
Większość z nas zetknęła się z QR-kodami, niewielkimi obrazkami pomagającymi otwierać na komórce stronę internetową bez ręcznego wklepywania adresu. Mało kto jednak zastanowił się, jakie algorytmy odpowiadają za to, że zeskanowanie QR-kodu jest tak szybkie i niezawodne.
Niniejszy artykuł opisuje proces produkcji obrazka z wybranym napisem. Ścieżka będzie jak zwykle prowadziła zakosami, poczytamy więc o nadmiarowym kodowaniu korekcyjnym, steganografii, typach QR-kodów, a nawet zagrożeniach, jakie mogą tkwić w tych niewinnych, czarno-białych obrazkach. Wszystko opisane prostym językiem, zrozumiałym dla osób spoza branży IT. Zapraszam do lektury!
Jeśli rozpoczynasz niniejszy tekst nie wiedząc, czym są QR-kody, oto rekordowo krótkie i zwięzłe objaśnienie: są to obrazki, w których według pewnego zestawu reguł zakodowano jakiś napis. Przykładowy QR-kod wygląda tak, jak poniżej (no i zawiera napis „Przykładowy QR-kod wygląda tak”).

Zawartość obrazka możesz odczytać przy pomocy jednej z wielu aplikacji mobilnych. Czasem nawet standardowa aplikacja aparatu rozpoznaje QR-kody i odczytuje ich zawartość (dzieje się tak na iOS od wersji 11 oraz w androidowych aplikacjach używających technologii Google Lens).
Cały artykuł będzie osnuty wokół dwóch wątków – jak się tworzy (koduje) taki obrazek i jak się go odczytuje (dekoduje). Do tego cała masa dygresji i ciekawostek.
Dlaczego QR-kody są różnej wielkości?

Gdy przyjrzymy się przykładowym QR-kodom, szybko zauważymy różnicę w liczbie modułów (pikseli) z których złożone są obrazy. Standard definiuje 40 wersji różniących się rozmiarem, a więc i pojemnością (do tego tematu jeszcze wrócimy). Wersja pierwsza to kwadrat 21×21 modułów, każda kolejna wersja zwiększa bok kwadratu o 4 moduły – wersja czterdziesta ma więc rozmiar 177×177 modułów.
Oto demonstracja wszystkich 40 wersji QR-kodów. Każdy kolejny zawiera coraz dłuższy kawałek Inwokacji z „Pana Tadeusza”.

(wszystkie inne też)
Uważny obserwator spostrzegł, że wszystkie powyższe kody mają kilka cech wspólnych. Sprawdźmy, jakie elementy graficzne znajdziemy w każdym prawidłowym QR-kodzie.
Z czego składa się QR-kod?

Oto obrazek, w którym niektóre części zostały wyróżnione kolorami. Omówimy je po kolei.
Wzór pozycjonowania (finder pattern)
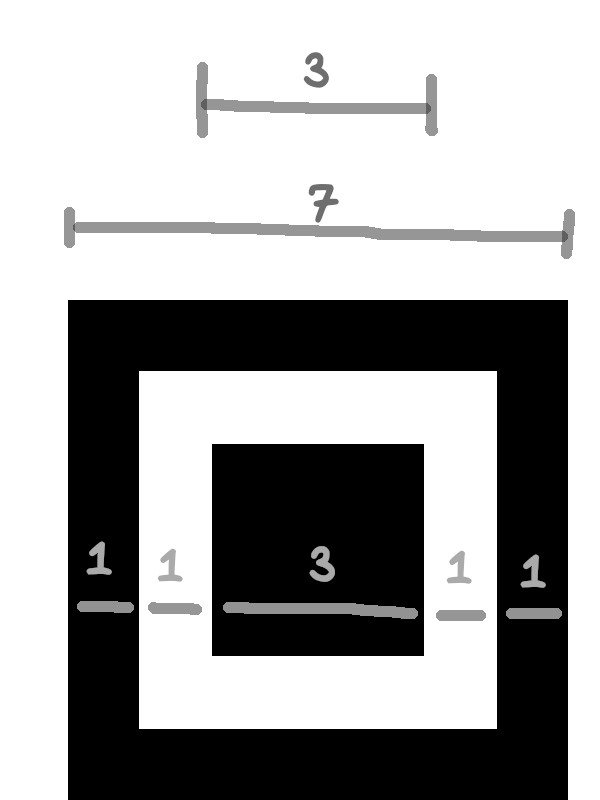
Wzór pozycjonowania to 49 modułów składających się na trzy zagnieżdżone kwadraty. Wzór ten służy do szybkiego określenia pozycji QR-kodu. Zauważmy, że linia przechodząca przez środek wzoru pozycjonowania zawsze będzie zawierała sekwencję zmian koloru „czarny – biały – 3 x czarny – biały – czarny” (patrz obrazek poniżej). Dzięki temu możliwe jest szybkie wytypowanie prawdopodobnej lokalizacji QR-kodu. Dodatkową wskazówką dotyczącą kąta widzenia jest to, że trzy wzory pozycjonowania tworzą trójkąt prostokątny.
Od wewnętrznej strony QR-kodu wzór pozycjonowania otoczony jest paskiem białych modułów (tu oznaczonych kolorem jasnozielonym). Specyfikacja wymaga, aby cały QR-kod miał biały margines o szerokości 4 modułów (tzw. quiet zone).

Wzór wyrównania (alignment pattern)
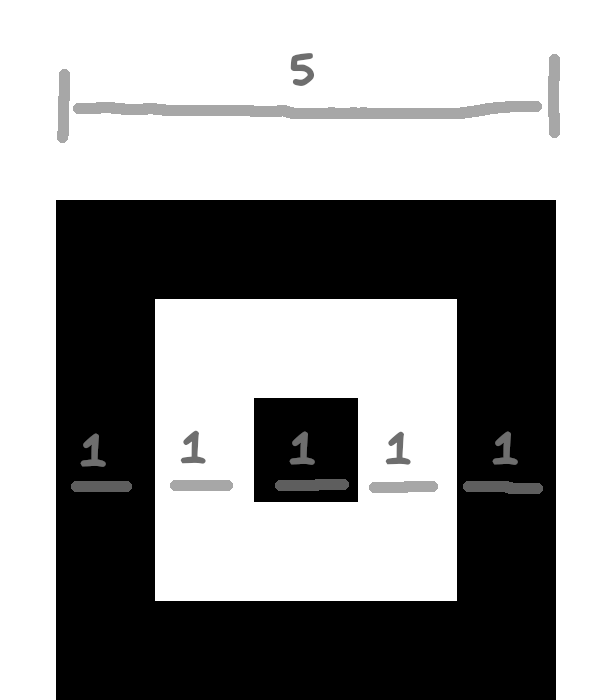
Ten wzór składa się z 25 modułów i służy jako element pomocniczy, potwierdzający prawidłową lokalizację i orientację QR-kodu. Nie występuje w wersji 1, od wersji 2 do 6 pojawia się w jednej kopii, od wersji 7 jest obecny w sześciu kopiach, potem liczba ta rośnie aż do czterdziestu sześciu sztuk (wersje od 35 wzwyż). Regularność rozłożenia modułów pomaga w określeniu stopnia deformacji kodu na fotografii.

