
Fundacja Moje Państwo od roku 2017 walczy ze zmiennym szczęściem o ujawnienie algorytmu stojącego za Systemem Losowego Przydziału Spraw, programem komputerowym rozdzielającym sprawy sądowe między składy sędziowskie. Ministerstwo przez lata odmawiało jego publikacji, jednak w połowie września 2021 nagle poddało się – na stronie gov.pl umieszczono dokument o nazwie Algorytm_losowania_utworzony_na_podstawie_dokumentacji_analitycznej_v111.pdf, dostępny pod ścieżką Ministerstwo Sprawiedliwości → O ministerstwie → Informacje publiczne → Algorytm SLPS.
Czy rzeczywiście Ministerstwo ujawniło komplet informacji niezbędnych do odtworzenia sposobu działania kluczowego modułu systemu? A może ustępstwo było pozorne a my dostaliśmy zestaw niekompletnych i niespójnych informacji, które grają rolę listka figowego skrywającego nieprzejrzystość SLPS? Zapraszam do lektury mojej analizy dokumentu!
Wcześniejsze teksty o Systemie Losowego Przydziału Spraw
[2020-12-14] System Pseudolosowego Przydziału Spraw – opisałem problemy z SLPS i objaśniłem, dlaczego celowe błędy wpływające na działanie generatora liczb pseudolosowych mogą wyglądać tak, jak staranny kod niekompetentnego programisty
[2021-05-02] NIK o SLPS: Nie osiągnięto celów całego przedsięwzięcia – zestaw cytatów na temat SLPS z raportu Najwyższej Izby Kontroli
[2021-07-30] O algorytmach dla prawników – objaśniam krok po kroku, czym algorytm różni się od programu komputerowego i dlaczego bez dostępu do kodu źródłowego nie będziemy wiedzieć, czy pozornie poprawny program nie zawiera błędów
[2021-10-03] Poznaliśmy algorytm losowania SLPS czyli… co dokładnie? – oceniam, jaką wartość ma dokument udostępniony przez Ministerstwo Sprawiedliwości
[2022-01-14] Przejrzystość SLPS – duży krok do przodu – na stronach Portalu Sądowego pojawiła się wyszukiwarka raportów z losowań – niestety zabezpieczona mechanizmem reCAPTCHA
[od kwietnia 2024] Monitor SLPS – wpisy w serwisie slps.pl
[2025-01-09] Realny i najwyższy stopień zagrożenia – opinia do wyroku WSA oddalającego skargę na odmowę udostępnienia kodu źródłowego SLPS
Osoby spoza IT będą miały duży problem z lekturą i interpretacją wspomnianego tekstu. Każda branża ma swój własny slang, sposoby na organizację i utrwalanie wiedzy o wytwarzaniu produktów i prowadzeniu procesów. Bez wiedzy przedmiotowej nie sposób zorientować się, co jest mocnym kiksem a co wypełniaczem pozbawionym znaczenia.
Ja programuję etatowo już jakieś 18 lat, w tym czasie zdążyłem przeczytać setki dokumentów projektowych różnorakiej jakości (oraz samodzielnie popełnić pewną ich liczbę). Opiszę swoje wrażenia z lektury tekstu źródłowego, najpierw jednak troszkę teorii dla niezorientowanych w temacie.
W jaki sposób tworzy się dokumentację projektową oprogramowania?
Bez owijania w bawełnę? Często wcale.
Czemu? Cofnijmy się w czasie. Złożoność programów komputerowych od zawsze ograniczana była przez sprzęt – wydajność procesorów, pojemność nośników, rozdzielczość monitorów, rozmiary pamięci operacyjnej i tak dalej. Gdy sprzęt był coraz lepszy, programy stawały się coraz większe. Już 20-30 lat temu złożoność oprogramowania tworzonego na komputery mainframe była tak duża, że wiele nowo projektowanych systemów IT nigdy nie doczekało się wdrożenia. Dlaczego?

Kluczowe problemy nie zmieniły się po dziś dzień – nieumiejętność oszacowania pracochłonności, niewłaściwe modelowanie dziedziny, błędny wybór technologii, nieuwzględnienie uwag przyszłych użytkowników. We wspomnieniach post mortem często pojawia się także temat dokumentacji projektowej – im więcej tomów już istniało, tym więcej pracy trzeba było włożyć w choćby niewielkie zmiany. Dużo czasu i energii zabierało wersjonowanie dokumentów, synchronizacja zmian w dokumentacji z rzeczywistymi modyfikacjami oprogramowania i tak dalej. Wystarczy spojrzeć na listę znaczących nieudanych projektów w Wikipedii – niektóre z nich kosztowały miliardy dolarów, przekroczyły zakładany budżet dziesiątki razy a i tak na końcu wyrzucano całość do kubła.
Uruchomione projekty często miewały zbyt długi cykl wdrażania zmian, zakładający np. wydanie nowej wersji raz w roku. Lekko upraszczając można przyjąć, że główne etapy produkcji – projektowanie, programowanie, testowanie i wdrożenie – trwały wówczas po kwartale. Jeśli w połowie roku okazało się, że najbardziej potrzebne są inne funkcje, niż obecnie realizowane, najwcześniejszy możliwy termin ich dostarczenia wynosił 18 miesięcy.
W odpowiedzi na te problemy popularność zaczęły zdobywać tzw. metodyki zwinne, których głównym założeniem jest wprowadzenie bardzo krótkich iteracji, często dwu- lub trzytygodniowych. W każdym krótkim cyklu zespół realizacyjny dostarcza nową funkcję. Sponsor projektu może modyfikować priorytety zadań przewidzianych na kolejne cykle, więc nagłą zmianę zapotrzebowania da się ogarnąć nawet w miesiąc.
Gdy metodykę zwinną połączymy z architekturą mikroserwisów, zakładającą budowę wielu małych modułów rozwijanych i testowanych niezależnie, zapotrzebowanie na dokumentację możemy zredukować do minimum. Często zresztą jej spora część jest generowana automatycznie wprost z kodu źródłowego, co dodatkowo ułatwia zarządzanie wersjami.
