jeden kompletny backup bloga Informatyk Zakładowy. Wstyd jest o tyle większy, że przecież rok temu opublikowałem trzyczęściowy cykl artykułów poświęconych tworzeniu kopii bezpieczeństwa (że o darmowym e-booku nie wspomnę), więc sam powinienem mieć wszystko zapięte na ostatni guzik, prawda? Aha…
W niniejszym tekście opisuję awarię mechanizmu tworzącego codzienny backup bloga oraz przyczyny, dla których nie dostrzegłem jej przez wiele miesięcy. Aby rozwiać wątpliwości – nie utraciłem danych. Wszystko wyszło na jaw, gdy wziąłem się za zupełnie inny temat. Planowałem opisać, ile czasu zajmie mi odtworzenie bloga od zera z wczorajszej kopii zapasowej. Zalogowałem się więc do AWS, by ją pobrać i wtedy…
Kopie zapasowe bloga wysyłane są do chmury Amazona, do kubełka S3. Oto, jak wyglądała lista plików tam obecnych:
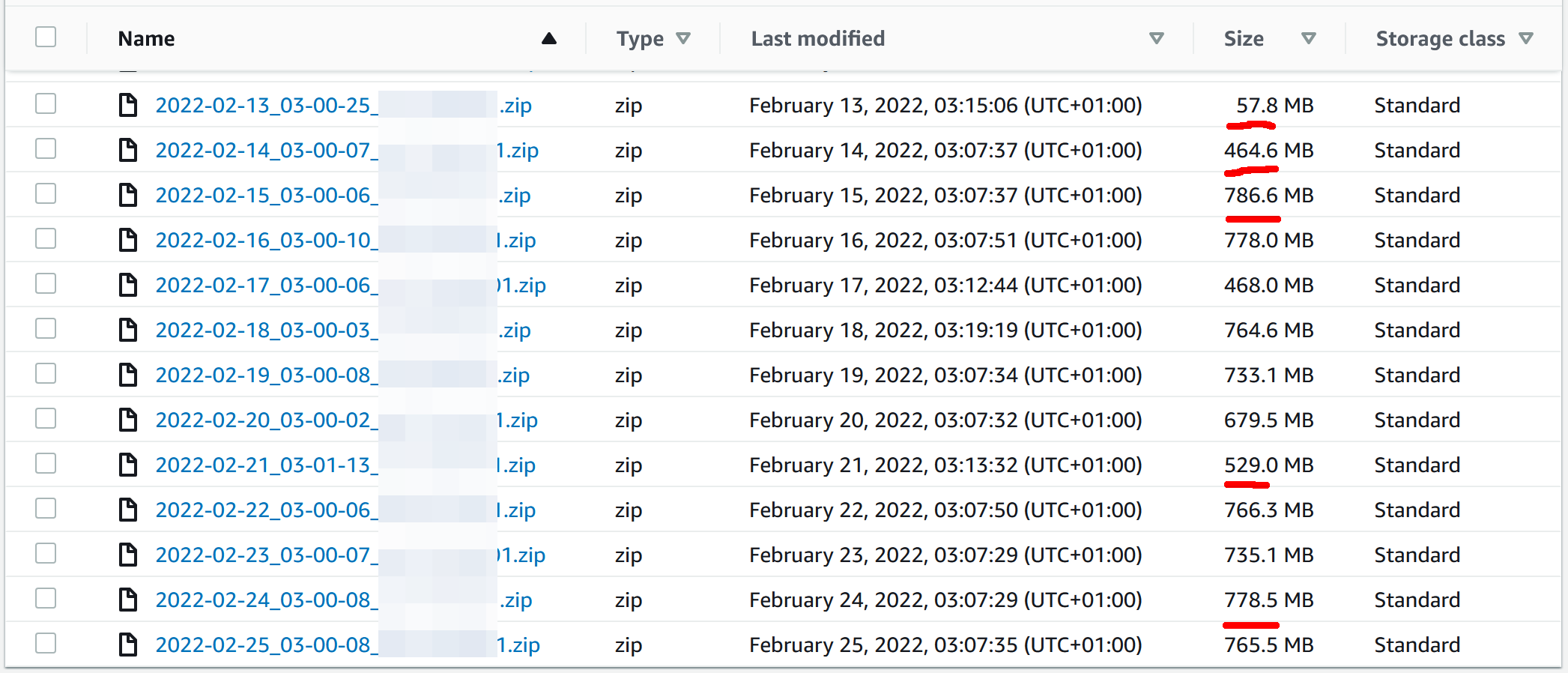
Już na pierwszy rzut oka coś było nie tak. Choć backup robił się co noc, to jego rozmiar każdego dnia był inny – 778 MB, 464 MB a nawet marne 57 MB! Największy plik miał 984 MB i pochodził z końcówki 2021 roku. Kubełek na backupy trzyma pliki z ostatnich 90 dni, opisana usterka obejmowała cały ten okres. Czy miałem choć jeden sprawny backup?