Wzór synchronizacji (timing pattern)
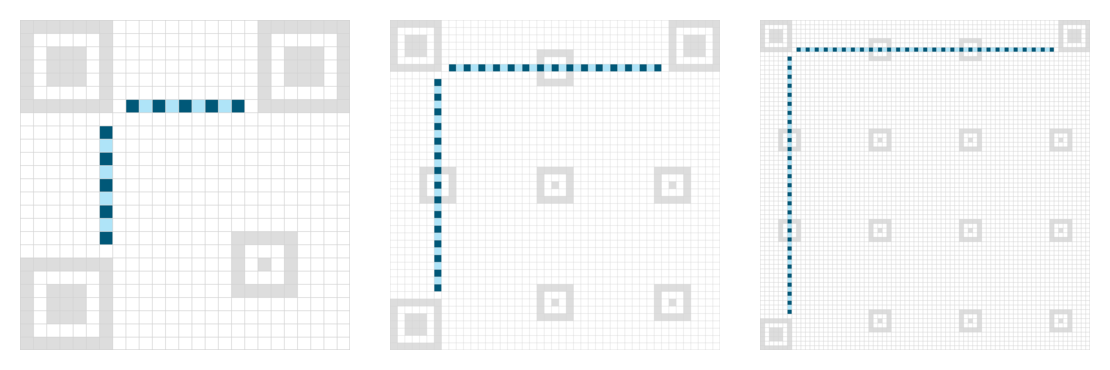
Pasek narysowany w siódmej kolumnie i siódmym wierszu obrazka, rozciągnięty między wzorami pozycjonowania. Składa się z naprzemiennych czarnych i białych modułów. Zawsze zgrywa się ze wzorami wyrównania tak, by środek wzoru wyrównania trafiał w czarny moduł paska synchronizacji.
Informacja o formacie (format information)
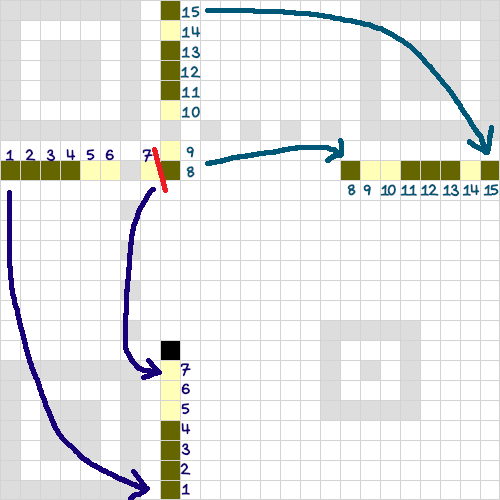
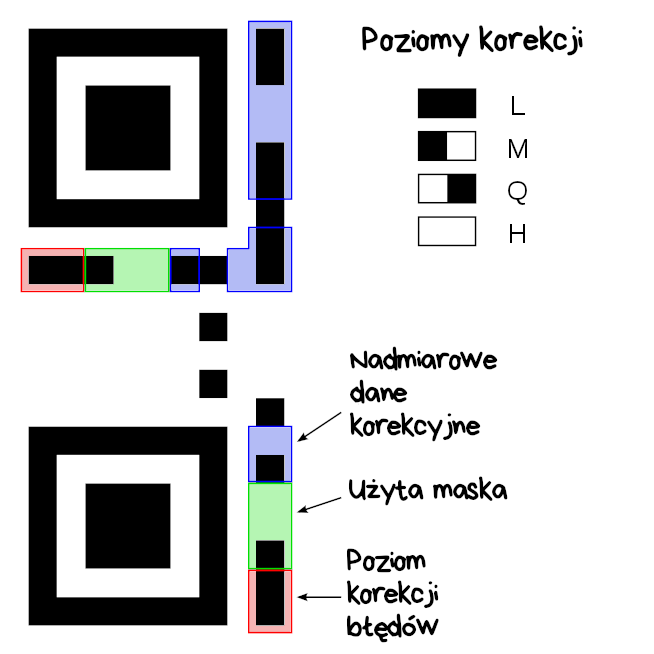
Wokół lewego-górnego wzoru pozycjonowania znajduje się zestaw 15 modułów w których zakodowany jest poziom korekcji błędów QR-kodu oraz użyta maska (oba elementy będą opisane w dalszej części). Dane te są zdublowane – kopia pierwszych 7 modułów występuje na dole, pozostałe 8 modułów ma swoje odpowiedniki po prawej stronie.
Nad dolnym paskiem z danymi o formacie leży ósmy moduł, który zawsze jest czarny. Bo tak.
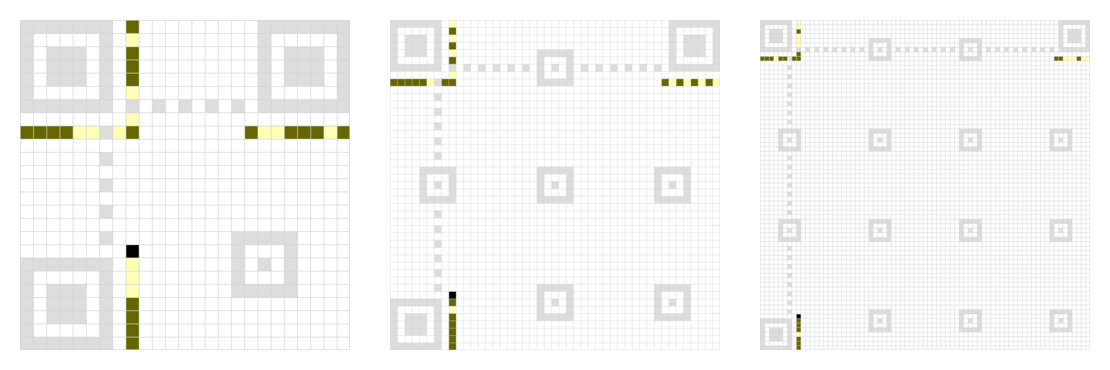
Co ciekawe, z 15 modułów (bitów) składających się na zestaw danych jedynie pierwszych 5 niesie rzeczywiste informacje o poziomie korekcji (2 bity) i masce (3 bity). Pozostałe 10 modułów przechowuje nadmiarowe dane korekcyjne, dzięki którym nawet trzy błędnie odczytane moduły zostaną naprawione.
Informacja o wersji (version information)

Ten segment występuje tylko w QR-kodach o wersji 7 lub wyższej. Składa się z dwóch prostokątów o wymiarach 3×6 modułów, o identycznej zawartości i symetrycznym ułożeniu.
Oba moduły niosą jedynie informację o wersji (a więc rozmiarze) QR-kodu. Ich zawartość nie zależy od zakodowanego przekazu, będą identyczne we wszystkich QR-kodach o danym rozmiarze. Pierwsze 6 bitów to binarne kodowanie numeru wersji, pozostałe 12 to kody korekcyjne. Moduł informacji o wersji może pomóc w dekodowaniu wtedy, gdy wzór synchronizacji jest zbyt mało czytelny, by mógł stanowić bazę dla określenia wymiarów QR-kodu.
Obszar chroniony
Wszystkie wzory i moduły opisane w tym rozdziale składają się na obszar chroniony przed późniejszymi modyfikacjami. Napis osadzany w QR-kodzie będzie po zakodowaniu umieszczony w pustych obszarach.

Przypomnijmy sobie obrazek z początku tego rozdziału. Teraz potrafisz już rozpoznać poszczególne moduły i ich zastosowanie. Sprawdźmy, jak koduje się tekst do umieszczenia w pustych miejscach szablonu.
Tworzymy zakodowany napis
Pierwszym etapem kodowania napisu, który chcemy umieścić w QR-kodzie, będzie przedstawienie go w postaci bitów i bajtów. Tu przydatna będzie wiedza z dwóch wcześniejszych artykułów. W tekście pt. „Emotikonki, Unicode, kodowanie znaków, bezpieczeństwo, 😷🦠” pisałem o tym, czym są strony kodowe, tablica ASCII oraz dlaczego w Unicode do zapisu jednego znaku możemy potrzebować wielu bajtów. W artykule „Wysyłamy plik pocztówką czyli do czego służy kodowanie Base64” objaśniłem, w jaki sposób możemy kodować literki na ułamkach bajtów. Gdy do zapisu jednej litery potrzebujemy ¾ bajtu, możemy zmieścić 5 liter w 4 bajtach.
Tryby kodowania
Wcześniej pisałem o umieszczaniu w QR-kodzie napisów, jednak podstawowym wariantem kodowania wiadomości jest zapisywanie bajtów „jeden do jednego”. Możemy więc zawrzeć w obrazku dowolny plik binarny (byle nie za duży)
Drugim trybem jest tryb numeryczny, w którym do zakodowania mamy jedynie cyfry. Tu każda cyferka zajmie jedynie 3⅓ bitu, co na pierwszy rzut oka nie ma żadnego sensu, bo przecież bit jest niepodzielny (zero lub jedynka). Spójrzmy na to inaczej – istnieje 1000 kombinacji trzech cyfr dziesiętnych: 000, 001, 002… aż do 999. Jesteśmy w stanie zmieścić informację o takiej kombinacji w dziesięciu bitach (nawet z małym zapasem, 210 = 1024). Skoro trzy cyfry dziesiętne zapiszemy w dziesięciu bitach, to każda zajmuje właśnie 3⅓ bitu. Jeśli liczba cyfr do zakodowania jest niepodzielna przez trzy, dwie ostatnie cyfry kodujemy na 7 bitach (też z zapasem, 2 cyfry to 100 kombinacji, 27 = 128) zaś jedną – na 4 bitach (10 cyfr, 24 = 16).
Trzecim trybem kodowania zawartości QR-kodu jest tryb alfanumeryczny, w którym do dyspozycji mamy cyfry, wielkie litery, spację i kilka znaków specjalnych, jak kropka, plus, minus czy znak procentu. Tutaj łączymy znaki w pary i każdą parę zapisujemy na 11 bitach, co daje średnio 5.5 bitu na znak (45 znaków, 2025 kombinacji, 211=2048).
Egzotyczne tryby kodowania
O tych trybach wspomnę tylko raz, nie wrócą w dalszej części tekstu.
Czwarty tryb kodowania umożliwa zapisywanie w QR-kodzie alfabetu Kanji w dwubajtowym kodowaniu Shift JIS. Tryb mało przydatny dla użytkowników polskojęzycznych.
Znacznik Extended Channel Interpretation (ECI) pozwala w teorii na wskazanie jednej z 30 stron kodowych. Moglibyśmy zadeklarować użycie ISO-8859-2 i liczyć na to, że polskie znaki w zapisanym tekście będą zajmować po jednym bajcie. W praktyce jedynym powszechnie obsługiwanym trybem ECI jest UTF-8, który i tak pozostaje domyślną metodą interpretacji odczytanego ciągu bajtów, więc nie trzeba go wskazywać.
Specyfikacja ISO/IEC 18004:2015 daje możliwość łączenia treści wielu kodów w jedną całość poprzez osadzanie w każdym kodzie znacznika serii. Nie spotkałem ani jednego programu potrafiącego zinterpretować ten tryb. Znacznik serii jest ignorowany – oprogramowanie odczytuje QR-kod i nie sygnalizuje, że odczytany przekaz to część większej całości.
Tryb FNC1 to wariant kodowania numerycznego w którym osadzony jest ciąg cyfr zgodny ze specyfikacją GS1. Jest to międzynarodowy standard kodowania informacji opisujących towary, usługi, elementy łańcucha dostaw i inne obszary związane z logistyką (przykład: tekst „(11)101020(17)111020(10)217001” koduje kolejno datę produkcji, datę ważności oraz numer partii).
Tworzenie optymalnej kombinacji kodowania
Teraz będzie fajny trik. Jeden QR-kod może zawierać wiadomość złożoną z kilku różnych segmentów kodowanych różnymi metodami. Na tej stronie możemy znaleźć automat wyznaczający taki podział wiadomości na sekcje, aby zakodowana wiadomość była jak najkrótsza.
Przykłady:
- napis
QWERTY123456zajmuje w kodowaniu alfanumerycznym 79 bitów (13 bitów nagłówka i 66 bitów danych). - napis
QWERTY1234567zajmuje w kodowaniu alfanumerycznym 85 bitów (13 bitów nagłówka i 72 bity danych) - napis
QWERTY1234567(ten sam) po podziale na dwie sekcje zajmie 84 bity (sekcja alfanumeryczna: 13 bitów nagłówka i 33 bity danych, sekcja numeryczna 14 bitów nagłówka i 24 bity danych)
Na wspomnianej stronie można samodzielnie sprawdzić, jak będzie wyglądał optymalny podział dla dowolnego napisu, oto przykład:
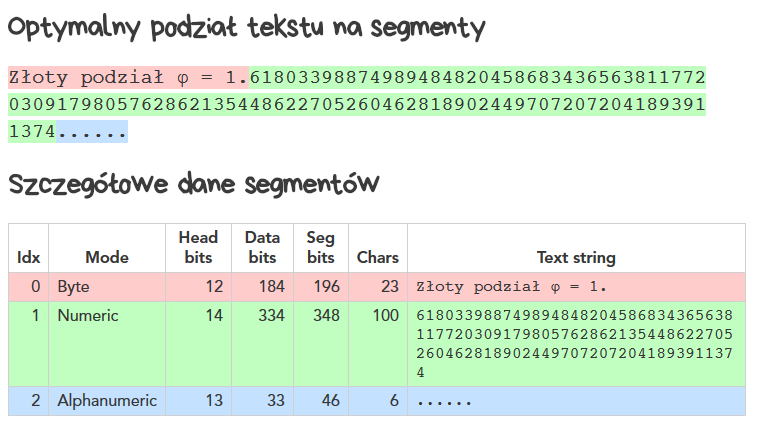
Jeśli interesuje cię arytmetyka i chcesz krok po kroku prześledzić etapy tworzenia QR-kodu z rozpisaniem każdego bitu i bajtu, odwiedź koniecznie stronę nayuki.io/page/creating-a-qr-code-step-by-step – możesz tam podać swój napis do zakodowania i śledzić jego losy na kolejnych etapach! Jest to naprawdę świetnie zrobiona strona i dobrze, że już istnieje – w przeciwnym razie trzeba by ją napisać!
Wiemy już, jakim przekształceniom poddawany jest wejściowy ciąg znaków (cyfr, liter, bajtów) do umieszczenia w QR-kodzie. Kolejnym etapem będzie wzbogacenie go o nadmiarowe informacje korekcyjne, dzięki którym QR-kod będzie odporny na błędy odczytu.
Dygresja – czym są kody korekcyjne
Jakiś czas temu napisałem tekst „Co to są sumy kontrolne plików i do czego mogą nam się przydać?”. Opisałem tam mechanizm, dzięki któremu możemy dowiedzieć się, że przekaz uległ uszkodzeniu podczas transmisji. Tutaj idziemy krok dalej – chcemy nie tylko dowiedzieć się o usterce, ale także ją skorygować.
Encyklopedyczna definicja kodowania korekcyjnego to „technika dodawania nadmiarowości do transmitowanych cyfrowo informacji; umożliwia całkowitą lub częściową detekcję i korekcję błędów powstałych w wyniku zakłóceń”.
Prosty przykład korekcji błędów
Jak może działać przykładowe kodowanie korekcyjne? Pokażę to na prostym przykładzie. Załóżmy, że nasze komunikaty przesyłane przez system łączności to zawsze jedno z czterech imion żeńskich: Ania, Asia, Isia czy Maja. Obawiamy się, że podczas transmisji pojedynczego komunikatu jedna z literek może zostać przekłamana. Gdy odbierzemy wiadomość „Ania”, to nie wiemy, czy nadawca nie nadawał przypadkiem „Asia” (i odwrotnie). Co możemy zrobić?
Gdy podwoimy długość komunikatu i każde imię będziemy nadawać dwukrotnie (zaś awaryjność systemu łączności nadal nie będzie wyższa niż jedna przekłamana literka na komunikat), będziemy w stanie wykrywać błędy transmisji. Odebrany komunikat „AsiaAsia” daje tym razem pewność co do intencji nadawcy, zaś „AsiaAnia” to na pewno komunikat uszkodzony.
Gdy potroimy długość pierwotnego komunikatu, zyskujemy możliwość korygowania błędu transmisji. Odebrany komunikat „AniaAsiaAsia” niesie teraz informację o przekłamaniu na łączach, ale mimo jego wystąpienia odtwarzamy imię „Asia” jako pierwotny przekaz wysłany przez nadawcę.
Wszystko fajnie, lecz nasz kanał transmisyjny ma teraz 33% pierwotnej przepustowości. Czy da się osiągnąć lepszy wynik?
Bardziej zaawansowany przykład korekcji błędów
Problem napotkany w poprzednim przykładzie polegał na tym, że istniały pary imion które różniły się tylko jedną literką (Ania-Asia oraz Asia-Isia). Mówimy, że tzw. odległość edycyjna między tymi słowami wynosi 1. Zmodyfikujmy teraz imiona z naszego słownika tak, aby odległość ta wynosiła minimum 3. Transmitowane imiona będą wyglądały np. tak:
1Ania
A2sia
Is3ia
Maj4a
Gdy odebrany komunikat będzie zawierał zamieniony znak, nadal będziemy w stanie ustalić transmitowane imię. Tym razem długość komunikatu zwiększyła się jedynie o 25%, więc nasz kanał łączności zachował aż 80% pierwotnej przepustowości.
Kody Reeda-Solomona
Kody Reeda-Solomona to fajne matematyczne odkrycie (wynalazek?) dzięki któremu możemy generować metody kodowania odporne na tyle usterek, ile sobie zażyczymy. To właśnie dzięki tej właściwości możemy zestawiać macierze dyskowe, w których samodzielnie definiujemy liczbę dysków, których jednoczesna awaria nie doprowadzi do utraty danych (z jednym soczystym wyjątkiem dla dysków HPE, patrz przypis do tego tekstu).
Nie będę szczegółowo opisywał algorytmu Reeda-Solomona. Do zrozumienia potrzebna jest algebra na poziomie akademickim zaś opis dzielenia wielomianów i wyznaczania kolejnych reszt z tego dzielenia jest żmudny i zwyczajnie nudny. Ja nauczyłem się tego raz, na studiach informatycznych – i od tamtej pory nigdy nie przeprowadzałem tego typu obliczeń samodzielnie. Jak w przypadku większości problemów zahaczających o kodowanie i kryptografię – lepiej nie pisać takiego kodu samemu, lecz skorzystać z gotowych, wypróbowanych komponentów.
Jeśli jednak jesteś ciekaw, calutki proces obliczania kodów korekcyjnych znajdziesz tutaj, z rozpiską każdego kroku.