Wróćmy jednak do SLPS. Nie da się ukryć, że tu jakaś dokumentacja jednak powstała. Jak duży jej fragment oglądamy? Albo bardziej ogólnie:
Jeśli dokumentacja jednak powstaje, to co zawiera?
Poniżej napiszę, jakiego rodzaju dokumentacji życzyłbym sobie w projekcie o rozmiarze i złożoności SLPS. Zaznaczam, że opis nie ma nic wspólnego z rzeczywistością – jest jedynie pomocą w rozumieniu niniejszego artykułu i stanowi projekcję mojego doświadczenia i myślenia życzeniowego. Taki właśnie zestaw chciałbym mieć przystępując do programowania lub próbowałbym wytworzyć, gdyby moją rolą było projektowanie.
Opisując poszczególne elementy pominę zastrzeżenia w rodzaju „często”, „czasem”, „niekiedy” czy „zazwyczaj” – dość powiedzieć, że w każdym projekcie będzie inaczej. Nie ma niestety branżowych reguł czy standardów dotyczących formy czy poziomu szczegółowości dokumentacji projektowej oprogramowania. Dobra, istnieje coś takiego, jak język modelowania UML i choć teoretycznie realizuje wiele zadań, to jednak w praktyce praktyka różni się od teorii a z całego UML-a najbardziej przydają się trzy albo cztery rodzaje diagramów.
Oto fikcyjne składowe dokumentacji SLPS, którą sobie wyobraziłem:
- Opis ogólny odpowiadający na pytania o powody i cele realizowane przez projektowane oprogramowanie. Coś w rodzaju „celem SLPS jest zwiększenie zaufania społeczeństwa do sądów poprzez zagwarantowanie całkowicie losowego przydziału składów sędziowskich do spraw” albo „celem drugorzędnym jest wyrównywanie obciążeń sędziów oraz dostarczanie ujednoliconych raportów o statystykach spraw w poszczególnych jednostkach”.
Tego typu opis pomaga wszystkim uczestnikom projektu skupić się na kluczowych aspektach systemu. W SLPS byłaby to przejrzystość losowania i niepodatność na manipulacje, co dałoby się zapewnić przez gwarancję rozliczalności działań użytkowników i użycie odpowiedniego źródła losowości. Do kluczowych aspektów nie będzie natomiast należeć dostosowanie interfejsu do urządzeń mobilnych ani gwarancja dostępności systemu przez 99.999% czasu.

- Słowniczek objaśniający pojęcia – świat wymiaru sprawiedliwości ma swój własny slang, niezrozumiały dla programistów. Dokumentacja powinna stosować wyłącznie pojęcia ze słowniczka aby terminologia była spójna w obrębie całego projektu. Dzięki temu nie będziemy musieli zastanawiać się, czy „koszt przypisania” jest tożsamy z „kosztem przydziału” i czym oba te koszty różnią się od „wskaźnika przydziału”.
- Analiza procesów czyli opis, jakie dane trafiają do systemu, jak są przetwarzane i co dzieje się z wynikami przetwarzania. Kluczowy jest precyzyjny opis nie tylko głównej ścieżki, ale wszystkich przypadków brzegowych. Mile widziany będzie dodatek z opisem mechanizmu ról i uprawnień oraz przypisanie procesów do ról.
- Schemat bazy danych czyli opis wszystkich typów obiektów (np. sąd, sędzia, sprawa, ławnik, losowanie, urlop) wraz z atrybutami (sędzia ma: imię, nazwisko, PESEL, bieżące obciążenie, przydział służbowy itd.) i łączącymi je relacjami (np. „sędzia ma urlop” albo „sędzia orzeka w wydziale”). Zdefiniowane tu więzy spójności bazy danych zapobiegną części błędów, np. PESEL sędziego określimy jako unikalny, więc ten sam nigdy nie pojawi się u dwóch sędziów. Typy pól też będą pomocne – jeśli liczba ławników jest wartością typu całkowitego bez znaku, to wykluczymy przypisanie do sprawy ujemnej liczby ławników. Czasem atrybutom zdefiniujemy dziedziny, np. wyszczególnimy wszystkie możliwe typy sądów.
- Projekt interfejsu użytkownika – menu głównego, sekcji, działów, okienek dialogowych, formularzy, zestawień; najlepiej z odwołaniami do systemu ról i uprawnień.
- (mile widziane) przypadki użycia czyli opisy interakcji i sekwencji działań, jakie muszą podjąć użytkownicy systemu by realizować od początku do końca typowe operacje.
Co dostaliśmy od Ministerstwa Sprawiedliwości i czy to rzeczywiście kompletny algorytm?
Dokument opublikowany pod nazwą Algorytm SLPS to fragment analizy procesów, wycięty z większej całości. Nie mamy do dyspozycji słowniczka, więc znaczenia wielu nazw musimy domyślać się z kontekstu. Nie mamy do dyspozycji opisu typów obiektów, więc nie wiemy, jakimi atrybutami charakteryzują się obiekty modelowane przez SLPS (sędzia, sprawa, losowanie itd.)
Nie upadajmy jednak na duchu, zamiast tego zastanówmy się, w jaki sposób możemy potwierdzić kompletność i poprawność algorytmu. Przypomnijmy sobie tekst „O algorytmach dla prawników” i objaśnianą tam różnicę między algorytmem a programem, w tekście wystąpił jeden algorytm i jego trzy implementacje (w językach Scratch, Basic, C#). Bingo! Jeśli będziemy w stanie napisać własny program, który – nakarmiony danymi wejściowymi – da taki sam wynik, jak SLPS, to będzie to dobry znak.