Aby to sprawdzić, zalogowałem się do panelu administracyjnego WordPressa i sprawdziłem logi ostatnio wykonywanego zadania:
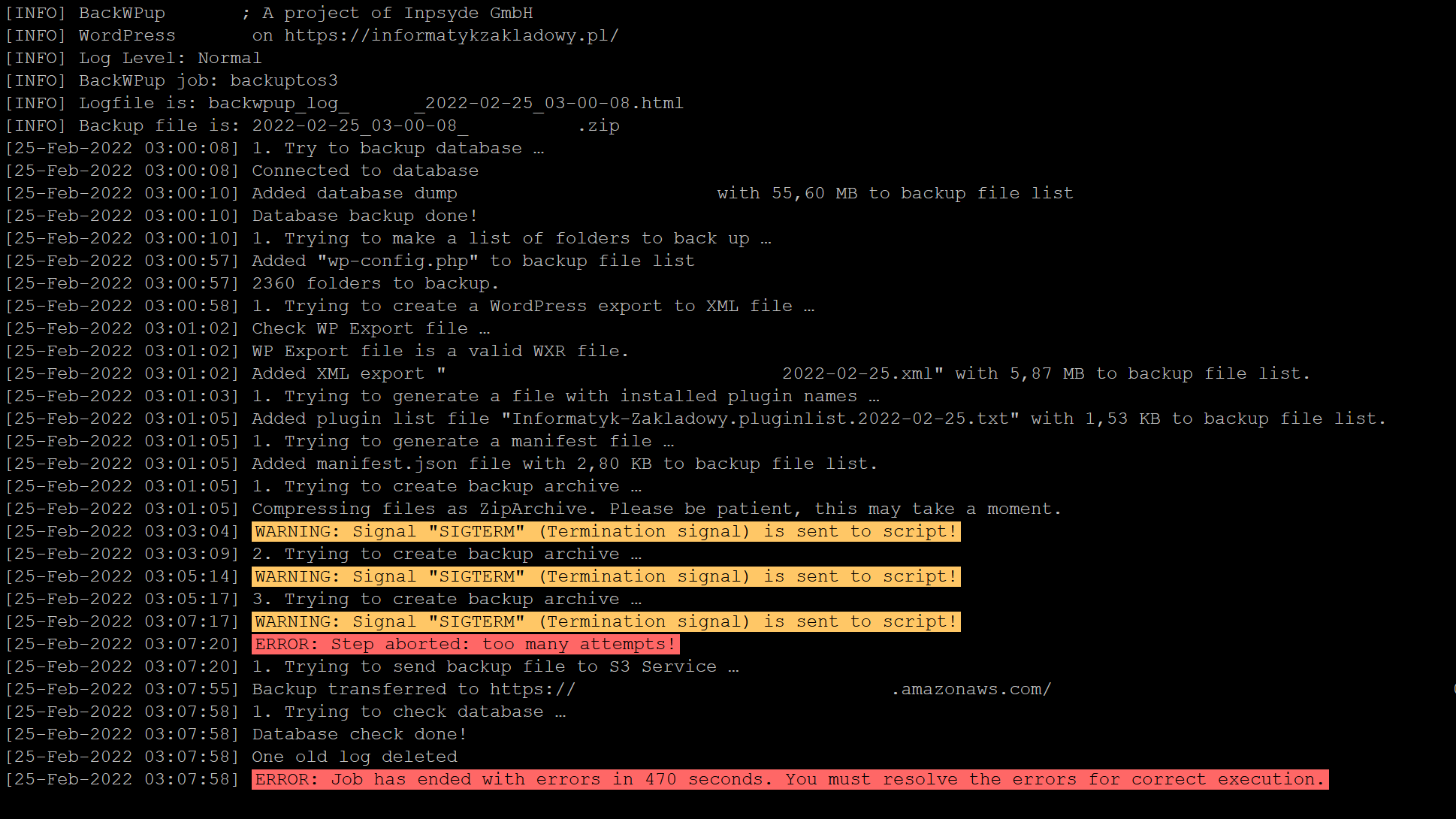
Co tu widzimy? Plugin BackWPup trzykrotnie próbuje spakować wszystkie pliki do archiwum dziennego. Za każdym razem proces jest przerywany po dwóch minutach i wznawiany od zera. Następnie archiwum – kompletne lub nie – jest wysyłane do kubełka S3.
Logi z wcześniejszych dni nie pozostawiały złudzeń.

Wspominałem, że największy plik miał 984 MB, tymczasem kompletny backup powinien zawierać 1378 MB. Przyczyna niekompletności archiwów jest trywialna. Blog Informatyk Zakładowy działa na zwykłym dzielonym hostingu na serwerach Dreamhost. To w zupełności wystarcza, nagłe skoki odwiedzalności pomaga obsłużyć Cloudflare. Jedną z cech takiego hostingu jest jednak brak kontroli nad niektórymi parametrami – między innymi nad limitem czasu wykonania pojedynczego żądania HTTP. Ograniczona jest też ilość pamięci i przydział mocy procesora, bo jedna maszyna obsługuje kilkunastu lub kilkudziesięciu klientów. Dwuminutowy timeout sprawiał, że do archiwum trafiało nie więcej niż kilkaset megabajtów…
Pierwotne źródło problemów
Dlaczego o awarii nie dowiedziałem się wcześniej? Poniżej opisuję sekwencję wydarzeń, które złożyły się na taką sytuację.
W marcu 2020, kilka miesięcy po założeniu bloga, skonfigurowałem jego automatyczny backup. Zdecydowałem się na plugin BackWPup do WordPressa ze względu na dużą elastyczność i konfigurowalność. Mi zależało na dwóch cechach – połączeniu kopii plików z kopią zawartości bazy danych MySQL oraz wysyłaniu backupów do AWS S3.
Zdefiniowane przeze mnie zadanie tworzyło kopię bezpieczeństwa raz na dobę. Przez następny tydzień kilkukrotnie upewniałem się, że kopia jest tworzona poprawnie, że zawiera wszystkie pliki, że zrzut zawartości bazy jest prawidłowy. Skonfigurowałem też w BackWPup e-maile z powiadomieniami o błędach.
W planach miałem przeorganizowanie domowych backupów, lecz zakup NAS-a był oddalony o kilka miesięcy. Nastawiłem więc cykliczne przypomnienia o sporządzaniu kopii bezpieczeństwa komputera na przenośny dysk oraz o testowaniu poprawności backupu bloga. W obu przypadkach – na półtora roku do przodu, do tego czasu nowy system backupów miał już działać.
W drugiej połowie 2020 opublikowałem trzyczęściowy poradnik tworzenia backupów w domu i małej firmie, zaś w styczniu 2021 kupiłem sobie Synology DS220j oraz dwa dyski Seagate IronWolf ST6000VN001 spięte w RAID-1 (replikacja danych, backup odporny na awarię jednego napędu). Blog nadal backupował się jednak tylko na S3. Uznałem, że kopia w chmurze AWS będzie wystarczającym zabezpieczeniem. W końcu sprawdzałem ją regularnie.