{kind=link}
Nam wystarczy na razie wiedza, że kody Reeda-Solomona to znana i szeroko stosowana metoda generowania komunikatów odpornych na zakłócenia.
Gdy mowa o korekcji błędów, trzeba wyjaśnić jedną rzecz. Algorytmy korekcji nie dostają informacji, które fragmenty wiadomości zostały uszkodzone. Spójrzmy na przykład – poniższe zdjęcie przedstawia kod QR wydrukowany na papierze, uszkodzony na środku i przylepiony do ceglanego muru. Człowiek patrzy na ten obrazek i dobrze wie, gdzie kończy się wiarygodna informacja a zaczyna dziura w papierze.

Gdy jednak odczytujemy maszynowo QR-kod ze zdjęcia, algorytm dekodujący dostanie mniej więcej taki zestaw informacji:

Jeśli gdzieś w odczytanych modułach są błędy, algorytmy korekcji muszą sobie z nimi poradzić samodzielnie, bez dodatkowych wskazówek. Ciekawostka – z protokołów uwzględniających korekcję błędów korzystają sondy kosmiczne, telewizja cyfrowa DVB czy… nośniki CD i DVD, dzięki czemu nawet porysowane płyty można z reguły odtworzyć bezbłędnie.
Poziomy odporności QR-kodów na uszkodzenia
Twórcy QR-kodów wzięli pod uwagę problemy, z którymi trzeba zmierzyć się podczas odczytu symboli z fotografii – jak niejednorodne oświetlenie, zniekształcenia perspektywiczne czy fizyczne uszkodzenia fragmentów obrazu. Treść umieszczana w obrazku jest więc wzbogacona o kody Reeda-Solomona, których rola jest dwojaka: służą po pierwsze do weryfikacji poprawności odczytu kodu, po drugie do korekcji ewentualnych błędów.
Standard określa cztery poziomy nadmiarowości – L, M, Q oraz H. Każdy kolejny pozwala na odzyskanie coraz większej części uszkodzonego QR-kodu, jednak dane korekcyjne zajmują coraz większą część zakodowanej wiadomości.
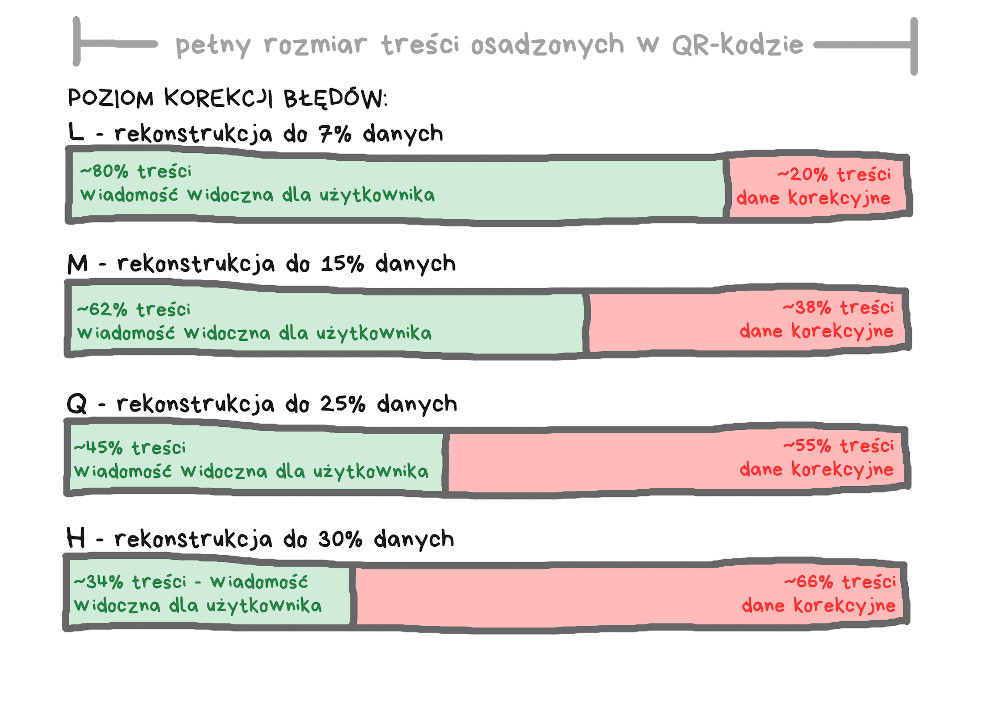
Powyższa ilustracja może wzbudzić wątpliwości – dlaczego poziom H pozwala na odzyskanie tylko 30% danych, skoro kody korekcyjne zajmują aż dwie trzecie całego przekazu? Przecież zamiast tego moglibyśmy umieścić pierwotną wiadomość w trzech kopiach, to chyba lepiej?
Takie myślenie jest błędne. Jeśli użylibyśmy trzech kopii wiadomości, to wystarczy uszkodzenie pierwszego znaku każdej kopii, by cały przekaz był nie do odzyskania. Kody Reeda-Solomona pozwalają na rekonstrukcję dowolnej części komunikatu, o ile tylko łączny procent uszkodzeń nie przekracza wcześniej ustalonego progu.