Tu pojawia się pierwszy problem: parametryzacja opisanych algorytmów. Niektóre wartości (np. liczbowe) nie są ustalone raz na zawsze, może modyfikować je administrator systemu. Przykład: parametr T decydujący, co ile losowań nastąpi balansowanie obciążeń składów trzyosobowych (str. 24). W wydziałach małych sądów może to być 5, w dużych 10, ale po pół roku ktoś może stwierdzić, że lepiej sprawdzą się wartości 6 i 9. A dodatkowo po tygodniu ów ktoś zmieni 9 na 11.
W rezultacie nie jesteśmy w stanie w sposób niezależny odtworzyć przebiegu algorytmu SLPS, jeśli nie znamy pełnego zestawu parametrów systemowych – te zaś mogą być zmieniane przez administratora w dowolnej chwili.
Drugi problem – luki w logice opisanego algorytmu. Na stronie 4 widzimy regułę R13 w której następuje sprawdzenie, czy sędzia był uprzednio wyłączony ze sprawy, w której następuje losowanie. Jeśli tak, ustawiany jest znacznik wyłączenia sędziego ze sprawy.
I teraz uwaga:
- to jedyne miejsce w którym pojawia się termin „znacznik wyłączenia ze sprawy”
- nie wiemy, w którym typie obiektów obecnych w systemie umieszczony jest taki znacznik ani jaki jest cykl życia tego obiektu (kiedy jest tworzony i kiedy znika)
- od tego znacznika nic nie zależy, tzn. nigdzie nie ma informacji, by na jego podstawie rzeczywiście usuwano wyłączonego sędziego z puli kandydatów (formalna specyfikacja nie działa w taki sposób, że jeśli nazwa parametru coś sugeruje, to odgadniemy o co chodzi i doprogramujemy to na boku)
Mamy więc tylko dwie możliwości – albo oprogramowanie zrealizowane według dostarczonego dokumentu nie będzie honorowało istniejących wyłączeń, albo też oprogramowanie realizuje algorytm odmienny od opisanego w dostarczonym dokumencie.
To może chociaż upewniliśmy się, że losowania SLPS są rzeczywiście losowe?
Temat źródła losowości skwitowano w dokumencie zwieźle: „Losowanie sędziego referenta dla sprawy odbywa przy wykorzystaniu generatora sprzętowego liczb”. Od razu pojawia się masa pytań i problemów. Przykład pierwszy z brzegu – nie wyspecyfikowano przedziału jaki przyjmuje wartość losowa i nie wiemy, czy zawsze jest wielokrotnością liczby sędziów. To ważne w świetle innego cytatu: „Generowana jest losowa liczba dla sprawy. Wygenerowana liczba dzielona jest modulo przez rozmiar puli losującej”.
Modulo to nic innego, jak reszta z dzielenia. Przykład: jeśli liczba losowa generowana zwykłą kostką do gry ma wartość od 1 do 6 a sędziów do losowania jest pięciu, to rzucając kostką i stosując operację dzielenia modulo mamy dwukrotnie większą szansę wylosowania pierwszego sędziego na liście (wynik 1 lub 6 na kostce) niż pozostałych (każdy z nich ma tylko jedną odpowiadającą mu liczbę oczek: 2, 3, 4 lub 5).
Albo rozwiązanie problemu znajduje się we fragmencie dokumentacji, który nie został udostępniony, albo też operacja dzielenia modulo będzie preferowała sędziego/sędziów z pierwszych miejsc listy. Teraz śmieszne spostrzeżenie – na liście sędziów do losowania, sędziowie delegowani z art. 77 par. 9 zawsze wskakują na początek listy (reguła R15, strona 5). Czemu? Nie jest to wyjaśnione w opublikowanym fragmencie dokumentacji.
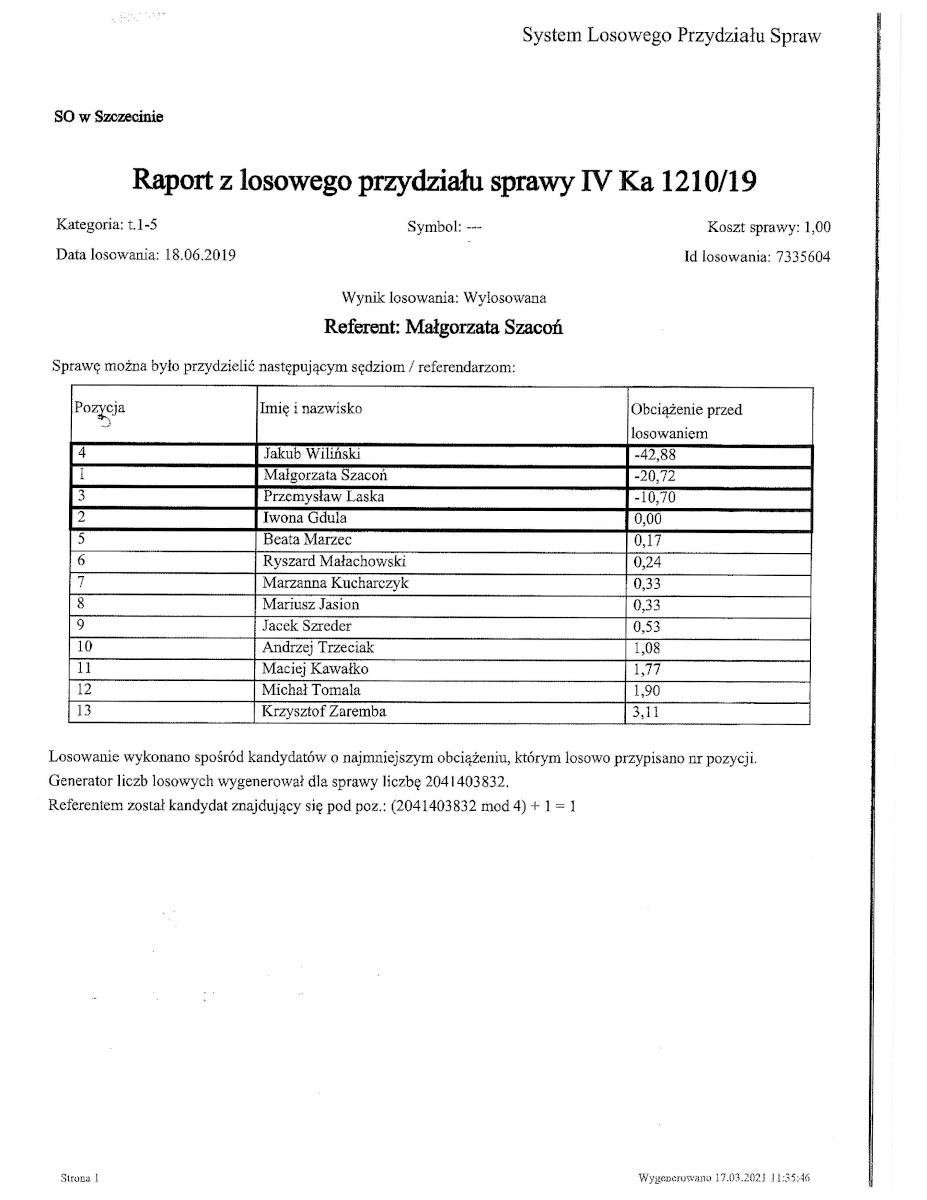
Jeśli spojrzymy na powyższy raport z losowania, zauważymy listę sędziów zakwalifikowanych do puli – nie widzimy jednak sędziów wykluczonych. Tymczasem powodów wykluczenia może być kilka, m.in. długi urlop, wyłączenia ze sprawy, ale także dokonywane przez administratora „wyłączenie [sędziego] z losowania” wszystkich spraw lub spraw danej kategorii.