W okolicach wakacji 2021 cykliczne powiadomienie wygasło a ja nie odnotowałem tego faktu. Blog obrastał w nowe treści, w artykułach osadzałem duże pliki audiowizualne, kopie bezpieczeństwa puchły i wtedy właśnie backup zawiódł po raz pierwszy. Potem po raz drugi, trzeci – aż do momentu, gdy powiódł się po raz ostatni. Ale ja wtedy nie sprawdzałem już poprawności archiwów, bo moją czujność uśpiło półtora roku prawidłowego działania.
Ale co z tymi alertami e-mailowymi, zapytacie? Zastanówmy się… czy wymusiłem wystąpienie błędu by sprawdzić doręczalność alertów? Pytanie niby retoryczne, ale napiszę to wprost: nie, nie sprawdziłem działania powiadomień o awariach, więc żadna z setek wiadomości nie trafiła do mojej skrzynki.
Co i jak naprawiłem
Pierwszym krokiem w ogarnięciu tej sytuacji było oczywiście sporządzenie i zabezpieczenie pełnej kopii bezpieczeństwa bloga. Ta historia jest już na tyle zawstydzająca, że zbędne jest ubarwianie jej dykteryjkami w stylu „… i wtedy właśnie naprawdę straciłem dane”. Zanim zabierzesz się do jakiejkolwiek pracy nad infrastrukturą, sporządź pełną kopię danych.
Krok drugi – naprawienie alertów. Tu przyczyna okazała się trywialna – adresem nadawcy alertu miał być e-mail w domenie @gmail.com. Mechanizmy wysyłki maili nie miały uprawnień do wysyłania maili w imieniu Gmaila. Gdy zmieniłem domenę na @informatykzakladowy.pl i odpaliłem backup, już po kilku minutach dostałem maila o tytule „[ERROR] BackWPup log 26-lut-2022 18:10: backuptos3”
Krok trzeci – rozdzielenie zadań backupowania na mniejsze części i dopasowanie ich do rzeczywistych potrzeb:
- backup bazy danych – wydzielony jako osobne zadanie, zawiera dane których nie dałoby się odtworzyć w sensowny sposób (np. komentarze czytelników)
- backup pluginów – choć serwis używa tylko dziesięciu, to w ich skład wchodzi prawie 9 tys. plików zgrupowanych w przeszło 2 tys. katalogów; są to pliki które dobrze się kompresują
- backup wszystkich pozostałych plików.
W przypadku tej ostatniej części zmian było najwięcej. Po pierwsze – wyłączyłem kompresję ZIP, bo lwia część objętości kopii bezpieczeństwa to pliki PNG, JPG i MP4, których nie da się skompresować jeszcze bardziej. Zamiast ZIP-a jest TAR (bez kompresji), więc operacje plikowe przyspieszyły. Po drugie – wyłączyłem backup plików cache (tymczasowych), one nie przydadzą się do niczego. Po trzecie – backupowane pliki nie zawierają teraz zasobów audio-wideo z minionych lat; ich kopie mam gdzie indziej.
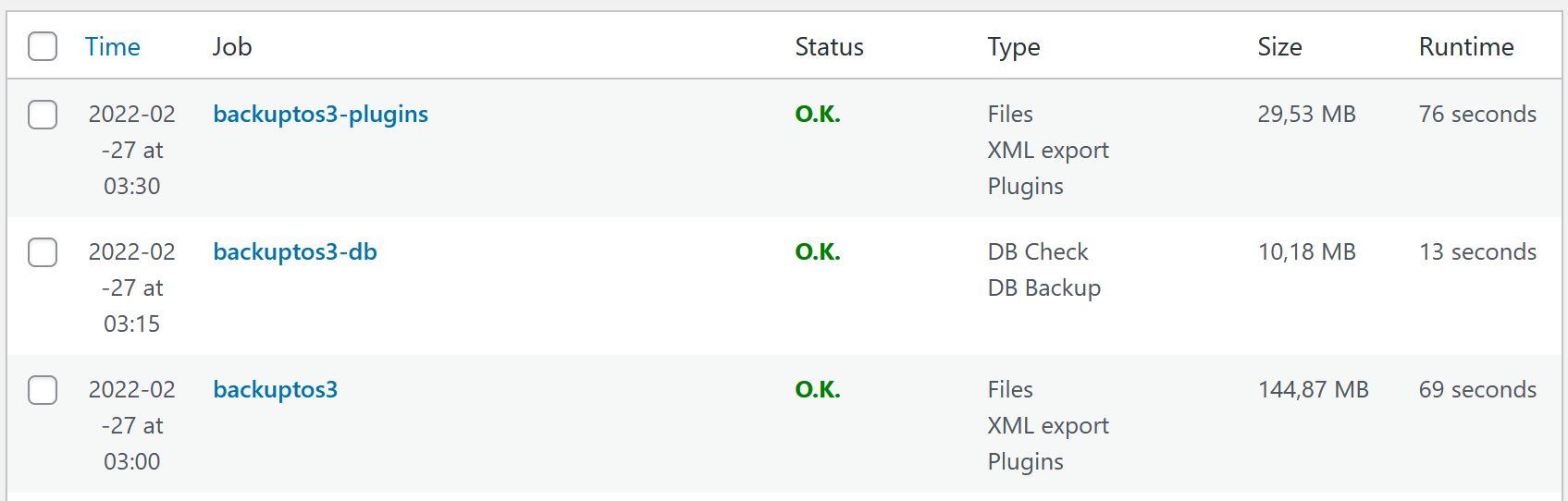
Po wprowadzeniu opisanych zmian czas tworzenia każdej z trzech części backupu nie przekracza półtorej minuty. Aby uniknąć niepożądanych interakcji, startują co kwadrans. A skoro grzebałem już w ustawieniach WordPressa, to aktywowałem także automatyczne aktualizacje wszystkich pluginów. W przeszłości robiłem to ręcznie, w godzinach najmniejszego ruchu – za to z wielodniowym opóźnieniem. Ryzyko wynikające z używania nieaktualnych pluginów jest jednak większe, niż niedogodności związane z kilkuminutową niedostępnością witryny.