Wysoki poziom korekcji będzie pożądany wszędzie tam, gdzie QR-kody są narażone na uszkodzenie lub deformację. Gdy jednak założymy gwarantowaną jakość prezentacji, będzie nam zależało raczej na jak najniższej wersji kodu – wtedy modułów jest mniej i dekodowanie przebiega szybciej.
Pojemność QR-kodu
Ile danych możemy zmieścić w QR-kodzie? Zależy to bezpośrednio od wersji i rodzaju zawartości. Przykład – w kodzie o wersji 1 możemy zmieścić od 17 (korekcja H) do 41 cyfr (korekcja L), od 10 do 25 liter lub cyfr, lecz tylko od 7 do 17 bajtów.
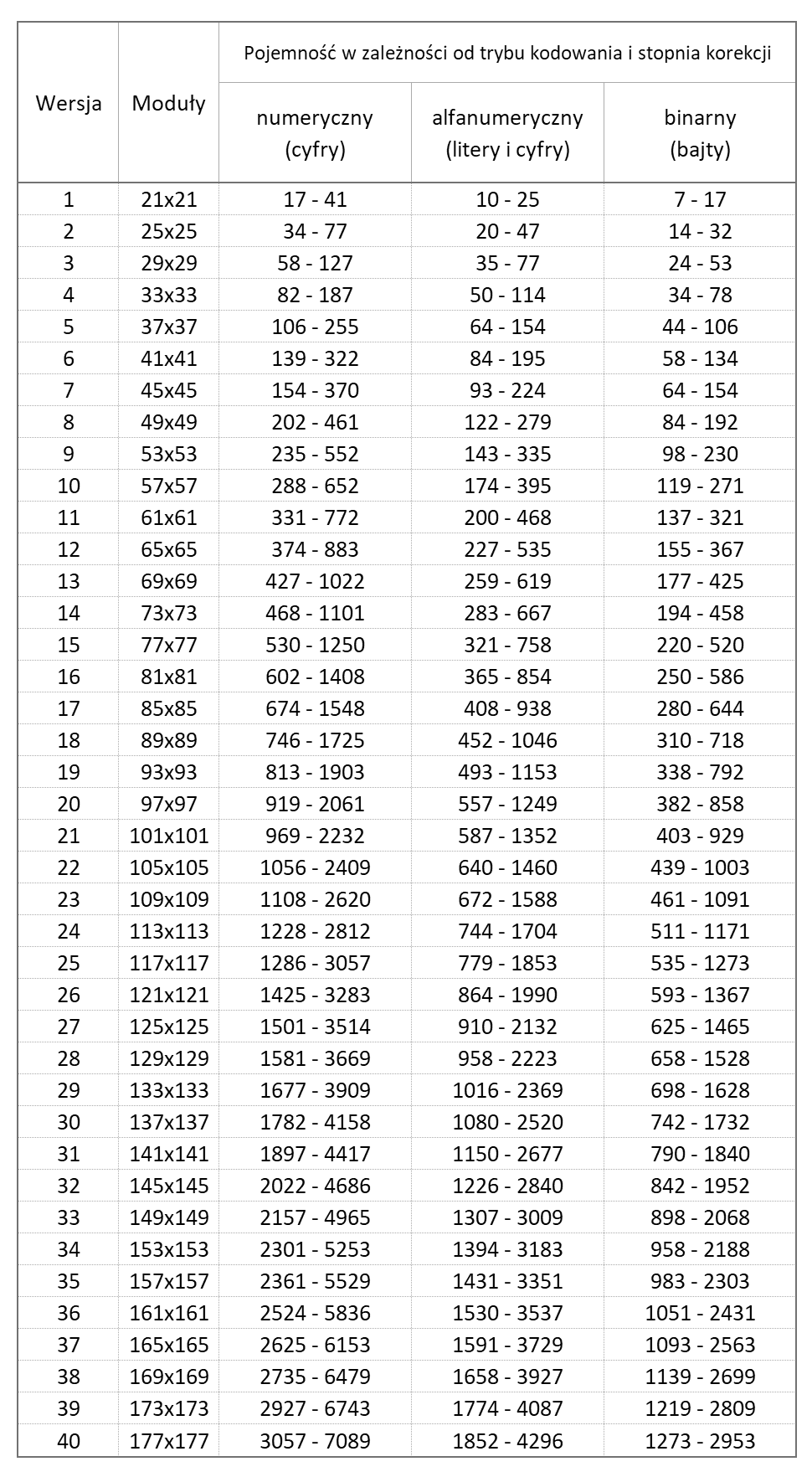
Co w sytuacji, gdy wiadomość zostanie zakodowana przy użyciu sekwencji należących do kilku różnych trybów? Obliczamy długość wynikowego ciągu bajtów i sprawdzamy w innej tabelce, jaka jest najmniejsza wersja kodu mieszcząca tę objętość (przy wybranym poziomie korekcji). Tabelkę znajdziesz kroku drugim przykładowych obliczeń.
Jak powstaje zawartość QR-kodu
Podsumujmy zgromadzone wcześniej informacje. Gdy tworzymy QR-kod, służące do tego oprogramowanie dostaje od nas dwa parametry – ciąg bajtów do zakodowania oraz stopień korekcji (od L do H). Następnie wykonywana jest następująca sekwencja działań:
- określany jest sposób kodowania zawartości – jeden z trzech trybów podstawowych (numeryczny / alfanumeryczny / binarny) lub tryb mieszany, łączący bloki kodowane w trybach podstawowych
- obliczana jest długość segmentu danych i wyznacza najmniejsza wersja kodu, w której przy obranym stopniu korekcji zmieści się segment owej długości
- segment danych uzupełniany jest zerowymi bitami do pełnego bajtu, następnie zaś naprzemiennie bajtami 0xEC oraz 0x11 aż do osiągnięcia rozmiaru właściwego dla użytej wersji QR-kodu (dopełnienie takie znane jest pod nazwą padding)
- segment danych wraz z paddingiem jest dzielony na bloki, których zawartość jest mieszana według określonych reguł – dzięki temu znaki (bajty) sąsiadujące w danych wejściowych są na obrazku oddalone od siebie (w kilku najmniejszych wersjach podział nie następuje, zamiast tego cały segment jest pojedynczym blokiem)
- do każdego bloku z poprzedniego punktu tworzony jest osobny kod korekcyjny Reeda-Solomona, kody również dzielone są na bloki, mieszane jak powyżej i dopisywane na końcu wyjściowego zestawu bajtów

Ciekawostka: ten kod zawiera jedynie literę „A” i ma wymuszoną ręcznie wersję 32 z niewielką (L) korekcją błędów. Powtarzalne wzory geometryczne zajmujące prawie cały QR-kod to sekwencje bajtów 0xEC oraz 0x11, stanowiące „wypełniacz” między sekcją danych a kodami korekcyjnymi.
Jak rysowany jest QR-kod
Wcześniej wspomnieliśmy, że stałe składniki QR-kodu mają swoje ustalone pozycje. Wiadomość, którą zakodowaliśmy zgodnie z regułami wspomnianymi przed chwilą, będziemy więc umieszczać bit po bicie w wolnych modułach, począwszy od prawego-dolnego rogu, zgodnie ze wzorem pokazanym na poniższych obrazkach.

Szczególne przypadki kodowania danych
Gdy patrzyliśmy na sposób kodowania liter (bajtów) przeznaczonych do umieszczenia w QR-kodzie, nie przejmowaliśmy się za bardzo ich graficzną reprezentacją. Okazuje się jednak, że w pewnych specyficznych przypadkach moglibyśmy otrzymać na wyjściu kody o dość niespodziewanej zawartości. Oto, jak wyglądałyby wiadomości złożone z setki bajtów z wszystkimi bitami wygaszonymi oraz zapalonymi