Czy też widzicie tu ryzyko? Nie wiemy nic o tym, by SLPS – albo baza danych na której jest oparty – miały mechanizm zapisu logów i zdarzeń systemowych z aktywnym mechanizmem gwarantującym integralność i niezaprzeczalność. Nie wiemy też, kto i w jakim trybie może wyłączać sędziów z losowania, wiemy jedynie, że jest to uprawnienie „zarządzanie wydziałem” (R10, str. 4). Społeczna kontrola takiego rejestru zdarzeń zwyczajnie nie istnieje.
Gdyby na protokole była lista sędziów spoza puli wraz z adnotacjami o przyczynach wykluczenia, ręczna manipulacja w panelu administratora zostawiałaby widoczny na zewnątrz ślad. Tak nie jest – a możliwość arbitralnego usuwania dowolnego sędziego z losowania jest kolejnym powodem, dla którego nie da się sporządzić mechanizmu naśladującego w sposób niezależny działania SLPS przez dłuższy czas.
To ile w końcu jest tych losowań?
Spójrzcie jeszcze raz na przykładowy protokół z poprzedniego obrazka. Zauważcie, że czteroosobowa pula sędziów do losowania ma zmienione liczby porządkowe (kolumna „Pozycja”). Pierwotnie numerom 1-2-3-4 odpowiadało rosnące obciążenie sprzed losowania, jednak zgodnie z regułą R19 (str. 5) numeracja pozycji została pomieszana, wyszło 4-1-3-2.
Jeśli dobrze rozumiem regułę, każdemu z czterech sędziów z puli przydzielono osobną wartość losową i posortowano według nich liczby porządkowe, bez przestawiania wierszy. Ważne: te wartości nie są nigdzie rejestrowane, nie ma tu nawet pozorów przejrzystości. Następnie w kroku R22 obieramy jeszcze jedną wartość losową – to ona trafia na protokół oraz wyznacza (operacja modulo) sędziego do sprawy.
Z punktu widzenia matematyki nie ma to żadnego sensu. To nie jest odpowiednik lepszego mieszania piłeczek w maszynie losującej Lotto, takie przestawianki w najmniejszym stopniu nie „poprawią” ani nie „wzmocnią” losowości. Jest to zaś kolejne miejsce w systemie, którego działania nie jest w stanie prześledzić zewnętrzny obserwator.
Po lekturze tych fragmentów drapiemy się w głowę
Kolekcja „michałków” znalezionych w tekście, trochę śmiesznych a trochę strasznych, bo obnażających niską jakość projektu:
Strona 2: „Do listy potencjalnych dat startowych dla sędziego dodawana jest data określona przez wartość zmiennej 'HolidaysFrom’ z pliku konfiguracyjnego aplikacji. […] Jako data startowa dla sędziego wybierana jest najpóźniejsza z potencjalnych dat startowych dla sędziego”. Yyyyy? Czy każdy sędzia ma swój „plik konfiguracyjny” z urlopami? A może jest to plik z definicjami dni świątecznych? Jeśli jest to ta druga opcja, to każdy sędzia będzie miał identyczną datę startową, zapewne przyszłoroczne Boże Narodzenie.
Reguła R17, strona 5: „Jeżeli liczba sędziów biorących udział w losowaniu wynosi 2, tworzony jest wirtualny kandydat poprzez zduplikowanie pierwszego sędziego z utworzonej w poprzednim kroku listy”. Yyyyy? Dlaczego nie może być dwóch sędziów? Po takim zduplikowaniu szansa na wybór wynosi 2 do 1 na rzecz pierwszego sędziego! Jeśli z dowolnego powodu potrzebnych jest co najmniej trzech sędziów, to czemu nie zduplikować obu wpisów? To zachowałoby równe szanse. Niestety – ani słowa wyjaśnienia.

Reguła 32 ze strony 7 jest zbędna. Podstawa normalizacji nigdy nie będzie ujemna, bo w regule 31 wybieramy ją spośród wartości równych lub większych od zera.
Te fragmenty brzydko pachną
Czasem patrzymy na kod źródłowy lub dokumentację i czujemy, że coś w projekcie śmierdzi (tak, code smell to naprawdę fragment slangu). Niniejszy rozdział to 100% moich subiektywnych opinii na temat raczej architektury SLPS niż algorytmu przydziału. Chcę jednak pokazać osobom spoza IT, że między wierszami daje się czasem wyczytać trochę dodatkowych informacji.