Czy w razie awarii/włamania utraciłbym dane na zawsze?
Rozważmy następujący scenariusz – ktoś zyskuje możliwość wykonania kodu na serwerze Informatyka Zakładowego, usuwa zawartość bazy danych WordPressa i kasuje wszystkie pliki. Zauważam to kilka godzin później, wtedy też odkrywam uszkodzone backupy. Co mi pozostaje?
Po pierwsze – Dreamhost
Mój dostawca hostingu to Dreamhost, z usług tej firmy korzystam od roku 2005. Robią świetną robotę i jestem bardzo zadowolony z ich usług, choć nie są najtańsze. Gdyby ktoś szukał rzetelnego hostingu, oto link afiliacyjny (59% zniżki).
W panelu zarządzania witryną można odnaleźć następującą opcję:
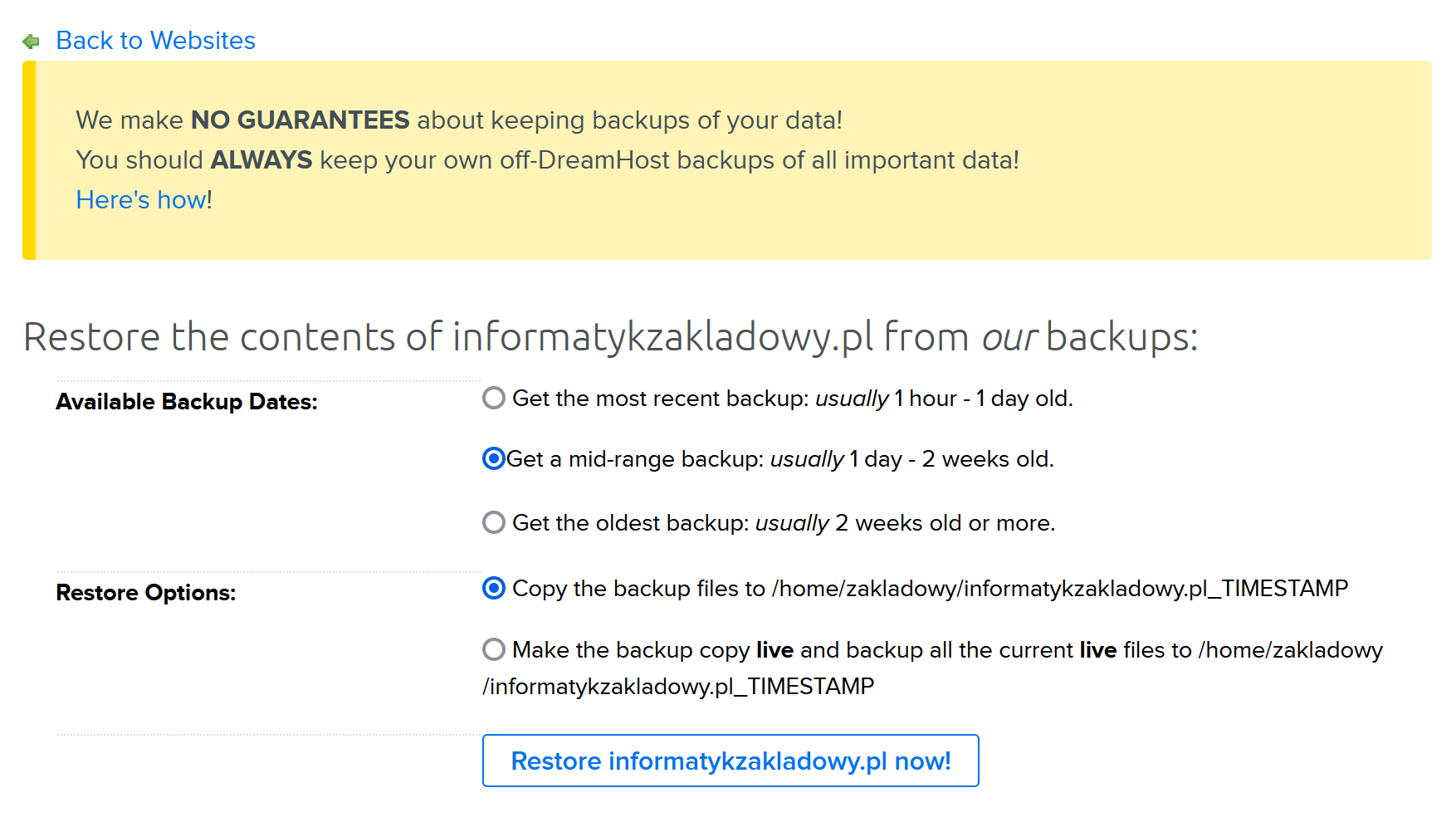
Dreamhost oferuje automatyczne przywrócenie witryny z własnych backupów – najnowszy, „środkowy” lub najstarszy. Po wybraniu odpowiedniej opcji pliki zaczęły spływać na moje konto w ciągu minuty, kompletna zawartość katalogu została przywrócona w ciągu niecałego kwadransa.

Co z bazą danych? Podobnie – do dyspozycji mam opcję przywrócenia zawartości bazy z jednej z siedmiu kopii tworzonych codziennie przez miniony tydzień. To oznacza, że teoretycznie byłbym w stanie podnieść serwis w ciągu kilkunastu minut. W praktyce jednak zacząłbym od analizy powłamaniowej, by blog przywrócony z kopii bezpieczeństwa nie został shackowany ponownie.
Po drugie – niekompletny backup to też backup
WordPress składa się z dużej liczby plików oraz jednej bazy danych. Utrata plików składających się na mechanizm publikacji treści jest nieistotna, odzyskamy je po świeżej instalacji. Podobnie będzie z pluginami oraz wystrojem graficznym. Do odtworzenia jest znakomita większość obrazków używanych w blogonotkach – mam je w domowym komputerze.