Algorytmy rozpoznające obrazy mają problem z dużymi, jednolitymi obszarami. Wiele programów ignoruje wspomniany wcześniej wzór synchronizacji rozciągnięty między wzorami pozycjonowania, zamiast tego wykrywa krawędzie oddzielające moduły czarne od białych, wyznacza siatkę „oczek” o maksymalnym kontraście i z nich czerpie informację o zerach i jedynkach. Gdy mówimy o rozpoznawaniu QR-kodu na fotografii, jednolite obszary mogłyby paść ofiarą algorytmów podbijających kontrast – zawczasu nie wiadomo bowiem, czy dany obszar jest jednobarwny, czy tylko słabo oświetlony.
Dygresja – brak wystarczającej zmienności danych wejściowych sprawiał problemy także w klasycznych dyskach twardych. Głowica HDD rozpoznaje zmiany pola magnetycznego na obracającym się pod nią talerzu. Już kilkanaście zer lub jedynek pod rząd skutkowałoby brakiem pewności, ile ich naprawdę przejechało. Kontrolery HDD stosują więc kodowanie RLL (i podobne), dzięki któremu w serii kilku bitów na pewno pojawi się zmiana wartości sygnału.
Nakładanie maski na QR-kody
Jak poradzimy sobie z problemem zbyt dużych, jednolitych obszarów? Moglibyśmy przekształcić treść do umieszczenia na obrazku którymś z wariantów kodowania RLL, to jednak zwiększyłoby jego rozmiar. Jeśli pomieszamy bajty/bity bez wydłużania wiadomości, zawsze będzie istniał wariant tekstu wejściowego, który sprawi problemy. Pat?
Twórcy QR-kodów wpadli na inny pomysł – bity danych rysowane na QR-kodzie poddawane są operacji XOR z maską, której zadaniem jest zwiększyć stopień „pomieszania” modułów. Operację bardzo łatwo odwrócić – wystarczy nałożyć na obrazek wynikowy tę samą maskę – wówczas otrzymamy obraz pierwotny.
Aby zwiększyć stopień pomieszania, za każdym razem wykorzystana będzie najlepsza z ośmiu dostępnych masek (w opisach formuły matematyczne, które na bazie numeru wiersza i kolumny określają zaczernienie modułu):
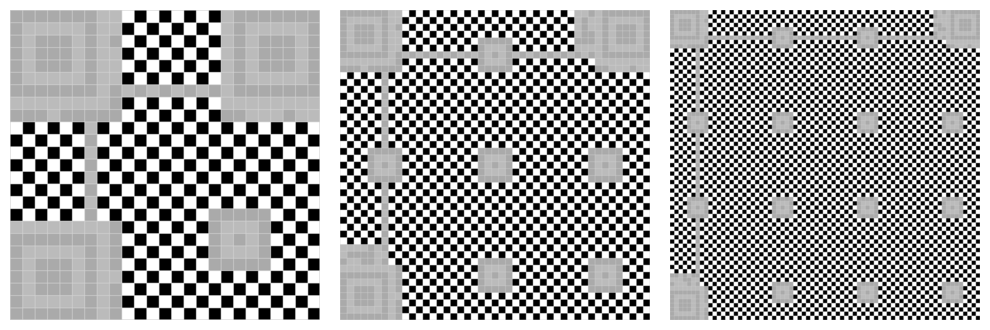
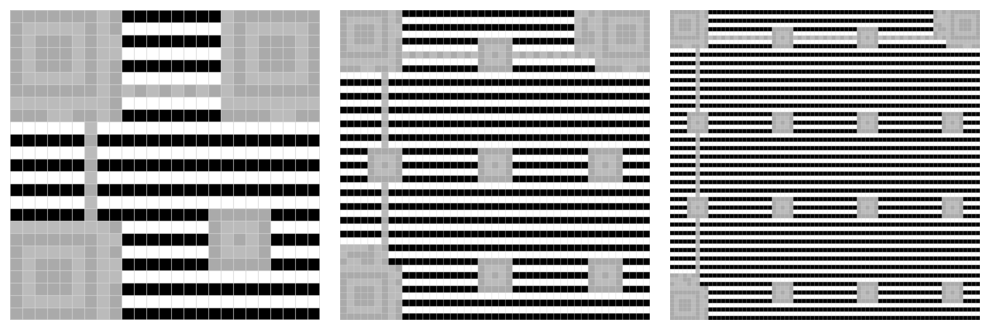
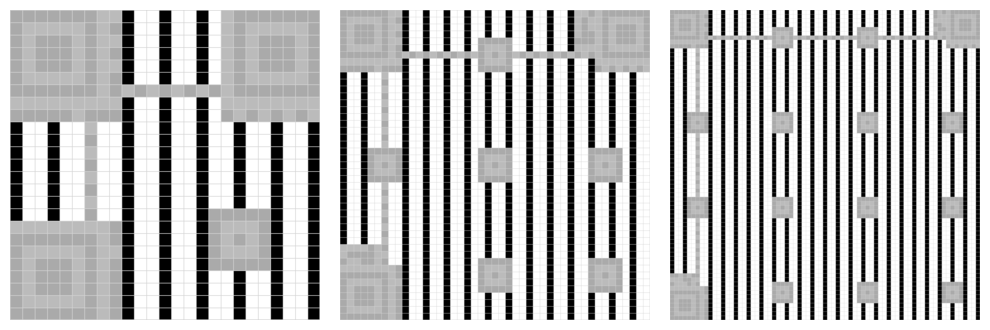
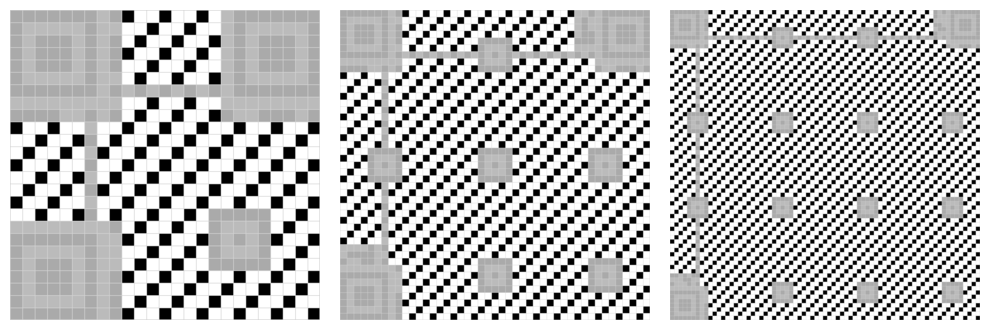
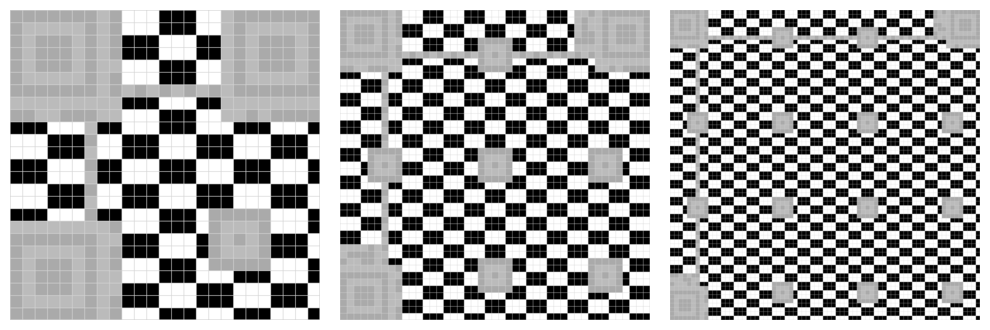
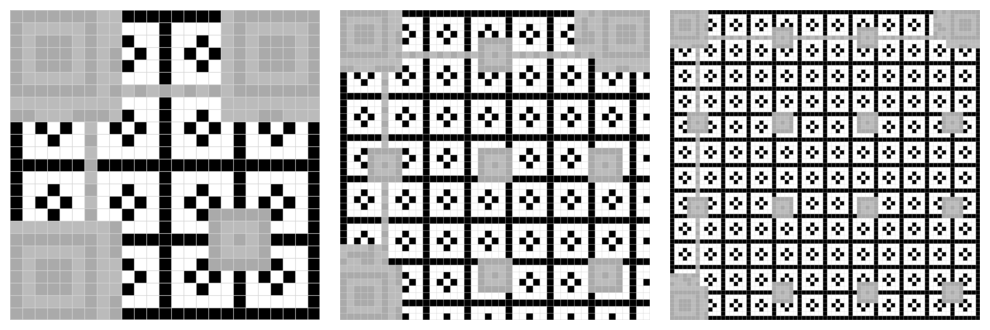
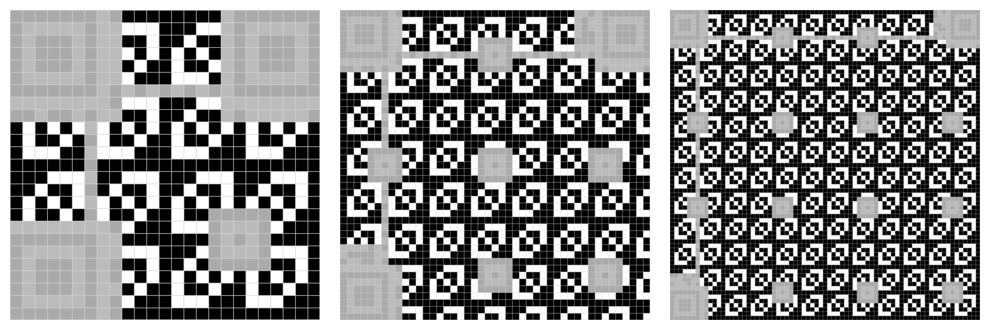