R23, strona 6 – dokument analityczny opisujący proces znienacka objaśnia dziedziny pól w bazie danych. Drobiazg, ale takie mieszanie warstw abstrakcji czasem oznacza braki w projekcie technicznym albo niepotrzebne dublowanie informacji.
R24-25, strona 6 – tu nawarstwia się kilka problemów.
- dokument analityczny opisujący proces losowania nie powinien zawierać opisu naprawy usterek w bazie danych. Akcja serwisowa powinna być opisana gdzie indziej, przeprowadzona raz, zakończona i zapomniana. W przeciwnym razie do końca świata trzeba będzie pamiętać, które kroki procesu były ważne tylko przez kilka miesięcy iks lat temu.
- sam proces naprawy powinien być przetestowany na replice bazy danych i wdrożony w jeden weekend; utrzymywanie różnic w metodologii liczenia obciążeń dopóki każdy z sędziów w Polsce nie wylosuje nowej sprawy brzmi jak temat, który nigdy się nie skończy i nie pozwoli na realizację spójnej sprawozdawczości
- nazywanie „nowym mechanizmem” czegokolwiek w dokumencie projektowym przywodzi na myśl program „Nowe Gadu-Gadu” wydany w roku 2009. Autor analizy zapewne nie przewidział, że „nowy mechanizm” będzie kiedyś zastąpiony „jeszcze nowszym mechanizmem”. Trzeba je numerować albo nadawać wersjom imiona.
Przypomnijmy fragment raportu NIK: „SLPS nieprawidłowo liczył sędziom obciążenia, co przekładało się negatywnie na równomierność przydziału spraw. W grudniu 2018 r. Dyrektor DKO opracował koncepcję naprawy danych w bazie SLPS. Generalne przeliczenie wartości zgodne z tą koncepcją odbyło się 15 lutego 2019 r. Operacja ta okazała się skuteczna tylko częściowo i jednocześnie sama była przyczyną kolejnych nieprawidłowości w bazie danych. Dlatego w marcu 2019 r. wprowadzono do SLPS możliwość zerowania obciążeń, a w lipcu udostępniono użytkownikom arkusz Excel służący do ręcznego przeliczenia danych i rozpoczęcia przydziału od nowa […] planowane jest uruchomienie odpowiedniego mechanizmu raportującego, który z poziomu centralnej bazy wykrywałby nietypowe różnice w obciążeniach sędziów”.
R30, strona 7 – „Tworzona jest lista zawierająca wszystkich sędziów z danego wydziału orzekających w danej kategorii, z wyłączeniem referatów zbiorczych”. Jeśli referat może być zbiorczy, to nie ma znaku równości między referatem a sędzią. Modelując system należałoby zastosować agregację (sędzia ma referat) albo dziedziczenie (referat sędziego jako specjalizacja bardziej ogólnego referatu).
Jak wspominałem – powyższe zastrzeżenia to tylko moje opinie, jestem jednak przekonany, że doświadczony zespół dążyłby do eliminacji opisanych pułapek. Usterki w architekturze odbijają się czkawką przez długie lata, jakiekolwiek początkowe oszczędności są niczym wobec kosztów ich naprawy po latach.
Co realnie zyskaliśmy otrzymując tzw. Algorytm SLPS?
Bardzo niewiele. Nie jesteśmy w stanie potwierdzić zarówno prawidłowości pojedynczych losowań jak i spójności danych SLPS w dłuższym okresie. Nie dowiedzieliśmy się niczego o źródłach losowości, logowaniu zdarzeń ani wiarygodności logów. Nie mamy też żadnej możliwości weryfikacji poprawności implementacji – tu potrzebny byłby dostęp do kodu źródłowego, o co nadal walczy Sieć Obywatelska Watchdog Polska. Na dobrą sprawę dowiedzieliśmy się jedynie, że jakaś dokumentacja projektowa rzeczywiście powstała a jej cechy pasują do… problemów z SLPS opisywanych w prasie.
Wciąż jednak mamy do czynienia z całkowitym brakiem przejrzystości SLPS. Gdyby tak działało Lotto, nie tylko zabrakłoby publicznych losowań na antenie TV, ale w ogóle nie mielibyśmy informacji o wylosowanych numerach. Gracze musieliby przyjąć na wiarę, że ktoś uruchamia maszynę, że skaczą w niej jakieś kulki a namalowane na nich liczby służą do wyznaczenia zwycięzców. Ciekawe, ile osób wierzyłoby wówczas w uczciwość losowań…
A może zrezygnować z generatora liczb losowych?
Aby nie było, że tylko marudzę – oto pomysł, jak przeprowadzić losowy przydział składów sędziowskich bez uciekania się do generatora liczb losowych, którego skuteczny audyt może być niemożliwy. Z góry przepraszam za hermetyczność tego rozdziału.
Główna idea – użycie skrótu kryptograficznego z wartości, które znane są w chwili wpływu sprawy, np. data i godzina, powód i pozwany. Ewentualne manipulacje z godziną czy kolejnością rejestracji nie mają znaczenia. Powstały skrót (hash) byłby natychmiast publikowany w portalu sądowym wraz z informacją o jego numerze sekwencyjnym (SLPS jest jeden na cały kraj, więc może kolejno numerować rejestrowane sprawy). Skrót sam z siebie nie zdradza niczego, natomiast stanowi stanowi swoiste znakowanie czasem i gwarancję wczesnego utworzenia losowości powiązanej niezaprzeczalnie z daną sprawą.
Potem obowiązkowo czekamy np. tydzień, aby pula sędziów do losowania stała się nieprzewidywalna (po drodze będzie wiele innych losowań, które wpłyną na dobór i kolejność sędziów w puli). W każdej sesji przydziału bierzemy sprawy nie nowsze niż tydzień, obrabiamy je obowiązkowo w kolejności rejestracji; decyduje numer sekwencyjny bazy danych SLPS nadany tydzień wcześniej. W każdej sprawie używamy ustalonego wcześniej skrótu do wyznaczenia n-tego sędziego z puli.