Pozostaje temat tekstowego zrzutu zawartości bazy danych. Ten plik ma 50 MB, po kompresji około 10 MB. I tu dobra wiadomość – był obecny w każdym z niekompletnych backupów, bo kopia bazy sporządzana jest w pierwszym kroku. Nawet uszkodzona kopia bezpieczeństwa może więc zawierać kluczowe zasoby! Te dane byłyby o tyle cenniejsze, że w domowych backupach nie miałem finalnych treści blogonotek w takiej postaci, w jakiej trafiały do publikacji.
Po trzecie – archive.org
Gdyby wszystkie metody odzyskania danych zawiodły, ostatnią opcją byłaby ich rekonstrukcja. Serwis Internet Archive (archive.org) sporządził zrzuty zawartości bloga Informatyk Zakładowy 41 razy. Najprawdopodobniej byłbym w stanie wyciągnąć stamtąd treść wszystkich opublikowanych dotąd artykułów oraz część obrazków.
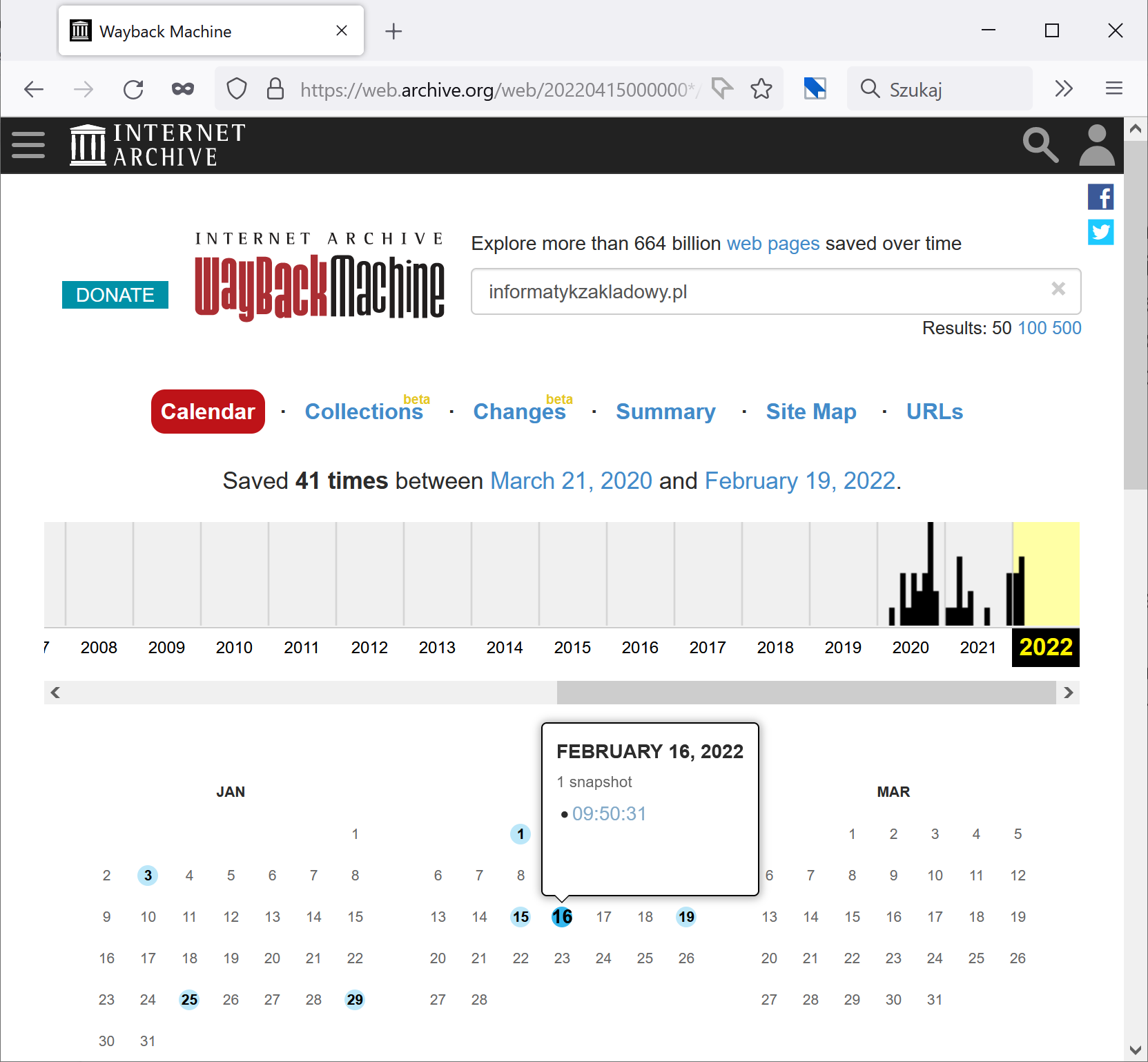
Jak widać, mimo wielu wielomiesięcznej awarii backupów bloga, sytuacja po ewentualnym włamaniu byłaby trudna ale nie beznadziejna. Zauważmy jednak, że mowa o stronie internetowej na WordPressie, publikowanej w internecie. Gdyby w grę wchodziły dokumenty lub dane księgowe małej lub średniej firmy, uszkodzony backup mógłby stanowić dużo większe zmartwienie.
Moja prywatna strategia kopii bezpieczeństwa
Swoje backupy tworzę według zasad, które opisałem w darmowym e-booku o kopiach bezpieczeństwa w domu i małej firmie.

Kopia odporna na ransomware to dysk zewnętrzny WD My Passport 1TB z kontenerem VeraCrypta. Kopiuję tam ręcznie (według ustalonego harmonogramu) te pliki, których utrata byłaby najbardziej bolesna.
Kompletna lokalna kopia danych leci na NAS Synology DS220j, do którego włożyłem dwa dyski Seagate IronWolf ST6000VN001 spięte w RAID-1. Ten backup wykonywany jest automatycznie oprogramowaniem kopia.io.