Numer użytej maski trafia do wzoru informacji o formacie. Pamiętacie, to te piętnaście pikseli leżących blisko wzorów pozycjonowania. Informacja o masce pojawia się na obrazku dwukrotnie a każda kopia jest opatrzona mocnymi kodami korekcyjnymi. I dobrze, bo jeśli przy dekodowaniu obrazka nie odczytamy poprawnego numeru maski, to pozamiatane.
Która maska jest najlepsza?
Oczywiście ta, która będzie zawierała najmniej fragmentów mogących sprawiać problemy. Nie chcielibyśmy przecież, aby gdzieś na środku pojawił się czwarty wzór pozycjonowania, prawda? Musimy wypróbować wszystkie osiem masek i wybrać tę, która zbierze najmniej punktów karnych.
Spójrzmy na ten sam QR-kod z maskami nr 1 i 2, policzymy punkty karne „na piechotę”.
Długie kreski w tym samym kolorze
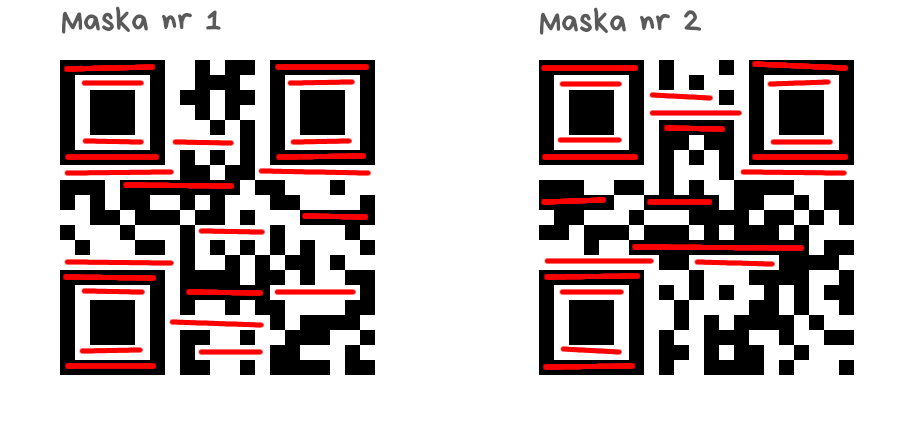
Każdy ciąg jednakowych modułów o długości 5 lub większej skutkuje punktami karnymi. Liczba punktów karnych to długość ciągu minus dwa (czyli ciąg o długości 5 to trzy punkty karne, o długości 6 to cztery punkty karne itd.). Liczymy wyłącznie obszar ograniczony przez obrys wzoru synchronizacji (bez białej obwódki)
Maska nr 1 – 176 punktów karnych
Maska nr 2 – 178 punktów karnych
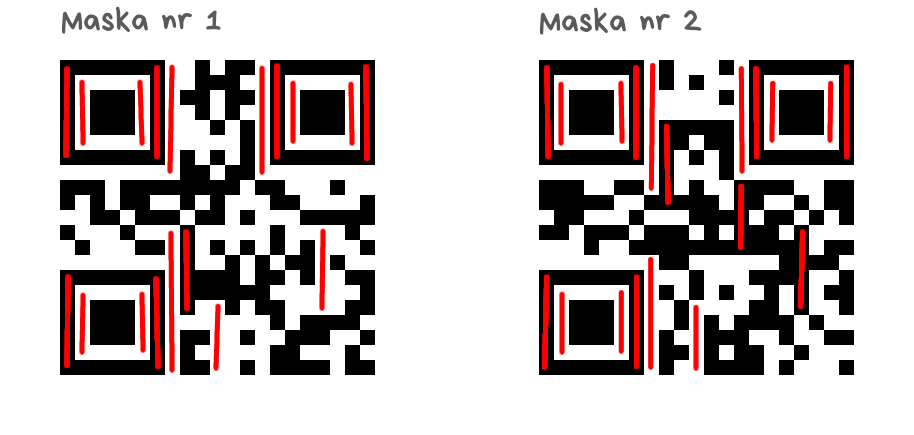
Kwadraty 2×2
Każdy jednokolorowy kwadrat o boku 2×2 to trzy punkty karne. Kwadraty mogą się nakładać, białej obwódki nie liczymy.
Maska nr 1 – 117 punktów karnych
Maska nr 2 – 126 punktów karnych
Fragmenty wzoru synchronizacji
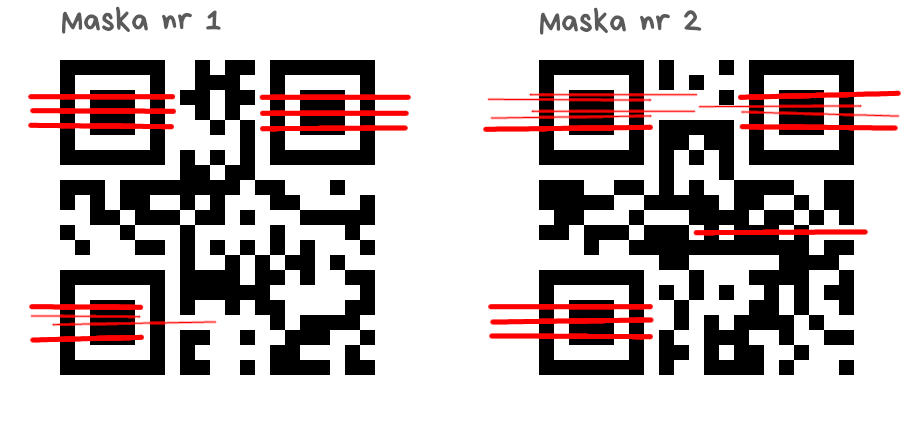
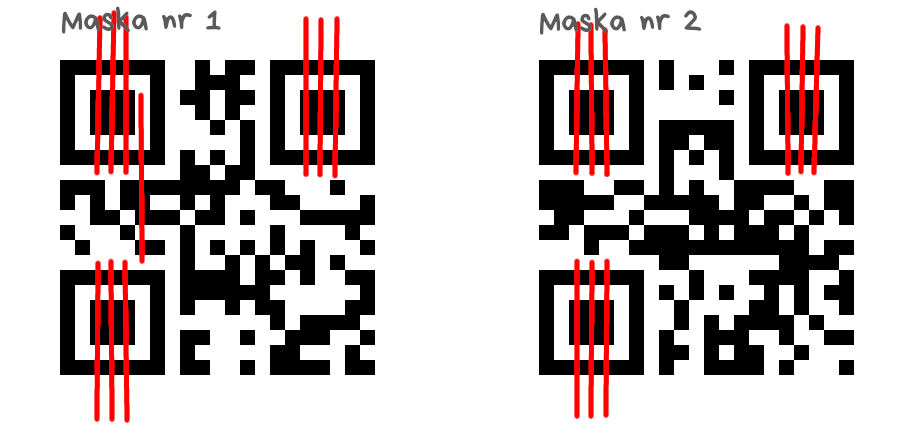
Czterdzieści (!) punktów karnych za każdy ciąg CBCCCBCBBBB lub BBBBCBCCCBC (B=biały, C=czarny), pionowo i poziomo, ciągi mogą się nakładać, uwzględniamy białą obwódkę.
Zbalansowanie bieli i czerni
Punkty karne za niedostateczny balans między modułami białymi i czarnymi. Liczymy, jaki procent wszystkich modułów stanowi kolor dominujący (białe obwódki ignorujemy). Jeśli mniej, niż 55%, nie ma punktów karnych. Za każde pełne 5 punktów procentowych ponad 50% – dziesięć punktów karnych (np. 57% – 10 punktów, 62% – 20 punktów, 77% – 50 punktów karnych itd.)
W naszym przypadku punktów za niezbalansowanie brak.
Wynik
W pojedynku opisanym wyżej wygrywa maska nr 1 przed maską nr 2 (1093 kontra 1184 punkty karne), ale spośród wszystkich masek najlepsza jest maska nr 8 (1002 punkty karne).
Samodzielne eksperymenty tradycyjnie na tej stronie, kary i obliczenia pokazane są w krokach 8 i 9. Na dole strony podlinkowany jest jej kod źródłowy napisany w TypeScripcie.
Jakiego typu zawartość można umieścić w QR-kodzie?
Ta informacja pojawiła się już w tekście wielokrotnie – QR-kod może zawierać dowolny ciąg bajtów. To, jak odczytaną zawartość zinterpretuje czytnik, to zupełnie inna sprawa.
Niestety, standard ISO/IEC 18004:2015 opisujący QR-kody nie podaje żadnej interpretacji zawartości zakodowanego komunikatu. Aplikacje dekodujące mogą więc, lecz nie muszą, pomóc użytkownikowi w oparciu o swobodnie dobrany zestaw heurystyk.
Oto kilka popularniejszych interpretacji:
- ciągi znaków zaczynające się od
http://albohttps://z reguły służy jako adres URL w przeglądarce
- ciągi znaków mające formę
tel:+48124420244można często wybrać jako numer telefonu
- ciągi znaków mające formę
geo:51.107883,17.038538mogą służyć jako współrzędne geograficzne pokazywane na mapie
Są i bardziej złożone przykłady, jak wpisy do kalendarza w standardzie VEVENT albo wizytówki w formacie VCard.
Brak standaryzacji sprawia jednak, że zachowanie różnych aplikacji będzie odmienne – np. jedna użyje całego tekstu po http:// jako adresu URL, kodując niedozwolone znaki, inna zaś zakończy interpretację URL-a na pierwszym niedozwolonym znaku.
Tworząc QR-kod nigdy nie mamy pewności, co z jego treścią zrobi aplikacja użytkownika.
Czy QR-kod może być niebezpieczny?
Tak. I nie.
Tak, bo w szczególnych sytuacjach treść odczytana z QR-kodu może ominąć mechanizmy walidacji i weryfikacji, trafiając tam, gdzie nie powinny docierać dane pochodzące z zewnątrz systemu.
Nie, bo kody QR to jedynie sposób kodowania jakiegoś ciągu bajtów w formie obrazka. Dopiero zeskanowanie kodu niedoskonałymi narzędziami w podatnym na błędy środowisku może doprowadzić do niepożądanych zachowań.
Oto kilka przykładów z życia
Fabryczny reset telefonów marki Samsung
Dawno, dawno temu w telefonach marki Samsung aplikacja do telefonowania automatycznie aktywowała kody USSD przekazane przez inne aplikacje. Na przykład z czytnika QR-kodów albo czytnika tagów NFC. Jednocześnie jeden z kodów USSD służył do przeprowadzania fabrycznego resetu urządzenia a po jego wpisaniu nie padało pytanie o potwierdzenie operacji.
Efekt – skanujesz QR-kod i bęc, w tej samej sekundzie tracisz całą zawartość telefonu. W roku 2012 było o tym głośno i całkiem możliwe, że owa podatność ograniczyła popularyzację tagów NFC.
XSS w mobilnym Firefoksie
Ta podatność nie ma jeszcze roku – odkryto ją w grudniu 2019. Czytnik QR-kodów w mobilnej przeglądarce Firefox umożliwiał przekazanie do przeglądarki poleceń Javascript odczytanych z QR-kodu – były one uruchamiane w kontekście bieżącej witryny, co pozwalało atakującemu np. na przejęcie sesji zalogowanego użytkownika.
Najprostszym wariantem demonstrującym podatność był QR-kod o treści javascript:alert(document.body.innerHTML);
QR-kody – arlekiny
Nie jest to bezpośredni atak, lecz demonstracja, że czytniki QR-kodów idą w heurystykach podnoszących skuteczność odczytu co najmniej jeden krok za daleko. Z tego powodu stają się podatne na sztuczki, które w normalnych warunkach nie byłyby możliwe.
W swojej publikacji „On Double-Sided QR-Codes“ Alexey Tikhonov podaje sposób na takie spreparowanie QR-kodu, by w lustrzanym odbiciu również dawał się odczytać lecz zawierał inną treść.
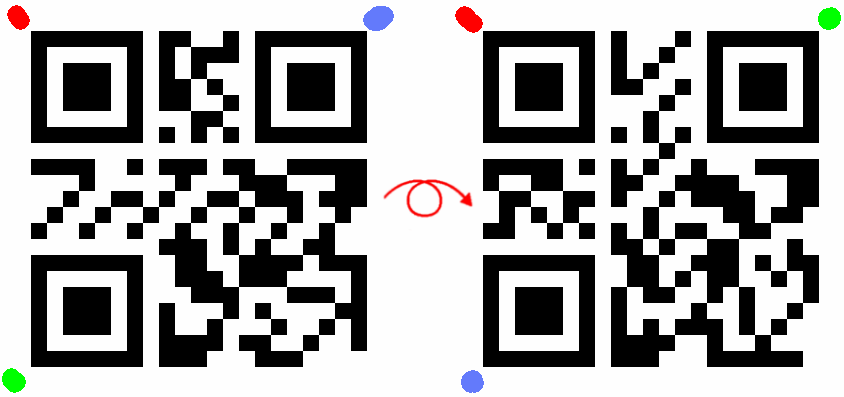
Gdy czytnik pozwala na odczyt kodu sfotografowanego od tyłu (np. przez szybę), efektem będzie taka sytuacja, jak na obrazku poniżej. Ten sam kod skanowany raz za razem będzie losowo rozpoznawany jako jeden z dwóch napisów: HARRY lub BOVIK.