Manipulowanie wynikiem byłoby wciąż możliwe, gdyby w ciągu owego tygodnia do danego wydziału wpłynęło na tyle mało spraw, by przyszła pula sędziów pozostała przewidywalna. Tę usterkę da się załatać – skoro SLPS jest jeden na cały kraj i przeprowadza losowania sekwencyjnie, to możemy „dohaszować” skrót sprawy X wynikiem przydziału sprawy X-1, ów wynik będzie znany dopiero ułamek sekundy przed przydziałem składu dla sprawy X.
Opisany pomysł nie zapobiegnie wszystkim możliwym manipulacjom (np. ręcznemu usuwaniu sędziów z puli) ale sposób uzyskania i użycia losowości nie wymagałby wiary w uczciwość i prawidłowość użycia sprzętowego generatora. Gdyby dodać do tego jawność protokołów przydziału i uwzględnienie na protokołach powodów wykluczeń sędziów, mielibyśmy coś na kształt audytowalnego SLPS.
Dostrzegacie inne słabości pomysłu, których ja nie widzę? Dajcie znać w komentarzach.
Wcześniejsze teksty o Systemie Losowego Przydziału Spraw
[2020-12-14] System Pseudolosowego Przydziału Spraw – opisałem problemy z SLPS i objaśniłem, dlaczego celowe błędy wpływające na działanie generatora liczb pseudolosowych mogą wyglądać tak, jak staranny kod niekompetentnego programisty
[2021-05-02] NIK o SLPS: Nie osiągnięto celów całego przedsięwzięcia – zestaw cytatów na temat SLPS z raportu Najwyższej Izby Kontroli
[2021-07-30] O algorytmach dla prawników – objaśniam krok po kroku, czym algorytm różni się od programu komputerowego i dlaczego bez dostępu do kodu źródłowego nie będziemy wiedzieć, czy pozornie poprawny program nie zawiera błędów
[2021-10-03] Poznaliśmy algorytm losowania SLPS czyli… co dokładnie? – oceniam, jaką wartość ma dokument udostępniony przez Ministerstwo Sprawiedliwości
[2022-01-14] Przejrzystość SLPS – duży krok do przodu – na stronach Portalu Sądowego pojawiła się wyszukiwarka raportów z losowań – niestety zabezpieczona mechanizmem reCAPTCHA
[od kwietnia 2024] Monitor SLPS – wpisy w serwisie slps.pl
[2025-01-09] Realny i najwyższy stopień zagrożenia – opinia do wyroku WSA oddalającego skargę na odmowę udostępnienia kodu źródłowego SLPS
O autorze: zawodowy programista od 2003 roku, pasjonat bezpieczeństwa informatycznego. Rozwijał systemy finansowe dla NBP, tworzył i weryfikował zabezpieczenia bankowych aplikacji mobilnych, brał udział w pracach nad grą Angry Birds i wyszukiwarką internetową Microsoft Bing.

21 odpowiedzi na “Poznaliśmy algorytm losowania SLPS czyli… co dokładnie?”
A gdyby tak:
– lista sędziów możliwych do przypisania w danej sprawie jest przygotowywana w wydziale. Kolejność sędziów jest losowa i początkowo utajniona
– pozycja z tej listy jest losowana na serwerze centralnym. Po jej wylosowaniu ujawniana jest kolejność sędziów wylosowana lokalnie w wydziale
– po tym tworzone są kolejne listy sędziów do kolejnych spraw, z uwzględnieniem zmienionego obłożenia sędziów pracą
Opcjonalnie można generować listy spraw, które może przyjąć sędzia i losować sprawę a nie sędziego. Dzięki temu trudniej będzie wpływać na wynik, bo losujemy jedną z np 20 spraw a nie jednego z 5 sędziów.
W ten sposób, żadna z dwóch biorących udział w losowaniu stron nie ma wpływu na całość losowania
Prezes sądu jest podległy ministrowi, więc de facto minister miałby kontrolę nad całością procesu
W ten sposób można skasować każde rozwiązanie techniczne. Bo nawet przy najlepszym systemie, administrator podlega ministrowi.
Uczciwość losowania w Twojej propozycji zależy od tego, czy operatorzy dwóch systemów nie będą umówieni. Jeśli są, nie wykryjesz ustawionego losowania.
„Losowanie sędziego referenta dla sprawy odbywa przy wykorzystaniu generatora sprzętowego liczb” – już samo to zdanie otwiera drzwi do króliczej nory. Tam nie ma nawet słowa „losowych”. Urządzenie sprzętowe generujące zawsze liczbę 1 (np. moneta z dwiema reszkami) jest sprzętowym generatorem. Kostka sześciościenna z liczbą 1 na 5 ścianach także. Kolejna sprawa – czy aby na pewno generator jest sprzętowy? Nie jest podany opis/model generatora, opis jest jaki jest więc może „sprzętowym” generatorem jest po prostu komputer? A jeśli tak, czy generator liczb naprawdę jest losowy, czy pseudolosowy? Last but not least: jeśli jest pseudolosowy, to jak ustalany jest seed? Pewnie w związku z ilością innych zmiennych nie ma to większego praktycznego znaczenia, ale jakiż piękny materiał do rozważań.
Sprzętowy generator liczb losowych spełniający stosowną normę FIPS byłby całkiem ok i w zasadzie audytowalny, ale żeby takie rzeczy wpisać to reszta dokumentacji by też musiała być na innym poziomie 😉
Ale to nie jest ani symulator z zakresu fizyki kwantowej, ani generator haseł do rezerwy federalnej czy arsenału nuklearnego. Nie ma po co wydawać na taki sprzęt z naszych podatków (i go integrować).
Zupełnie wystarczająca wydaje się funkcja „random” – jedna linijka kodu – z której każdy każdy zwykły program. SLPS ma rozlosować codziennie kilkanaście tysięcy spraw sądowych, pomiędzy kilkadziesiąt tysięcy sędziów i referendarzy. Tylko tyle.