Kopię przechowywaną w innym miejscu realizuję za pomocą Backblaze, usługi zdalnego backupu do chmury (czytaj: na cudze komputery).
Uprzedzając pytanie – tak, czasem sprawdzam, czy ten albo tamten plik daje się wyciągnąć z opisanych wyżej backupów i czy jego zawartość jest prawidłowa.
Test odtworzenia bloga z backupu
Za chwilę pojawi się żargon, nie będzie opatrzony objaśnieniami. Bez większej straty możesz pominąć ten rozdział i przeskoczyć bezpośrednio do zakończenia.
W końcu możemy przejść do tematu, od którego zaczęła się cała ta historia – test odtworzenia bloga z backupu. Sam nie zajmuję się administracją systemów i nigdy nie utrzymywałem ani nie zabezpieczałem publicznie dostępnych serwerów WWW, więc jako kryterium sukcesu przyjąłem dostępność serwisu w izolowanej od sieci maszynie wirtualnej.
Uruchomiłem świeżo zainstalowanego Ubuntu 21.04, przeniosłem do niego trzy pliki z backupem bloga.
0:00
Czas start.
0:05
zainstalowałem Apache oraz MariaDB, zgodnie z tym tutorialem
0:10
zainstalowałem phpMyAdmin prawie zgodnie z tym tutorialem, utworzyłem użytkownika bazodanowego z wszystkimi przywilejami, spróbowałem zaimportować plik SQL. Nie udało się, wygooglałem komunikat błędu. Przyczyna problemu – maksymalny domyślny rozmiar uploadu to 2 MB, backup bazy ma 50 MB. Odnajduję plik konfiguracyjny PHP, zmieniam tę wartość na 200 MB. Maksymalny rozmiar uploadu rośnie do… 8 MB. Odnajduję inny parametr, maksymalny rozmiar żądania POST, podbijam wartość. Tym razem import startuje, minutę później baza jest przywrócona. Wyłączam maszynie wirtualnej połączenie z siecią.
0:15
rozpakowuję backup do katalogu z którego Apache serwuje witrynę, zmieniam w pliku wp-config.php ustawienia bazy danych, próbuję załadować zawartość http://localhost. Zostaję przekierowany na adres domenowy. Przypominam sobie, że muszę przestawić w tabeli wp_options bazowy adres bloga na „localhost”. Potem trzeba jeszcze wyczyścić cache przeglądarki, by zapomniała o przekierowaniu, i…
0:20
lokalna kopia bloga działa.
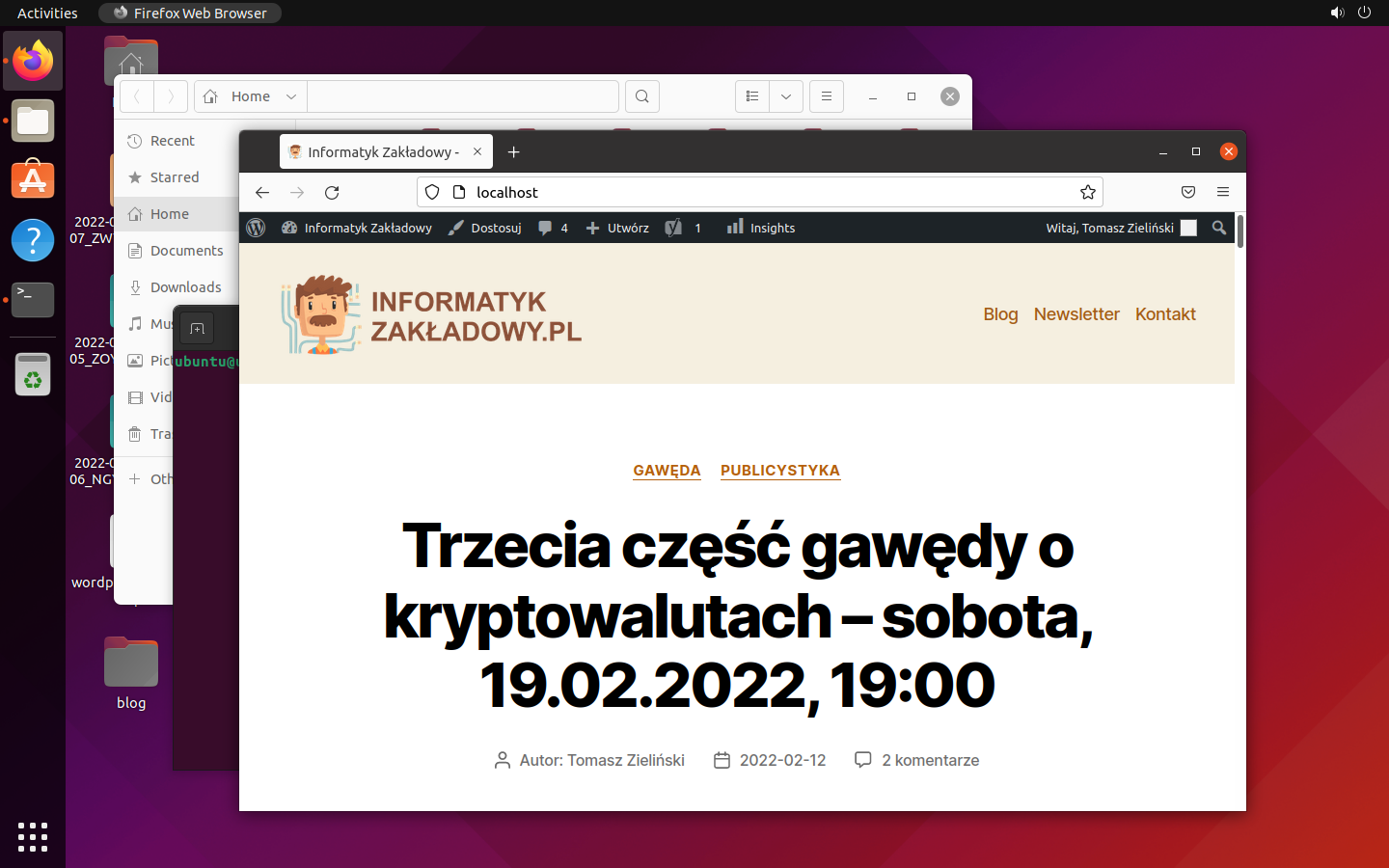
Cały proces przebiegł bezproblemowo, ale nie mogłem tego wiedzieć, póki nie sprawdziłem. Oczywiście – tak postawiony i skonfigurowany serwer nie nadawałby się do wystawienia na świat, ale skoro WordPress odtworzony z backupu działa na localhoście, to zadziała też po przywróceniu na docelowym hostingu (zarządzanym przez ludzi wiedzących co robią).