A co z kolorowymi QR-kodami?
Nie przyjęły się z prostego powodu – przynoszą niewiele korzyści, dramatycznie obniżają pewność odczytu. Poniżej przykład sklejenia trzech QR-kodów w jeden wynikowy kod, którego nie odczytamy w słabszych warunkach albo przy kolorowym świetle.
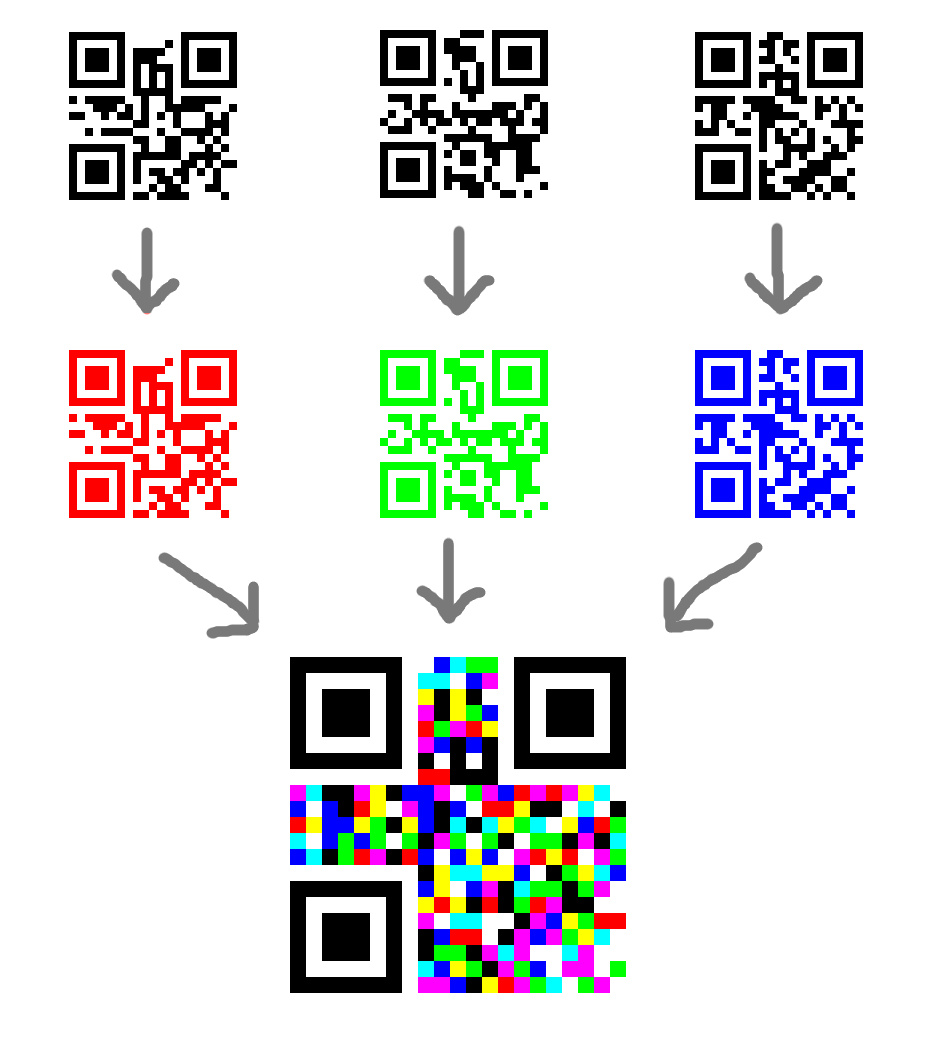
Zamiast kolorów moglibyśmy używać odcieni szarości, ale nadal n-krotne zwiększenie pojemności będzie wymagało rozpoznawania 2n różnych odcieni.
Tutaj możemy pobrać pracę opisującą kilka różnych podejść do kolorowych QR-kodów i wady oraz zalety każdego z nich.

Dość egzotycznym pomysłem jest drukowanie QR-kodów farbami świecącymi w świetle ultrafioletowym. Oto przykład drukowania trzech QR-kodów na sobie – jeden widzialny, dwa wzbudzane różnymi częstotliwościami UV.
Czy QR-kody pozwalają na archiwizację danych cyfrowych na wydrukach lub mikrofilmach?
Tak, ale umówmy się, że od epoki kart tekturowych i taśm perforowanych nikt nie robi tego na serio. Gdyby jednak ktoś chciał archiwizować dane na papierze, lepiej użyć formatu potrafiącego przyjąć na raz więcej danych, niż QR-kody. W optymalnych warunkach kartka A4 pomieści jakieś pół megabajta danych.
Działające oprogramowanie do archwizacji na papierze i odtwarzania danych ze skanu można znaleźć tutaj: ollydbg.de/Paperbak/

Różne różnostki
Kilka ciekawostek, na które trafiłem podczas przygotowania tekstu
Hybryda
Niektóre kody dwuwymiarowe różnych typów można połączyć w jeden. Na obrazku hybryda złożona z kodów QR oraz Aztec.

Gra dla Windows w QR-kodzie
Ta historyjka bardziej opowiada o tym, jak zmieścić prostą grę w bardzo małym pliku wykonywalnym, no ale na końcu trafia on na drukowany QR-kod i jest z sukcesem wciągany z powrotem na dysk.
Eksperymenty ze wzorami na QR-kodach
Tutaj krótkie eksperymenty pokazujące, że gdy chcemy wstawiać w QR-kod jakiś obrazek, to część pikseli będzie już zapalona/zgaszona zgodnie lub prawie zgodnie z naszymi oczekiwaniami. Wówczas wystarczy zająć się tymi, które najbardziej zaburzają osadzane kształty.

Cała Wikipedia w jednym QR-kodzie
Rozważania (po angielsku), jak duży musiałby być QR-kod, by zmieścić tekst całej Wikipedii. Spoiler: kwadrat o boku 27 kilometrów.
Przemycanie tajnych informacji w korygowanych błędach QR-kodów
Pomysł znalazłem w tym artykule. Steganografia jest tu realizowana w następujący sposób – tworzymy kod QR, bierzemy sekretną wiadomość, osadzamy ją uszkadzając (odwracając) pewną liczbę modułów tego kodu, gotowe.
Odbiorca sekretnej wiadomości bierze kod, odczytuje go (algorytmy korekcji naprawiają błędy), koduje ponownie – teraz sprawdza różnice między kodem odebranym a naprawionym i otrzymuje sekretną wiadomość.

Magiczne przekierowania
Czasem spotykamy się z sytuacją, gdy ten sam QR-kod służący do pobierania aplikacji działa na obu platformach mobilnych – Androidzie oraz iOS. Nie ma w tym żadnej magii – zakodowany URL prowadzi do strony, która na podstawie nagłówków z żądania HTTP rozpoznaje system operacyjny urządzenia i dokonuje przekierowania na adres odpowiedniego sklepu z aplikacjami.
Jak ocenić jakość bibliotek rozpoznających QR-kody?
Tylko i wyłącznie eksperymentalnie. Oto przykładowe badanie – twórcy biblioteki BoofCV zebrali kilkaset zdjęć QR-kodów stanowiących wyzwanie dla algorytmów, pogrupowali je w kilkanaście kategorii (rozmyte, uszkodzone, niejednorodnie oświetlone, obrócone, powielone itd.) i przy ich użyciu porównali swój produkt z najważniejszymi konkurentami (w tym OpenCV, ZBar i ZXing).

Z wynikami można zapoznać się tutaj. BoofCV był najdokładniejszy, ZXing najbardziej tolerancyjny dla kodów nie trzymających się specyfikacji. Na YouTube można znaleźć film demonstrujący wyzwania, z jakimi trzeba się mierzyć podczas rozpoznawania QR-kodu (od 4:30).
Jak maszyny rozpoznają QR-kody?
Ha! Pytanie o pojemności oceanu. Komputerowe rozpoznawanie obrazu jest tematem niezliczonych prac naukowych. No dobra, zliczonych. Google Scholar pod hasłem „qr code recognition” zwraca 68 tysięcy wyników.
Przekartkowałem kilkadziesiąt publikacji i efekt jest taki, że nie podejmuję się streszczenia metod wykrywania i odczytu QR-kodów, bo jest ich po prostu zbyt wiele. Zazwyczaj można w nich wyróżnić następujące kroki:
- wykrycie wzorów pozycjonowania
- wykrycie pozycji i wersji QR-kodu, wraz z rozmiarem, obrotami, deformacjami i zniekształceniami perspektywicznymi
- binaryzacja obrazu czyli oddzielenie obszarów jasnych od ciemnych
- identyfikacja koloru pojedynczych modułów i próba odczytu treści danego kodu
Wszystkich zainteresowanych tematem (i znających angielski) zachęcam do samodzielnego wyszukiwania odpowiednich publikacji lub zapoznania się z kodem źródłowym istniejących bibliotek. Poniżej na zachętę wklejam kilka ciekawszych ilustracji z prac opisujących różne etapy przetwarzania obrazu i wykrywania QR-kodów.
A jeśli ktoś nigdy nie słyszał o SciHub, to już słyszał.

źródło: Dubská, M., Herout, A. & Havel, J. Real-time precise detection of regular grids and matrix codes. J Real-Time Image Proc 11, 193–200 (2016).

źródło: Dubská, M., Herout, A. & Havel, J. Real-time precise detection of regular grids and matrix codes. J Real-Time Image Proc 11, 193–200 (2016).