Moja propozycja wymaga kilku założeń:
Sędzia nie powinien mieć przypisanych więcej niż MAX spraw.
Ma to zabezpieczyć przed rozładowaniem całej kolejki na jednej osobie gdy pozostali są np na urlopie.
Sędzia jest wyłączony z losowania gdy wymaga tego prawo lub gdy ma MAX aktualnych spraw.
Sędzie wie do czego służy funkcja skrótu i jak ten skrót wyznaczyć.
Lista spraw jest posortowana po dacie, a w ramach daty po numerze sprawy.
1. Tworzymy listę sędziów z liczbą spraw mniejszą niż MAX i nie wyłączonych z udziału w przydzielaniu,
Oraz drugą listę sędziów wyłączonych z podanym powodem wyłączenia.
2. Dla każdego sedziego z pierwszej listy tworzymy zapis:
[Identyfikator_Sędziego]:[Numer ostatnio zamkniętej sprawy]
Np: Jan_Kowalski:IV_Ka_1210/19
Wyliczamy md5 i otrzymujemy: ef415f1841d34dca16ffc7ccff50748e
Można to zweryfikować przykładowo na:
http://www.md5online.pl/
https://www.md5online.org/md5-encrypt.html
3. Sortujemy sędziów z pierwszej list po wartości md5.
Mamy więc dwa stosy. Stos spraw i stos sędziów z pierwszej listy, posortowanych po md5.
4. Zdejmujemy pierwszą sprawę i przydzielamy ją pierwszemu na liście sędziemu. Następną sprawę przydzielamy następnemu sędziemu.
Przez listę sędziów przechodzimy wielokrotnie za każdym razem usuwając sędziów którzy osiągneli MAX.
Ponieważ każdy sędzia sam decyduje kiedy i jaką sprawę zamyka więc mamy listę niezależnych od siebie sum md5.
5. Losowanie kończy się gdy kończą się sprawy do przypisania lub zabraknie sędziów na liście.
6. Wysyłany jest emailem raport zawierający:
– posortowaną listę początkową spraw z numerem i datą,
– posortowaną po md5 początkową listę sędziów z identyfikatorem, numerem zamkniętej sprawy, ilością przydzielonych spraw i wyliczonym md5,
– listę sędziów wyłączonych z informacją o powodzie wyłączenia.
– listę komu i jaką sprawę przydzielono w kolejnych krokach z punktu 5 (czyli właściwie log z przydzielania zadań).
Ps. Dobry blog.
Całe formatowanie poszło w piach.
Takie kwestie:
– jakkolwiek przeprowadzony „po ciemku” to POZNAJEMY wynik losowania. „Raport z losowania” jest wydrukowany w aktach każdej ze spraw (z publicznym dostępem stron, a w niektórych przypadkach też np. dziennikarzy).
– lista sędziów pominiętych w losowaniu jest prosta do ustalenia. Lista wszystkich sędziów danego wydziału jest publicznie dostępna – można porównać z Raportem z losowania i już widać którzy sędziowie zostali pominięci. Oczywiście nadal brak jest ujawnienia przyczyny pominięcia w losowaniu.
– w praktyce wydziały w Sądach są raczej małe (max. kilku sędziów, a nie 13, jak w przykładzie).
– sprawa nie może czekać tydzień na losowanie. Czekanie do poranka następnego dnia roboczego już było krytykowane.
– przykład z drobnym błędem metody „mod” dla pierwszych pozycji na liście, z kostką 6-ścienną – obrazowy, ale nieco nietrafiony. Jak widać na przykładzie system losuje liczbę 10-cyfrową, a więc „pokrzywdzenie” pierwszego na liście, choć występuje, to jest liczone w bardzo dalekich ułamkach.
ps. z tym mieszaniem listy rankingowej („Pozycji”) – to rzeczywiście jakieś kuriozum. Bez tego system byłby po wielokroć bardziej przejrzysty.
ps2. pomysł z hash’em zamiast liczby losowej – fajny, ale ma małą wadę: częste drobne pomyłki we wprowadzaniu nazw stron do komputera. Do tego możliwość skracania (np. „sp. z o.o.” zamiast „spółka z ograniczoną odpowiedzialnością”). No i teraz co… losowanie nieważne bo był błąd przy wpisywaniu ? trzeba powtarzać całą sprawę sądową bo była prowadzona przez nie tego sędziego ? „Biuro podawcze” winne temu, że wylosowano komuś „ostrego” sędziego, bo skrócili mu nazwę przy wpisywaniu ?
Niewiele z tego rozumiem, przyznaję się bez bicia. Nadal jednak broniłbym starego systemu:
1) zdefiniowany przydział numerowy (ostatnia cyfra lub dwie w dużych wydziałach), tj. Sędzia X: 1,2,3, Sędzia Y:4,5,6,7, Sędzia Z:8,9,0,
2) sprawy wpisywane do repertorium/systemu alfabetycznie każdego dnia, z kontynuacją numeracji z dnia poprzedniego, czyli wczoraj ostatnia sprawa zarejestrowana była pod sygn. II K 543/21, a więc sprawa Józefa Adamskiego dostanie nr II K 544/21, Zenona Bednarskiego II K 545/21 itd.
3) efekty:
a) system komputerowy wykluczy możliwość zarejestrowania przez panią kierowniczkę Ziutkę sprawy Bednarskiego przed Adamskim,
b) w dowolnej chwili można sprawdzić przydział numerowy z dowolnego dnia i co za tym idzie:
c) czy sprawa trafiła do kolejnego – właściwego sędziego.
4. W przypadku sędziego wyłączonego stosowny dokument i tak musi znaleźć się w aktach (oświadczenie o wyłączeniu z mocy prawa albo postanowienie o wyłączeniu na wniosek)
5) system tańszy i bardziej przejrzysty… no i losowy – nie można przewidzieć ile dokładnie spraw wpłynie danego dnia, czyli trafienie do wybranego sędziego jest mało prawdopodobne.