Zakończenie
Uszkodzone backupy odkryłem, zanim stały się potrzebne. Mogłem w spokoju przeprowadzić analizę problemu, zastanowić się nad ewentualnym planem „B” i „C”, naprawić alerty itd. Takiego komfortu nie miałbym w obliczu rzeczywistej awarii i konieczności przywracania serwisu z niekompletnych kopii bezpieczeństwa.
Jeśli robisz backupy – sprawdź ich integralność teraz! (no i daj znać w komentarzu, jeśli właśnie na jaw wyszły jakieś problemy)
Jeśli nie robisz backupów ale chcesz zacząć, zapisz się na newsletter – od razu po potwierdzeniu subskrypcji otrzymasz e-booka, dzięki któremu JUŻ DZIŚ zabezpieczysz kopię najważniejszych plików.
Nie masz gdzie trzymać backupów? Musisz kupić odpowiedni sprzęt albo usługę? Będzie mi bardzo miło, jeśli skorzystasz z linków afiliacyjnych obecnych w tym artykule. Ty zapłacisz tyle samo, a ja dostanę niewielką prowizję od twoich zakupów. Polecam sprzęt i oprogramowanie, którego sam używam:
- Backblaze – backup do chmury bez limitu wielkości. Działa w tle i non stop backupuje zawartość twojego komputera. Korzystam od wielu lat. Cena: 70 USD rocznie (marzec 2022)
- WD My Passport 1TB / 2TB / 4 TB – dyski zewnętrzne z interfejsem USB 3
- SanDisk Ultra Dual Drive USB-C 128GB / 256 GB – pendrive z podwójną wtyczką USB A / USB C
- NAS Synology 220j – do domu i małego biura, miejsce na 2 HDD (tutaj zestaw z 2 x HDD 4 TB)
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

22 odpowiedzi na “Lekarzu, ulecz się sam czyli moje backupy nie działały”
Ja robię produkcyjnie teraz tak: 1) mysql – xtrabackup z dockera robi backup do folderu, potem dwa przebiegi prepare. Następnie odpalam MySQL z dockera na tych plikach backupu i robię mysqlcheck + query sprawdzające ostatnie wpisy czy nie są starsze niż 24h. Potem pacham to na nas przez restic ( szyfrowanie, deduplikacja i pilnowanie ilości kopii). Wszystkie te czynności są monitorowane przez żabnica więc jak coś nie wpadnie albo będzie za mało danych to informacja. Pliki pcham tak samo ale w innym przebiegu by je oddzielnie monitorować.
Niech szewc bez butów pierwszy rzuci kamieniem 😉
Dzięki wielkie za ten tekst. Obyśmy uczyli się na Twoich błędach.
Pytanie o NAS – zakładając, że nie potrzebuję wysokiej dostępności – lepiej RAID 1 czy drugi dysk z zestawu użyć jako dysk na backup dysku pierwszego. Jak często padają oba dyski w RAID 1? Czy drugi dysk z niższym przebiegiem nie będzie lepszym rozwiązaniem?
Robienie backupu na dysk 1 a z niego na dysk 2 oznacza, że albo oba zapisują tyle samo i są włączone tak samo długo, albo backup na dysku 2 jest spóźniony i w razie awarii jedynki nie masz najnowszej kopii bezpieczeństwa.
Backblaze unlimited? za 70$/rok? Ciekawe, czy da radę skopiować lokalnego NASa, na którym jest zamontowany unlimited dysk z chmury?
Ja WordPressy backupuję przez rsync i mysqldump. Później odtworzenie struktury plików i bazy lokalnie, w Dockerze, podmiana kilku zmiennych w bazie i konfiguracji WP na domenę lokalną, a na koniec test, czy pewna zawartość się wczytuje (curl). Automat, oskryptowane, jak coś nie pójdzie to dostaję e-maila, a na kopię lokalną WP mogę sobie wejść w przeglądarce. Nigdy nie używam do wgrywania baz phpMyAdmina. Polecam hostingi z dostępem SSH 🙂
SSH (nawet okrojone do najbardziej podstawowychg aplikacji) i możliwość używania crona do kopii zapasowych to świetna sprawa. Przede wszystkim nie wiążą człowieka z dostawcą, a migracja do innego, oferującego dostęp SSH, to tylko kilka godzin pracy.
Dreamhost ma SSH 🙂
Ja staram się powiadomienia mailowe wysyłać zawsze, tylko ze statusem OK lub ERROR (najlepiej w temacie). Jeżeli jest OK to jestem spokojny a brak maila nie jest dla mnie sygnałem, że wszystko jest w porządku.
Takie wiadomości można sobie zawsze ogarnąć filtrami i OK przenosić do spamu. Ja wolę, kiedy mi dzwoni telefon w razie awarii, bo wiem o niej najdalej w 3 minuty po jej wystąpieniu.
W poprzednich wpisach polecałeś EaseUs ToDo backup, a tutaj już kopia.io. To które lepsze to zastosowań domowych? 😉 Jak one się mają w zestawieniu do Duplicacy/Duplicity. Dla kogoś, hmm.. bardziej zaawansowanego.
No i ciekawy byłby artykuł o kopiowaniu zdjęć z karty aparatu bez pośrednictwa laptopa (jesli jest to coś innego, niż OTG w telefonie 😛 )
Kopia.io nie jest narzędziem dla początkujących, więc nie ma go w poradniku dla początkujących. Wspomnianych przez Ciebie programów nie znam.