źródło: Derek Bradley & Gerhard Roth (2007) Adaptive Thresholding using the Integral; Image, Journal of Graphics Tools, 12:2, 13-21

źródło: Karrach, L.; Pivarčiová, E.; Božek, P. Identification of QR Code Perspective Distortion Based on Edge Directions and Edge Projections Analysis. J. Imaging 2020, 6, 67.
Licencja na obrazki z tego artykułu
Wszystkie obrazki w niniejszym tekście, które nie mają podanego źródła, są mojego autorstwa. Przekazuję je do domeny publicznej, co nie jest w Polsce tak całkiem możliwe, więc w razie potrzeby deklaruję objęcie tychże obrazków licencją CC0 1.0 Universal. Oczywiście linkowanie do źródła i podanie autorstwa jest nadal bardzo mile widziane.
Tekst artykułu nie jest objęty wolną licencją. Jeśli chcesz go użyć w sytuacjach przekraczających dozwolony użytek, daj mi znać.
A jeśli chodzi o same QR-kody, to nazwa jest znakiem towarowym japońskiej firmy Denso Wave, lecz używanie kodów nie wymaga zgody ani licencji.
Czasem pojawia się pytanie, jak można zmodyfikować QR-kody, żeby działały jak „prywatny” nośnik informacji, niekompatybilny z istniejącymi czytnikami. Najprościej jest zmodyfikować albo zmienić kolejność stosowanych masek, lecz uwaga – w ten sposób można wejść w konflikt z Denso Wave, bo firma ta zrzeka się praw licencyjnych jedynie w odniesieniu do QR-kodów trzymających się oryginalnej specyfikacji ISO/IEC 18004:2015.
Oprogramowanie, którym tworzyłem obrazki i animacje
Do przygotowania prawie wszystkich ilustracji użyłem biblioteki QRCoder pozwalającej na generowanie QR-kodów w języku C#. To fajna biblioteka, bo:
- oddziela proces generowania QR-kodu od jego renderowania (rysowania)
- ma wiele różnych mechanizmów rysowania gotowego QR-kodu, w tym tworzenie obrazków ASCII, bitmap w pamięci, plików graficznych rastrowych i wektorowych
- ma zestaw klas pomocniczych do generowania zawartości QR-kodów takich typów, jak wydarzenia z kalendarza czy dane dostępowe sieci WiFi
Jedyne, czego mi brakowało, to możliwość swobodnego żonglowania kolorami, więc zrobiłem własną kopię (fork) projektu i dopisałem mechanizm kolorowania. Wszystkie zmiany są zrobione na szybko i na brudno, ale spełniły swoje zadanie. Oczywiście całość zmian jest objęta licencję MIT.

Obrazy łączyłem i obrabiałem oprogramowaniem ImageMagick, animacje powstały przy użyciu FFmpeg.
Zakończenie
Skoro czytasz te słowa, to artykuł naprawdę cię wciągnął. Cóż, nie jestem zdziwiony, ja świetnie się bawiłem pisząc go. Oczywiście QR-kody nie wyczerpują tematu kodów dwuwymiarowych. Jeśli chcecie przeczytać artykuł o innych standardach, napiszcie mi to w komentarzu pod tekstem.

Przygotowanie takiego artykułu to kilka tygodni pracy, więc nie pojawiają się one jakoś strasznie często. Mam prośbę – zapisz się na newsletter. Obiecuję nie przeginać, dostaniesz jednego maila co kilka tygodni. Subskrypcja będzie dla mnie potwierdzeniem, że podoba ci się moja twórczość i warto pisać dalej. Lajki i suby na social mediach przychodzą i odchodzą a lista mailingowa trwa. Dzięki!
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

32 odpowiedzi na “Więcej, niż chcieliście wiedzieć o QR-kodach”
Czekam na następny odcinek 🙂
Następny Aztec?
„Łał”! Dobry artykuł w czasach, w których króluje skrótowość i „chodzenie po łebkach”.
Podziwiam ilość czasu, jaką musiałeś poświęcić na zebranie materiałów do artykułu. Naprawdę: szacunek.
super ! dzięki : )
Super! Również czekam na ciąg dalszy 😀
Dziękuję za wspaniały opis QR, widziałem na Twoim twitterze że bierzesz się za temat, ale rozmach z jakim to zrealizowałeś powala. Dzięki!
Świetna robota. Czekamy na kolejne artykuły 🙂
Kawał rzetelnej wiedzy jasno opisany.
Jakosci przekazu mogliby sie uczyc niektorzy wykladowcy.
Swietny artykuł!
Bardzo chciałbym przeczytać taki dokładny opis dla Data Matrix i może jakieś porównanie który lepszy/gorszy
Wyczerpująco super
Dopiero teraz trafiłem na ten artykuł i nie żałuję poświęconego czasu na przeczytanie. A chciałem posiąść jakąś wiedzę na ten temat, ponieważ trafiłem na aplikację, która umożliwia płatności w sklepach za pomocą kodu QR. To Startup, który się nazywa PaySperience. Zastanawiam się na ile to jest bezpieczne i sprawne w wymianie płatności. Ponoć w Chinach to jest na porządku dziennym, a w Polsce to chyba nowość.
Komć żebyś wiedział że robisz dobrą nieulotną robotę, THX
Wchodzę w newslettera bo za rzadko pojawiasz się w moim otoczeniu a warto Cię czytać
super – czekam na więcej na temat kodów dwuwymiarowych 🙂
dodałbym informację o licencjonowaniu samych QR. czy ich używanie jest za darmo. czy są objęte jakąś licencją.
Jeśli wiesz a nie chcesz aktualizować artykułu będę wdzięczny za taką informację na privie.
Ogólnie super.
Licencja jest darmowa, jeśli używasz QR-kodów zgodnych z oryginalną specyfikacją (czyli nie zmieniasz sposobu kodowania, masek itd.). W przeciwnym razie musisz kontaktować się z Denso Wave, albo ktokolwiek jest teraz właścicielem patentów.
Bardzo dziękuję, za możliwość zapoznania się ze świetnym artykułem. Wielki szacunek za podejście do tematu.
Dobry wieczór
Czy orientuje się pan jakie można napotkać problemy przy wyświetlaniu qr kodów na ekranach z wysoką rozdzielczością lub powiększeniem czcionek przy 175%?
QR-kody to bitmapy, powiększanie czcionek nie powinno mieć wpływu na wyświetlanie obrazków na ekranie. Na ekranach o większej gęstości pikseli obrazek wyświetlany 1:1 będzie mniejszy. Co do zasady – jeśli człowiek rozpoznaje wzrokiem trzy narożniki QR-kodu, to maszyna też powinna dać radę
Mam pytanie do eksperta o kod QR w paszporcie covidowym? Jakie dane tam są zaszyfrowane? Jak można to sprawdzić? Czy to są dane z jakiegoś systemu/bazy danych czy suche dane osobowe zaszyfrowane qr kodem?
Tutaj jest o tym osobny artykuł: https://informatykzakladowy.pl/co-zawieraja-qr-kody-w-unijnym-certyfikacie-covid-i-jak-to-sprawdzic/
Dzięki za dosyć wyczerpujący materiał i szacun za włożoną pracę.
Idąc o krok dalej mam pytanie czy są aplikacje, które zapisują dane z kodu QR – np. po zeskanowaniu kodu aparatem telefonu, informacje w nim zawarte są przekazywane zapisywane w bazie danych/pliku (Excela?) w jakiejś chmurze? Czy może coś takiego już funkcjonuje?
Możesz to sobie wystrugać samemu za pomocą IFTTT albo Integromatu – https://trevorfox.com/2015/09/qr-codes-scan-to-vote-app-ifttt-google-sheets/, https://www.integromat.com/en/integrations/barcode itd
Cześć,
świetny artykuł, dziękuję za włożoną pracę!
Mam pytanie, na które sam sobie odpowiedziałem. jednak chce się upewnić;
– Czy wygenerowany kod QR może w jakikolwiek sposób wygasnąć?
Sam QR kod jest sposobem szyfrowania i reprezentacji danych wiec stawiam, że nie jest to możliwe.
QR-kod to sposób zapisu cyfr, liter lub bajtów. Treść zakodowana jest raz na zawsze.
Jeśli w QR-kodzie będzie jakiś URL, to on oczywiście przy każdym załadowaniu w przeglądarce może pokazać co innego.
Takich ludzi jak Autor cenię bardzo.
Coś Cię interesuje, badasz temat, czytasz, dzielisz się wiedzą.
Jak mówią niektórzy (lewusy) – po co jeśli nikt Ci za to nie płaci?
Po to żeby nie siedzieć w jaskini! Bo można!
Bardzo szanuje !!!
Super artykuł. Chciałbym zautomatyzowac sobie w pracy pewne powtarzalne czynności, takie jak automatyczne uzupełnianie komórek w arkuszach google.
Czy jest możliwość wprowadzenia w kodzie QR niewidzialnych znaków z tabeli ASCII takich jak tabulacja pozioma czy znak nowej linii („enter”) w środku tekstu? (alt+009 i alt+013 nie działają)
I jeszcze jedno czy jest możliwość tym samym kodem qr sprawić aby wstawiała się data systemowa w jednej z komórek (chociaż to pewnie już jest funkcja samych arkuszy google)
Bardzo wnikliwy i obszerny artykuł! Dziekujemy!
Mam pytanie, tworzę kod QR, który ma mnie przekierować do grupy na FB – i tu pojawia się problem. Na iPhone kod działa bez zarzutu, kieruje prosto na grupę, jednak w telefonach z systemem Android ten sam kod kieruje tylko na własnego walla na Facebooku. Jaka może być tego przyczyna?
Hej! QR-kod to w tym przypadku tylko sposób zapisania linku. Jeśli go otworzysz w przeglądarce mobilnej, wszystko powinno działać jak należy. Jeśli jednak link otworzy mobilna aplikacja Facebooka, to ona zdecyduje co wyświetlić – w takim przypadku wina leży po stronie apki, nie QR-kodu.
Dzięki bardzo za odpowiedź! Problem jest taki, że 2 osoby z iphone sprawdziły i kod działa, a 4 inne z Androidem kod przenosi na walla na FB a nie na grupe 🙁
Czy jest jakis sposób, żeby wygenerować kod, który zadziała na wszystkich telefonach? (na komputerze kod śmiga).
Bardzo ciekawy artykuł, dzięki za włożoną w niego pracę. 🙂
Hej, nigdy nie trafiłem na artykuł który podlinkowałeś (kolorowe QRCody). A szukałem wnikliwie bo oparłem na tym pomyślę pracę inżynierską (z 2011 roku czyli już po jego opublikowaniu). Nie mam dostępu do artykułu ale u mnie z testów wyszło, że wydrukowane kolorowe kody działały istotnie gorzej ale już „aktywne” czyli wyświetlane na czymś potrafiły być lepsze. Pozdrawiam