Skutki SLPS, które odczułem na własnej skórze: w pierwszym roku blisko 67 spraw więcej niż wynika z podziału czynności, w drugim roku 18 spraw więcej, w trzecim roku 1 sprawa więcej, w tym roku już 28 spraw więcej i wciąż na mnie losuje równo z kolegami. dodam, że średnia miesięczna „załatwialność” w kraju w tego typu sprawach to około 35.
mrdezo, czy zawartość raportu nie wyjaśnia z czego wynika nadmiar przydzielanych spraw?
Niestety, nie. Ministerstwo obiecało wyjaśnienie i poprawkę systemu ze skutkiem opisanym.
Doświadczenie wymieniane z innymi sądami wskazuje, że opłaca się mieć dużo nieobecności różnego rodzaju (urlop, szkolenie, choroba) zwłaszcza w kluczowych momentach (półrocze, koniec kwartału) i wówczas obciążenie jest mniejsze niż wynika to z podziału czynności, czego w ogóle już nie rozumiem, bo system miał temu przeciwdziałać.
Ale to już nie jest kwestia „informatyczna/programistyczna”, tylko określenie zasad ustalania „współczynnika obciążenia sprawami”. Te zasady zostały przez kogoś ustalone i narzucone informatykowi „z góry”.
To, jak i kiedy jest obliczany ten „współczynnik obciążania” – to całkiem inna kwestia.
Ps. Treść przykładowego „Raportu z losowania” sugeruje, że ten współczynnik jest „aktualizowany” po każdym pozytywnym dla danego Sędziego losowaniu. Jeśli są jakieś korekty bazy tego współczynnika, na koniec roku/półrocza/kwartału – to raczej robione „ręcznie”. Ale to tylko spekulacja.
Szanowny Panie.
Z artykułu wynika mniej-więcej, że:
(1) przedstawiona dokumentacja SLPS jest bardzo słaba – zawiera „dziury” jak np. zagadkowy mechanizm „mieszania pozycji”.
(2) wskazane „dziury”, zależnie od tego jak zostały rozwiązane, rodzą ryzyko „manipulacji”, czy to ze strony wydziału, czy Ministerstwa.
NIE MNIEJ:
Przyjmując, że „dziury” są tylko „dziurami” w dokumentacji, a faktycznie kod programu jako-tako rozwiązuje potencjalne zagrożenia wynikające z tych „dziur”, albo też nie ma w Pańskiej sprawie woli manipulacji akurat Pańskim przydziałem ze strony wydziału czy Ministerstwa – Pański większy wpływ niż w latach poprzednich wynika tylko i wyłącznie z… mniejszego „obciążenia”.
Dziękuję za tę wypowiedź, pozwoliła mi ustalić clue sprawy. Problem polega tylko na tym, że mniejsze obciążenie nie wynika z podziału czynności, ale… mniejszych zaległości. Słowem, kto pracuje szybciej/ wydajniej niż inni dostaje więcej spraw.
W założeniu stagnacja w orzekaniu miała świadczyć o przydziale trudniejszych spraw. W rzeczywistości wyszło po sądowemu – jeśli się wyrabiasz, to nie dlatego, że jesteś dobry i się starasz, tylko za mało ci dołożyliśmy.
Life…
@mrdezo
Jadnak system nie uwzględnia aktualnego obciążania w sensie że daje najwięcej spraw tym co mają ich najmniej niezałatwionych (najwięcej załatwili). U mnie w wydziale (3 osobowym) najwięcej spraw dostaje osoba która ma najwięcej sprawy (ma coś na pieńku z tym komputerem w gdańsku co to losuje 😉
Ja to zrobiłbym inaczej by – nie było skoków obciążenia. Dlaczego losować sędziów zamiast sprawy ?
Najpierw ustalamy sędziego który winien dostać sprawę w danej kategorii, uwzględniając sprawy które dostał już wcześniej a potem dopiero losujemy mu sprawę z puli dostępnych spraw w danej kategorii.
I mamy zarówno losowość (choć nie wiem czy to wartość) jak i równe obciążenie.
Tak szczerze: tylko dzięki uzyskaniu tego przykładowego „Raportu z losowania”, dzięki uprzejmości czytelnika – ten dokument z ministerstwa jest jako-tako zjadliwy.
Na tle Twojego artykułu poniższy staje się zabawny.
https://www.prawo.pl/prawnicy-sady/sztuczna-inteligencja-w-sadzie-trwaja-prace-nad-rozwiazaniami,418130.html
Pytanie. Czy my jesteśmy pionierami, czy może są już na świecie lub chociażby w Europie takie systemy wdrożone na których można by się wzorować?
„Spójrzcie jeszcze raz na przykładowy protokół z poprzedniego obrazka. Zauważcie, że czteroosobowa pula sędziów do losowania ma zmienione liczby porządkowe (kolumna „Pozycja”). Pierwotnie numerom 1-2-3-4 odpowiadało rosnące obciążenie sprzed losowania, jednak zgodnie z regułą R19 (str. 5) numeracja pozycji została pomieszana, wyszło 4-1-3-2.
Jeśli dobrze rozumiem regułę, każdemu z czterech sędziów z puli przydzielono osobną wartość losową i posortowano według nich liczby porządkowe, bez przestawiania wierszy. Ważne: te wartości nie są nigdzie rejestrowane, nie ma tu nawet pozorów przejrzystości. Następnie w kroku R22 obieramy jeszcze jedną wartość losową – to ona trafia na protokół oraz wyznacza (operacja modulo) sędziego do sprawy.
Z punktu widzenia matematyki nie ma to żadnego sensu. ” – no wiec ma, ten shuffling jest wlasnie po to, zeby modulo mialo mniej wiecej rowne szanse – moim zdaniem. Co i tak jest bez sensu i to taka patchworkowa robota, zeby przypudrowac to, co pod spodem.