A co z narzędziami dostępnymi wraz z synology ? Nie będą skuteczniejsze i lżejsze ?
Jakoś mi nie podeszły.
A czy kopia.io jest odpowiednim narzędziem do więcej niż zastosowań domowych? Zdjęcia, dokumenty, programowanie, projekty? Sprawdzić oczywiście mogę sobie, w wolnej chwili, ale później kwestia odzysku danych to dobrze mieć coś z polecenia 😉
I w sumie inne pytanie: lepiej ustawić backup (jakimkolwiek programem) na całą partycję, czy podzielić na zestawy folderów z zależności od częstotliwości ich modyfikacji i sposobu (np. zdjęcia głównie przyrostowo, programowanie to jakieś foldery to w sumie jako archiwum traktowane)?
Nie wiem, czy da się udzielić jakiejś takiej porady ogólnej, pasującej każdemu. A co do kopia.io, to polubiłem ze względu na deduplikację – backupuję tam wiele komputerów, każdy ma osobne snapshoty ale takie same pliki są w jednej, eeee, kopii 😉
(oczywiście ta „jedna” kopia siedzi na RAID, więc już są jej dwie)
Takie same pliki w jednej kopii? Masz na myśli, że na jednym serwerze NAS? 😛
Może inaczej zadam pytanie, razem z innymi:
1. Dlaczego zmieniłeś EseaUs na kopia.io (poza deduplikacją)?
2. Czy wszędzie zmieniłeś na kopia.io?
3. Jeśli zmienię położenie jakiegoś folderu lub jego nazwę, to jak „zachowa się” deduplikacja – odnotuje tylko te zmiany, czy skopiuje razem z zawartością?
ad 1) EaseUS polecam początkującym, bo interfejs jest przyjazny i zrozumiały, mało zaawansowany użytkownik go ogarnie. Ja potrzebuję narzędzia bardziej zaawansowanego i w sumie może to być temat na osobny artykuł.
ad 2) kopia.io+NAS to nie jest jedyny backup, mam jeszcze Backblaze (chmura) i HDD offline
ad 3) pliki są deduplikowane wg zawartości, położenie pliku należy do danych snapshotu, nie jest cechą pliku
W temacie tego Easeusa – kiedyś doszły mnie słuchy, że zdarzyła się im taka aktualizacja programu, która bie potrafiła obsłużyć backupu zrobionego poprzednią wersją programu. Prawda to?
Będzie poradnik o Kopia.io?
Nie uzywam synology tylko qnap i niestety qnap nie ma fajnej apki do backupow. Ktos powie jest netbak (synology chyba ma odpowiednik), alw netbak nie wystartuje bez praw admjna, wiec do backupu sie nie nadaje. Jest qsync ale to tez tak srednio, bo domyslnie dziala tam, ze jesli plik zostanie usuniety z komputwra zniknie tez z qnapa.
Do backupow wybralem: syncbackfree, kopia.io sprawdze 🙂
Dzięki za super art .
Może opiszę moje zabawki.Jestem amatorem samoukiem i ciekaw jestem jak ocenicie taki config .
Mam mały serwerek (nazwijmy srv1) na którym lata 24/7 nextcloud dostępny przez www i reszta serwisow (storage to 2 dyski w raid 1).
Userzy w domu synchronizują co tam chcą z telefonów i kompow z nextcloud.
Na srv1 lata skrypt bash odpalany z crona który robi pewne przygotowania , zrzuca bazy danych (codziennie) i kluczowe partycje (/ oraz home) – to raz na tydzień (używam fsarchiver z niedużą kompresją)
W razie przejęcia srv1 przez atakującego kazdy backup dostępny z przejetej maszyny jest zagrozony skasowaniem.
Dlatego przyjalem ze nie odpalam żadnego backupu z srv1
Cron z srv1 odpala w nocy WOL i budzi srv2 (tez raid 1 z dwóch dysków )
Na srv2 lata skrypt cron który wbija się na srv1 po ssh i montuje zasoby po sshfs.
Borg backup z odpowiednimi przelacznikami ciągnie wszystko z srv1 na srv2 (wszystko trwa przeciętnie do pol h bo pobiera tylko to co nowe lub zmienione, w sumie backupowi podlega ok 1,5 tb plików )
Sukces lub porażka idzie po gotify pushem na komórkę
Kopia z srv jest kopiowana jeszcze w jedno miejsce (tu moze być cokolwiek) dowolną metodą . U mnie dysk przenośny a z niedługo pewnie cos w necie
Jak myślicie?
Dzięki, dobry artykuł. Co prawda nie używam wtyczkek do kopii zapasowych, bo mam nie tylko WordPressy, ale u mnie zasada jest podobna. Monitoruję backup, to znaczy: czy istnieje archiwum/zrzut bazy z dzisiejszą datą w nazwie oraz czy plik jest większy niż zakładane minimum. Jeżeli nie, telefon mruga i brzęczy.
Niedawno nawet stary streamer sobie kupiłem i nagrywam niektóre rzeczy na taśmy. Już kilka razy sprzęt trzeba było otwierać, bo któraś tam sprężynka odskoczyła, ale pomimo swoich lat działa świetnie.
Wpadka nie jest aż taka znowu straszna i niespotykana. Pamiętam historię, kiedy backup Githuba odzyskano z kopii zapasowej lokalnego dysku któregoś z administratorów. Bo oficjalne backupy były puste.
Nie ufam szczególnie żadnym kreatorkom od Synology, lub Qnapa. Niestety wiążą z producentem sprzętu. Pracowałem trochę z Baculą (nikomu nie życzę przebijana się przez konsolę Baculi, ale odzyska absolutnie wszystko; nie raz klienci błagali o starą pocztę) i teraz doszkalam się z Borg Backup. Kopie przyrostowe, obsługiwane przez obydwa powyższe, oszczędzają kilogramy przestrzeni dyskowej.